JDK源码分析------Vector
概述
正如我们大家都知道的样子,在集合框架中ArrayList和LinkedList都是线程不安全的。但是有没有存在线程安全的类呢?答案必然是肯定的。这里就解释一下Vector这个类。可能有人会提到java.util.concurrent.CopyOnWriteArrayList这个东西,由于其实现机制和Vector是不同的,这里不做如何讨论。当分析到CopyOnWriteArrayList这个类的时候我会详细介绍一下这个东东。
首先我们来看一下如下所示的代码
public static void main(String[] args) throws InterruptedException {
Vector<Integer> vector = new Vector<>();
ThreadPoolExecutor executor = new ThreadPoolExecutor(10,20,10L,TimeUnit.SECONDS,
new ArrayBlockingQueue<Runnable>(100));
for (int i=0; i<20; i++) {
int temp = i;
executor.execute(new Runnable() {
@Override
public void run() {
vector.add(temp);
}
});
}
// 这里使用sleep就是让main线程阻塞,让线程池中的vector调用完成。
Thread.sleep(2000);
System.out.println(vector.toString());
}

通过这个小例子,我们可以看出Vector是线程安全的。现在让我们通过源码,认真分析一波内部具体是如何实现的。
继承关系
public class Vector<E>
extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
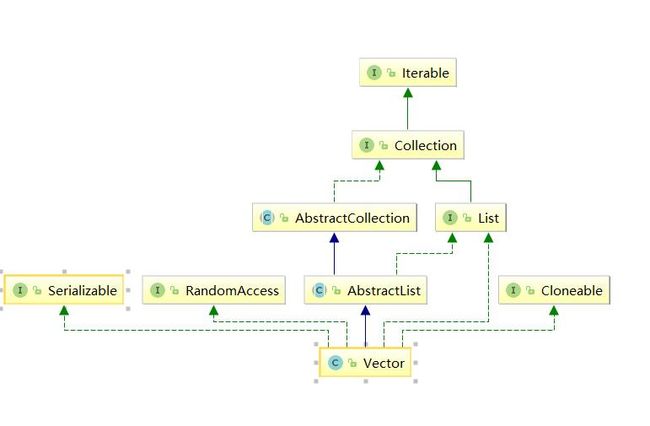
我们可以看到,Vector继承了AbstractList,实现了List接口。这样实现了集合类的接口。
实现了RandomAccess,可以通过迭代器快速访问。实现了Cloneable接口。同时也实现了Serializable接口,可以进行对象的序列化和反序列化。
属性
//vector底层是用数组来是实现的。
protected Object[] elementData;
//保存元素个数
protected int elementCount;
//每次扩容的大小,ArrayList是原来数组大小的1.5倍,Vector如果不指定,
//则扩容大小和扩容前数组的大小一致,即扩容到原来数组大小的两倍。
protected int capacityIncrement;
同时再Vector中还有三个内部类,大致如下:
//这里是Java中的迭代器
private class Itr implements Iterator<E> ;
static final class VectorSpliterator<E> implements Spliterator<E>
final class ListItr extends Itr implements ListIterator<E>
Iterator和ListIterator相同点和不同点
相同点:
都是迭代器,当需要对集合中元素进行遍历不需要干涉其遍历过程时,这两种迭代器都可以使用。
不同点:
1.使用范围不同,Iterator可以应用于所有的集合,Set、List和Map和这些集合的子类型。而ListIterator只能用于List及其子类型。
2.ListIterator有add方法,可以向List中添加对象,而Iterator不能。
3.ListIterator和Iterator都有hasNext()和next()方法,可以实现顺序向后遍历,但是ListIterator有hasPrevious()和previous()方法,可以实现逆向(顺序向前)遍历。Iterator不可以。
4.ListIterator可以定位当前索引的位置,nextIndex()和previousIndex()可以实现。Iterator没有此功能。
5.都可实现删除操作,但是ListIterator可以实现对象的修改,set()方法可以实现。Iterator仅能遍历,不能修改。
下面我们来看一个有趣的例子:
public static void main(String[] args) throws InterruptedException {
Vector<Integer> vector = new Vector<>();
for (int i=0; i<10; i++) {
vector.add(i);
}
Iterator<Integer> iterator = vector.iterator();
while (iterator.hasNext()) {
Integer next = iterator.next();
System.out.print(next+" ");
}
System.out.println();
ListIterator<Integer> integerListIterator = vector.listIterator();
while (integerListIterator.hasNext()) {
Integer next = integerListIterator.next();
System.out.print(next+" ");
}
System.out.println();
while (integerListIterator.hasPrevious()) {
Integer previous = integerListIterator.previous();
System.out.print(previous+" ");
}
System.out.println();
System.out.println(vector.toString());
}
这里是两种遍历方式,同时还包含从前遍历和从后遍历两种方式。

这里我注释掉了使用listIterator的从前遍历。结果会是如何呢?
public static void main(String[] args) throws InterruptedException {
Vector<Integer> vector = new Vector<>();
for (int i=0; i<10; i++) {
vector.add(i);
}
Iterator<Integer> iterator = vector.iterator();
while (iterator.hasNext()) {
Integer next = iterator.next();
System.out.print(next+" ");
}
System.out.println();
ListIterator<Integer> integerListIterator = vector.listIterator();
/*while (integerListIterator.hasNext()) {
Integer next = integerListIterator.next();
System.out.print(next+" ");
}
System.out.println();*/
while (integerListIterator.hasPrevious()) {
Integer previous = integerListIterator.previous();
System.out.print(previous+" ");
}
System.out.println();
System.out.println(vector.toString());
}

