Redis:普通锁和分布式锁实现原理
Redis:普通锁和分布式锁实现原理
一、Redis单服务实例实现锁
1、实现锁有以下要求:
(1)唯一性:一把锁只能存在一个实例;
(2)无死锁:client操作超时自动释放;
(3)安全性:只对当前client可操作;
唯一性:同一把锁有切只能有一个实例;假如A、B两个client同时有Lock这把锁,A和B都有权限同时操作同一数据,那“锁”也就没有了意义,锁存在的意义就是避免同步操作;
无死锁:client-A在获取Lock这把锁之后,client-A意外退出(网络超时、程序卡死等),在退出之前没有对锁释放(可能都来不及释放),这个时候Lock这把锁就长期持有,在client-A重新登录之后,如果无法获取“Lock”都可能无法释放锁,Redis通过Lock的过期时间控制锁的自动释放;
安全性:如果client-A在获取Lock锁之后,client-B也可以对Lock进行操作的话,最后判定Lock锁解锁失败(redis在删除一个不存在的key时,会返回失败,如下代码所示);
$> del UserInfo{112001}
(integer) 0
2、单例锁实现
基于以上三个特性,Redis通过SET命令实现锁的创建和删除,如下示例:
SET resource_name my_random_value NX PX 30000
resource_name:锁的名字,在Redis中做key;
my_random_value:锁的值,如果不要求安全性时,可以不操作该值,只需要设置上值即可;如果需要保证安全性,此值在所有客户端和所有锁定请求中必须唯一,可以通过秒级时间戳来保证值得唯一,或者连接CLIENT ID。
NX:SET命令的参数,如果Key存在,则SET失败,保证锁的唯一性;
PX:SET命令的参数,设置成功之后,在30000毫秒内将过期,保证无死锁;
为什么可以通过VALUE随机值来保证安全性?
在释放锁时,当且仅当Lock存在且存储在Lock上的VALUE恰好是我期望的值时,才能释放该Lock;
该方案可以在逻辑代码中实现,也可以通过Lua脚本实现。
安全释放锁的Lua脚本:
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
以上即是Redis单例实现锁,单例锁对安全性要求不高的话足够使用(Redis服务器宕机对锁的影响不大,只需要丢弃本次操作或者重新获取即可),但是要求锁的安全性必须很高,那就需要使用分布式锁了。
现在我们有了获取和释放锁的好方法。该方案基于由一个始终可用的单个实例组成的非分布式系统的推理是安全的。让我们将概念扩展到没有此类保证的分布式系统。
二、Redis分布式锁
1、为什么基于故障转移还不够?
使用Redis锁定资源的最简单方法是在实例中创建Lock。Lock通常使用Redis过期功能在有限的生存时间内创建,因此即便client失连之后,通过过期时间保证Lock最终被释放。当client需要主动释放资源时,将Lock删除即可。
从表面上看,这个设计很完美,但是存在一个问题:单点故障(single point of failure)
如果Redis主服务器宕机怎么办?有人肯定能想到Redis集群,为主服务器添加Slave,即便Master宕机,Slave可以代替Master,如果还担心一个Slave不够可以多加几个Slave,然后通过ZK管理集群;然而,这种方案是不行的,因为我们要保证锁的唯一性和安全性;Redis的主从复制是异步的,client-A首先在Master获取Lock,在Master将Lock数据复制到Slave之前,Master宕机,此时Slave中并没有Lock的数据,在Slave中选举出Master之后,client-B又尝试在新Master中获取Lock,此时client-A已经对资源锁定,这中情况就违反了锁的唯一性和安全性。
2、基于Redlock算法的Redis分布式锁
假设我们有N个Redis Master节点,这些主节点完全独立,我们不使用副本或者其他类似Slave的隐式协调系统。前面Redis锁的单例实现即时Redlock的核心,不过我们将通过设置N为5举例说明分布式的Redlock算法解决的问题。不管在虚拟机还是物理机上都可以部署,我们的目的只是为了实现独立的单点故障。
客户端需要执行以下步骤:
(1)获取当前时间的毫秒时间戳。
(2)挨个在所有Master节点中获取锁,在所有节点中设置锁之后,客户端保存一个比“总锁定时间”稍微小一点的超时时间(例如自动释放时间为10秒,客户端的超时时间可以设置为5~50ms之间)。这样可以防止客户端长时间与故障节点通信阻塞,如果一个实例不可用我们应该尽快与下一个实例通讯。
