LDA处理文档主题分布
这篇文章主要是讲述如何通过LDA处理文本内容TXT,并计算其文档主题分布。
在了解本篇内容之前,推荐先阅读相关的基础知识:
LDA文档主题生成模型入门
结巴中文分词介绍
爬取百度百科5A景点摘要并实现分词
使用scikit-learn计算文本TF-IDF值
一、完整程序
from sklearn import feature_extraction
from sklearn.feature_extraction.text import CountVectorizer
if __name__ == "__main__":
corpus = []
for line in open('test.txt', 'r').readlines():
corpus.append(line.strip())
#print (corpus)
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus)
word = vectorizer.get_feature_names() # 所有的特征词,即关键词
print (word)
#print(X)
analyze = vectorizer.build_analyzer()
weight = X.toarray()
print(weight)
import numpy as np
import lda
# 训练模型
model = lda.LDA(n_topics = 2, n_iter = 500, random_state = 1)
model.fit(np.asarray(weight))
# 主题-词分布
topic_word = model.topic_word_ #生成主题以及主题中词的分布
print("topic-word:\n", topic_word)
# 计算topN关键词
n = 5
for i, word_weight in enumerate(topic_word):
#print("word_weight:\n", word_weight)
distIndexArr = np.argsort(word_weight)
#print("distIndexArr:\n", distIndexArr)
topN_index = distIndexArr[:-(n+1):-1]
#print("topN_index:\n", topN_index) # 权重最在的n个
topN_words = np.array(word)[topN_index]
print(u'*Topic {}\n- {}'.format(i, ' '.join(topN_words)))
# 绘制主题-词分布图
import matplotlib.pyplot as plt
f, ax= plt.subplots(2, 1, figsize=(6, 6), sharex=True)
for i, k in enumerate([0, 1]): #两个主题
ax[i].stem(topic_word[k,:], linefmt='b-',
markerfmt='bo', basefmt='w-')
ax[i].set_xlim(-2,20)
ax[i].set_ylim(0, 1)
ax[i].set_ylabel("Prob")
ax[i].set_title("topic {}".format(k))
ax[1].set_xlabel("word")
plt.tight_layout()
plt.show()
# 文档-主题分布
doc_topic = model.doc_topic_
print("type(doc_topic): {}".format(type(doc_topic)))
print("shape: {}".format(doc_topic.shape))
label = []
for i in range(10):
print(doc_topic[i])
topic_most_pr = doc_topic[i].argmax()
label.append(topic_most_pr)
print("doc: {} topic: {}".format(i, topic_most_pr))
print(label) # 前10篇文章对应的主题列表
# 绘制文档-主题分布图
import matplotlib.pyplot as plt
f, ax= plt.subplots(6, 1, figsize=(8, 8), sharex=True)
for i, k in enumerate([0,1,2,3,8,9]):