我们发现从后遍历的结果也没有了,为何会出现这样的结果呢?我们可以从源码中可以得知一二。
public boolean hasPrevious() {
return cursor != 0;
}
public E previous() {
synchronized (Vector.this) {
checkForComodification();
int i = cursor - 1;
if (i < 0)
throw new NoSuchElementException();
cursor = i;
return elementData(lastRet = i);
}
}
public synchronized ListIterator<E> listIterator() {
return new ListItr(0);
}
在进行从后往前遍历的时候,可以看到是根据cursor这个属性定位元素的索引值。但是不巧的是初始化的时候这个cursor这个值是为0。
public boolean hasNext() {
// Racy but within spec, since modifications are checked
// within or after synchronization in next/previous
return cursor != elementCount;
}
public E next() {
synchronized (Vector.this) {
checkForComodification();
int i = cursor;
if (i >= elementCount)
throw new NoSuchElementException();
cursor = i + 1;
return elementData(lastRet = i);
}
}
只有当next()方法执行完毕,才会进行cursor游标加1的操作 。hasNext和next方法其实来自于 Iterator方法的实现。然后ListItr继承了Itr,对它进行了扩展操作。所以在使用ListIterator从后遍历之前首先要进行从前往后遍历。才能得到真正的结果。
我们看到还有一个属性是Spliterator。这个是JDK1.8之后才有的。
Spliterator是一个可分割迭代器(splitable iterator),可以和iterator顺序遍历迭代器一起看。jdk1.8发布后,对于并行处理的能力大大增强,Spliterator就是为了并行遍历元素而设计的一个迭代器,jdk1.8中的集合框架中的数据结构都默认实现了spliterator,后面我们也会结合ArrayList中的spliterator()一起解析。
构造函数
public Vector();
public Vector(int initialCapacity);
// 上面两个方法其实都是在调用这个方法,其实也没有做什么
// 对elementData和capacityIncrement进行初始化。
public Vector(int initialCapacity, int capacityIncrement) {
super();
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
this.elementData = new Object[initialCapacity];
this.capacityIncrement = capacityIncrement;
}
// 如果参数是一个集合,那么先将这个集合转化为数组,然后通过数组的copy实现。
public Vector(Collection<? extends E> c) {
elementData = c.toArray();
elementCount = elementData.length;
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, elementCount, Object[].class);
}
add
//当向一个Vector加入一个元素的时候,其实就是做了modCount加一,这个属性记载了底层数组被
//操纵了多少次。然后看是否需要扩容,如果需要扩容,就扩容,实现数组的copy,然后在数组末尾加入这个元素。
// 需要注意的地方时我们可以看到在add方法上加入了synchronized关键字。使用这个可以保持在多线程环境下是线
//程安全的,但是这个不是最优的,因为是在add方法上加锁,锁的粒度太粗,在add的时候其实也是个串行操作。之后会讲一个
//其他的线程安全的类。
public synchronized boolean add(E e) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = e;
return true;
}
private void ensureCapacityHelper(int minCapacity) {
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
//扩容如果指定扩容大小,则使用扩容大小,否则会扩容为原来数组的两倍。
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}
其他的add操作也是一样的,不会是操作的位置的不同,比如如果指定索引,会在索引之后的元素统一往后移动一位。如果是一个集合,那么会讲这个位置之后的元素统一移动集合长度个单位。然后把这个集合放在这个位置。都比较简单。
contains
public boolean contains(Object o) {
return indexOf(o, 0) >= 0;
}
public synchronized int indexOf(Object o, int index) {
if (o == null) {
for (int i = index ; i < elementCount ; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = index ; i < elementCount ; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
也就是for循环过去。其实比较easy。
remove
public boolean remove(Object o) {
return removeElement(o);
}
// 移除元素,首先定位元素位置,如果元素存在,那么就移除
public synchronized boolean removeElement(Object obj) {
modCount++;
int i = indexOf(obj);
if (i >= 0) {
removeElementAt(i);
return true;
}
return false;
}
public synchronized void removeElementAt(int index) {
modCount++;
if (index >= elementCount) {
throw new ArrayIndexOutOfBoundsException(index + " >= " +
elementCount);
}
else if (index < 0) {
throw new ArrayIndexOutOfBoundsException(index);
}
int j = elementCount - index - 1;
// 将对应的索引值之后都往前移动一个位置。
if (j > 0) {
System.arraycopy(elementData, index + 1, elementData, index, j);
}
elementCount--;
elementData[elementCount] = null; /* to let gc do its work */
}
我觉得其他的源码都比较简单,这里就不一一列出了。
总结
Vector和ArrayList在功能上其实都是一致的, 只不过是Vector使用了synchronized,在涉及到elementData属性添加、修改、删除的地方都加锁操作了,将一个并行计算修改为了串行操作。虽然是线程安全,但是性能方面不是特别好,在之后分析完成Set和Map代码之后会介绍一下current包中的一些线程安全的类是如何实现的。