(3)根据当前时间与步骤(1)中获得的时间取差,就是客户端在获取锁过程中所消耗的时间,当且仅当客户端在大多数实例中(大于等于3个,即N/2 + 1)获得了锁,并且获得锁所消耗的时间小于“锁的有效时间(锁在Redis中自动释放的时间)”,则认为获取锁成功。
(4)如果成功获取了锁,则将初始有效时间减去“经过时间” 视为有效持有锁的时间。
(5)如果获取锁失败,则客户端应尝试解锁所有节点上的Lock,即时客户端没有在该节点上创建Lock实例;安全性要求client-A创建的Lock只能由client-A释放,否则锁将在Redis节点上存在很长时间,直到自动释放。
有一点值得强调:当客户端获取锁失败时,应尽快释放那些已经获取Lock的节点。
举例:还是有5个节点相互独立,client-A获取了1和2两个节点的Lock实例,client-B获取了3、4和5三个节点的Lock实例,从N/2+1原则上来说,client-B获取了Lock锁,那么client-A需要尽快释放1和2两个节点上的Lock实例,如果client-A不主动释放就只能等Lock在1、2上自动过期,假如过期时间为3秒,那么在3秒内1、2节点将不再接收Lock的创建(SET NX原则);那么在client-B释放锁之后,在释放到过期这段时间内将很有可能不再支持Lock锁的创建(很有可能client-B和client-C在3、4、5上获取Lock实例,这个时候很难满足N/2+1原则,除非一个客户端全部获取3、4、5节点上的Lock实例)。
失败重试:
当client无法获取Lock锁时,它应在随机延迟后重试,避免多个client出现同步问题。同样,客户端在大多数Redis实例中尝试获取锁定的速度越快,出现裂脑情况的窗口就越小,因此理想情况下,客户端应尝试使用多路复用同时将SET命令发送到N个实例。
性能,崩溃恢复和fsync
使用Redis作为Lock服务器的许多用户在"获取/释放锁"的延迟和每秒可能执行的"获取/释放操"作数方面都需要高性能。为了满足此需求,与N个Redis服务器进行通信以减少延迟的策略肯定是多路复用(或自己实现多路复用,即将套接字置于非阻塞模式,假设客户端和每个实例之间的RTT相似,在发送所有命令之后,并读取所有命令),此时新版本的Redis已经支持多路复用。
除了性能之外,我们要针对崩溃恢复系统模型,还需要考虑持久性。
举例问题:假设我们完全没有持久性地配置Redis。客户端在5个实例中的3个节点中获取了锁。这三个节点中的其中一个节点重新启动,此时,我们又可以为同一资源锁定3个节点,而另一个客户端可以再次锁定它,这违反了锁的唯一性和安全性。
如果启用AOF持久性,则情况将会大大改善。例如,我们可以通过SHUTDOWN命令关闭服务器然后重新启动它来实现升级服务器。因为Redis过期是从语义上实现的,实际上在服务器关闭之后时间仍在流逝,所以只要是正常关闭我们的所有请求都是可以安全转移的。但是,停电呢?如果默认情况下将Redis配置为每秒在磁盘上进行fsync(关于fsync详细讲解请参考Redis持久化),则重启后可能会丢失1秒的数据。从理论上讲,如果要在遇到任何类型的实例重新启动时都保证锁定安全,则需要在持久性设置中始终启用fsync = always。不过这将完全破坏Redis的性能,使其达到传统上以安全方式实现分布式锁的CP系统的水平。
但是,情况总比乍看之下要好。只要节点在崩溃后重新启动,它就不再参与任何当前活动的Lock(将该节点在锁的持有计算上排除),算法安全性就得以保留;即在所有可用节点上进行锁的实例获取,正在重启的节点不参与计算。为了保证这一点,我们需要在崩溃节点上的所有锁的最大的过期时间还要稍微大一点时间的窗口期,该崩溃节点不可用,为了保证在该节点上的锁在其他节点上已经失效或者自动过期。如下图所示:
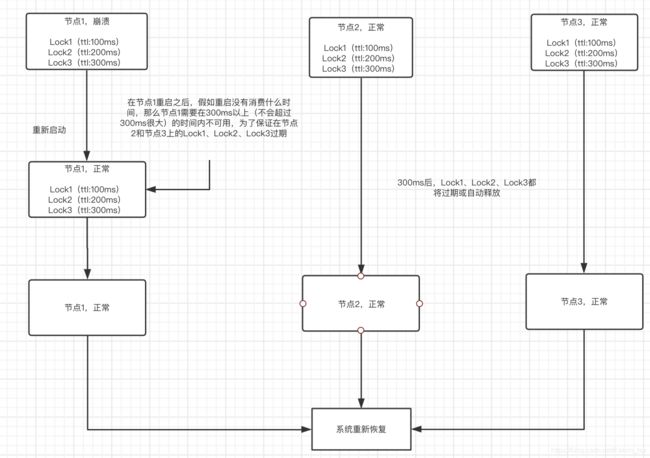
即使没有任何可用的Redis持久性,使用延迟重启也基本上可以实现安全性,但是请注意,这可能会导致可用性下降。例如,如果大多数实例崩溃,则系统将对TTL全局不可用(此处,全局意味着在此期间根本没有资源可锁定)。
如果想对锁进行扩展,那么在获取锁失败时,重新获取锁的等待"TIMEOUT"上可以做下文章,只是提供一下思路。
推荐一些已经实现分布式锁的链接,可以用作参考:
Redlock-rb:Ruby实现
Redlock-py:Python实现
Aioredlock:异步Python实现
Redlock-php:PHP实现
Redsync:Go实现
Redlock-cpp:C++实现
Redlock-cs:C#/.NET实现
Redisson:Java实现
更多可参考Redis官方文档;
参考:Redis官方文档