ax[i].stem(doc_topic[k,:], linefmt='r-',
markerfmt='ro', basefmt='w-')
ax[i].set_xlim(-1, 2) #x坐标下标
ax[i].set_ylim(0, 1.2) #y坐标下标
ax[i].set_ylabel("Probability")
ax[i].set_title("Document {}".format(k))
ax[5].set_xlabel("Topic")
plt.tight_layout()
plt.show() 二、程序分析
(一)test.txt
这里的test.txt里面包含了分词后的内容
新春 备 年货 , 新年 联欢晚会
新春 节目单 , 春节 联欢晚会 红火
大盘 下跌 股市 散户
下跌 股市 赚钱
金猴 新春 红火 新年
新车 新年 年货 新春
股市 反弹 下跌
股市 散户 赚钱
新年 , 看 春节 联欢晚会
大盘 下跌 散户 散户若想了解分词过程,可参考上面推荐的《[结巴中文分词介绍》和《爬取百度百科5A景点摘要并实现分词》。
(二)corpus
corpus是一个数组,存放的是test.txt中的所有内容,每行内容作为数组的一个元素:
['新春 备 年货 , 新年 联欢晚会', '新春 节目单 , 春节 联欢晚会 红 火', '大盘 下跌 股市 散户', '下跌 股市 赚钱', '金猴 新春 红火 新年', '新车 新年 年货 新春', '股市 反弹 下跌', '股市 散户 赚钱', '新年 , 看 春节 联欢晚会', '大盘 下跌 散户 散户'](三)特征词
vectorizer.fit_transform(corpus)的作用是提取特征词,这里一共提取出15个特征词:
['下跌', '反弹', '大盘', '年货', '散户', '新年', '新春', '新车', ' 春节', '红火', '联欢晚会', '股市', '节目单', '赚钱', '金猴']特征词不包含标点符号,比如逗号,也不包含单个的字,比如“备”、“看”。
注意英文是按字母顺序排序的,比如“and”肯定会放在“bee”之前。
中文按什么顺序我还不清楚,为何“下跌”放在“反弹”之前,“金猴”放在最后?有了解者盼指教。
(四)特征词的出现次数
X = vectorizer.fit_transform(corpus)是用于获取特征词的出现次数
(0, 10) 1
(0, 5) 1
(0, 3) 1
(0, 6) 1
(1, 9) 1
(1, 8) 1
(1, 12) 1
(1, 10) 1
(1, 6) 1
(2, 4) 1
(2, 11) 1
(2, 0) 1
(2, 2) 1
(3, 13) 1
(3, 11) 1
(3, 0) 1
(4, 14) 1
(4, 9) 1
(4, 5) 1
(4, 6) 1
(5, 7) 1
(5, 5) 1
(5, 3) 1
(5, 6) 1
(6, 1) 1
(6, 11) 1
(6, 0) 1
(7, 13) 1
(7, 4) 1
(7, 11) 1
(8, 8) 1
(8, 10) 1
(8, 5) 1
(9, 4) 2
(9, 0) 1
(9, 2) 1(0, 10) 1 表示第10个词“联欢晚会”在第0行里出现了1次。注意对于程序而言都是从0开始计数的,而不是从1开始。
(0, 5) 1 表示第5个词“新年”在第0行里出现了1次。
(0, 3) 1 表示第3个词“年货”在第0行里出现了1次。
……
(9, 4) 2 表示第4个词“散户”在第9行里出现了2次。
(9, 0) 1 表示第0个词“下跌”在第9行里出现了1次。
(9, 2) 1 表示第2个词“大盘”在第9行里出现了1次。
weight = X.toarray()的作用是把特征语出现次数放在数组里
[[0 0 0 1 0 1 1 0 0 0 1 0 0 0 0]
[0 0 0 0 0 0 1 0 1 1 1 0 1 0 0]
[1 0 1 0 1 0 0 0 0 0 0 1 0 0 0]
[1 0 0 0 0 0 0 0 0 0 0 1 0 1 0]
[0 0 0 0 0 1 1 0 0 1 0 0 0 0 1]
[0 0 0 1 0 1 1 1 0 0 0 0 0 0 0]
[1 1 0 0 0 0 0 0 0 0 0 1 0 0 0]
[0 0 0 0 1 0 0 0 0 0 0 1 0 1 0]
[0 0 0 0 0 1 0 0 1 0 1 0 0 0 0]
[1 0 1 0 2 0 0 0 0 0 0 0 0 0 0]](四)主题-词分布
lda.LDA(n_topics = 2, n_iter = 500, random_state = 1)
n_topics表示主题数,这里因为文件较少,咱们一眼就可以看出主题是两个。在复杂场景中,这个参数不好确定。
n_iter表示训练迭代的次数 。
topic_word = model.topic_word_表示主题中特征词的分布:
topic-word:
[[0.23381924 0.05889213 0.11720117 0.00058309 0.23381924 0.00058309
0.00058309 0.00058309 0.00058309 0.00058309 0.00058309 0.23381924
0.00058309 0.11720117 0.00058309]
[0.00049628 0.00049628 0.00049628 0.09975186 0.00049628 0.19900744
0.19900744 0.05012407 0.09975186 0.09975186 0.14937965 0.00049628
0.05012407 0.00049628 0.05012407]]这里可以看出,第一个主题里的第0,1,2,4,11,13个特征词占的权重较大;第二个主题里第3,5,6,7,8,9,10,12,14个语占的权重较大。
这个权重是什么计算的呢?权重 约等于 出现次数/该主题的所有词,这里的所有词不包含符号和单个字(比如“看”和“备”)
例1:求“下跌”的权重
“下跌”共出现了4次,“下跌”属于主题0
主题0包含了第2,3,6,7,9行共17个词,
所以,w(“下跌”) = 4 / 17 = 0.235294
例2:求“年货”的权重
“年货”共出现了2次,“年货”属于主题1
主题0包含了第0,1,4,5,8行共20个词
所以,w(“年货”) = 2/20 = 0.1
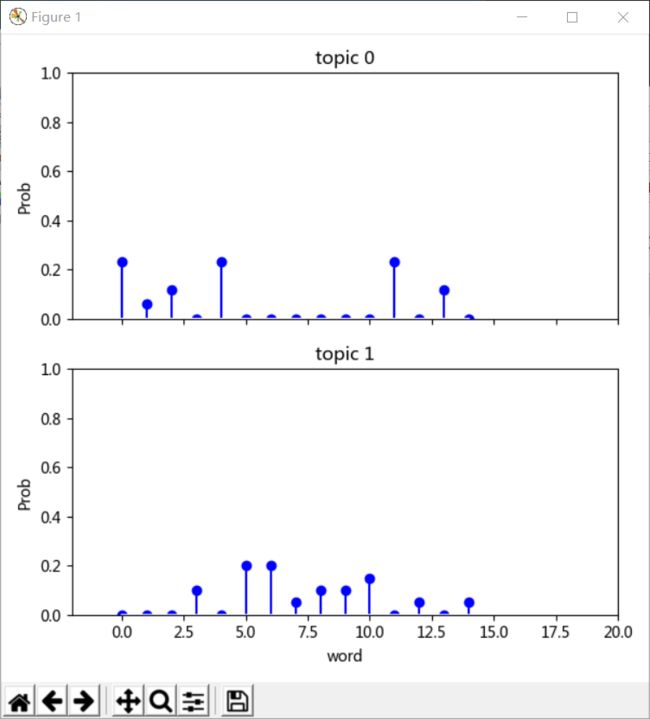
(五)求每个主题的前5个关键词
代码:
# 计算topN关词
n = 5
for i, word_weight in enumerate(topic_word):
#print("word_weight:\n", word_weight)
distIndexArr = np.argsort(word_weight)
#print("distIndexArr:\n", distIndexArr)
topN_index = distIndexArr[:-(n+1):-1]
#print("topN_index:\n", topN_index) # 权重最在的n个
topN_words = np.array(word)[topN_index]
print(u'*Topic {}\n- {}'.format(i, ' '.join(topN_words))) 运行结果:
*Topic 0
- 股市 散户 下跌 赚钱 大盘
*Topic 1
- 新春 新年 联欢晚会 红火 春节可以看到,计算结果与上一步的图形是可以相对应的。
(六)文档-主题分布
type(doc_topic):
shape: (10, 2)
[0.02380952 0.97619048]
doc: 0 topic: 1
[0.01923077 0.98076923]
doc: 1 topic: 1
[0.97619048 0.02380952]
doc: 2 topic: 0
[0.96875 0.03125]
doc: 3 topic: 0
[0.02380952 0.97619048]
doc: 4 topic: 1
[0.02380952 0.97619048]
doc: 5 topic: 1
[0.96875 0.03125]
doc: 6 topic: 0
[0.96875 0.03125]
doc: 7 topic: 0
[0.03125 0.96875]
doc: 8 topic: 1
[0.97619048 0.02380952]
doc: 9 topic: 0
[1, 1, 0, 0, 1, 1, 0, 0, 1, 0] 总共有10篇文档,分为两个主题。
每个doc_topic[i]中包含了两个值,一个是主题0的概率,一个是主题1的概率。哪个概率大说明这个文档的主题是哪个。
最终10篇文章分别对应于主题1, 1, 0, 0, 1, 1, 0, 0, 1, 0。
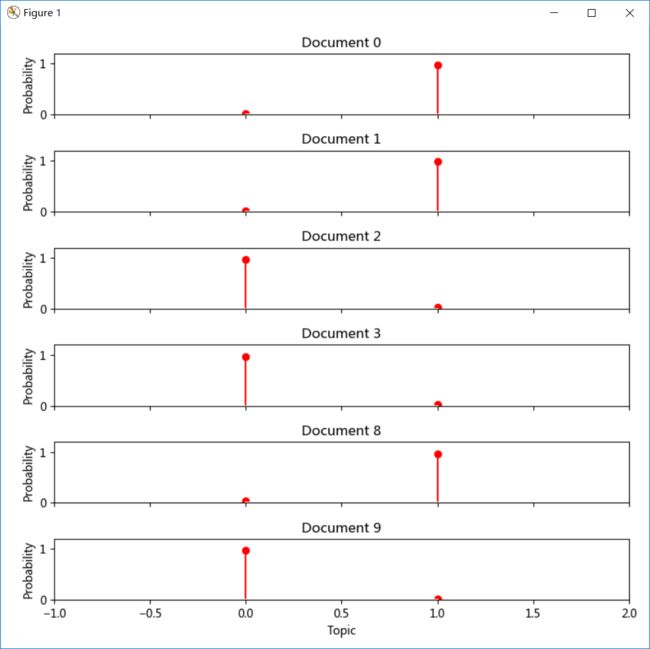
这里列出了其中6个文档的主题分布图。
三、参考
https://blog.csdn.net/eastmount/article/details/50891162
TopCoder & Codeforces & AtCoder交流QQ群:648202993
更多内容请关注微信公众号
