2019独角兽企业重金招聘Python工程师标准>>> 
mysql自动同步
以下教程均使用mysql自带的自动同步功能
全库单向自动同步
本例把192.168.3.45上名称为ewater_main的数据库自动同步到192.168.3.68的ewater_main数据库,前者被称为主库(master),后者称为从库(slave)
注意同步是单向(从192.168.3.45到192.168.3.68)。且是全库(全部的表)。
首先用navicat,分别在master和slave都建一个用于同步的用户,用户密码都是repl,然后允许主机先设为%(需要考虑安全性可以设具体ip)
在master的主机也就是192.168.3.45上操作,打开mysql的命令行
输入:
grant replication slave on *.* to 'repl'@'192.168.3.68' identified by 'repl';
其中192.168.3.68是slave的ip,第一个repl是用于同步用户的用户名,第二个repl是同步用户的密码
再输入:
flush privileges;
结果如图

然后修改master的my.ini文件
PS:注意,以下提到的在my.ini里面的配置项,有些已经存在文件,有些不存在,因此在修改前必须先搜索一次确认是否已存在, 否则多个同名配置项后者会把之前的覆盖
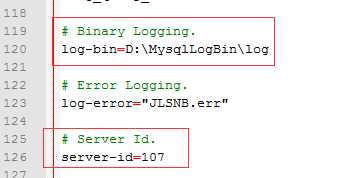
找到server-id项,并修改,可以任意改一个,但不要是1,本例设为107
然后再设置配置项log-bin,值设为一个绝对路径,此值用于存储二进制日志文件。注意,例如此例中配置为D:\MysqlLogBin\log,意思是日志文件都放在D:\MysqlLogBin文件夹下,且日志文件都以log开头
配置效果如下
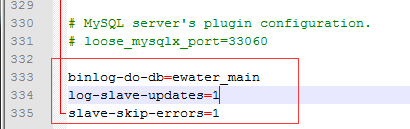
设置binlog-do-db,值为要同步的数据库名,如果备份多个数据库,重复设置这个选项即可
设置log-slave-updates=1,这个参数一定要加上,否则不会给更新(可以理解为sql的update)的记录些到二进制文件
设置slave-skip-errors=1,意思是跳过错误,继续执行复制操作
其他可选配置:
binlog-ignore-db=xxx,意思是不需要备份的数据库名,如果备份多个数据库,重复设置这 个选项即可
配置效果如下:
重启master的mysql
在命令行输入:
show master status;
查看作为master的状态

其中binlog-do-db就是刚才配置的binlog-do-db,而File和Position要记着,后面配置从库(slave)要用到
然后开始配置slave
修改my.ini
配置server-id,可配置任意值,但不能是默认值1,也不能跟master的相同,本例配为109
效果如下:

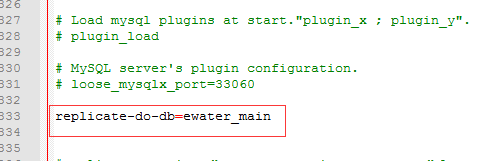
配置replicate-do-db,意思是从库被同步的数据库,效果如下
重启mysql
打开mysql的命令行
开始在slave配置master的配置
输入:stop slave;
输入:(注意:以下的换行在命令行输入时真的要回车换行,有些行有逗号也真的要输入)
change master to
master_host='192.168.3.45',
master_user='repl',
master_password='repl',
master_log_file='log.000004',
master_log_pos=2910;
其中master_host是master的ip,master_user和master_password是master库用于同步的用户和密码,master_log_file和master_log_pos都是master的信息(刚才有说,也如下图)

输入时类似下图

输入:
start slave;
重启数据库
到此配置完毕
在此可以用命令
show slave status\G;
看看作为slave的配置和状态,其中Slave_IO_Running和Slave_SQL_Running值应为Yes

然后开始测试
打开navicat连接master的ewater_main库,在ew_companydemo表添加一条记录

再打开slave的ewater_main库,打开ew_companydemo表,应该可以看到
master加的
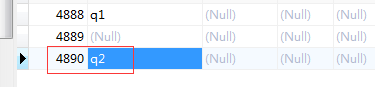
slave同一个表 刷新能看到

到此同步配置完成
设置只同步指定的表
本例假设只同步ewater_main库的ew_companydemo表,可使用配置项replicate-wild-do-table,如果要设置多个表可添加多行

PS:注意之前如果配置了全库同步也就是replicate-do-db需要屏蔽,假设如果配置同时有replicate-do-db和replicate-do-db那两条都会生效
另外,如果要设置不同步哪个表,可用配置项replicate-wild-ignore-table,格式类似
设置同步的主从库名称不同
本例假设把master的ewater_main库同步到slave的ewater_db2,可用配置项replicate-rewrite-db
应配置为replicate-rewrite-db = ewater_main -> ewater_db2,其中->左边是master的库,右边是同步到的slave的库

注意:如果还有设置只同步具体表,可以与replicate-wild-do-table同时使用,但是注意配置的库名称应该是slave的库名,例如在以上配置基础上增加只同步ewater_db2库的ew_companydemo表,可配置为

同步出错调试技巧
当发现同步失效,很可能是某次同步过程中出错,导致后面的同步失败
查看同步失败异常信息,可以在slave执行命令 show slave status\G;
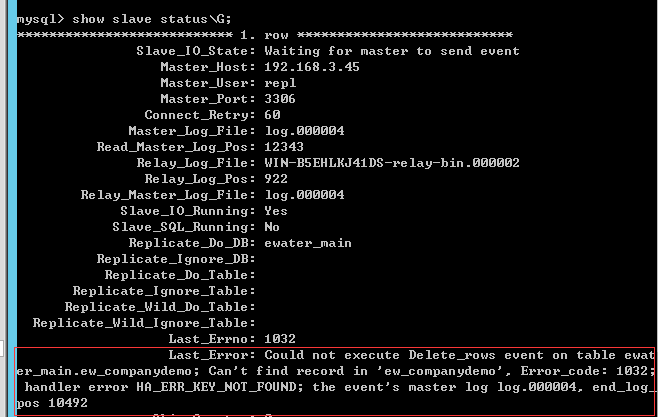
然后根据错误信息进行修改,错误原因通常是因为两个库数据不同而造成slave执行master的数据库操作失败
以下是一些常见错误
master新增记录的主键在slave有重复
例如同步某表,在master中主键值为110,而slave已经存在主键为110的此行
解决方法可以在slave删除主键为110的这行
master删除记录的主键在slave没有
例如同步某表,在master中主键值为110,而slave已经没有主键为110的行
解决方法可以在slave增加主键为110的这行
万能解决方案
了解自动同步原理的可知,slave是执行master的日志文件实现同步,那当执行到某行出错,可以重新设置同步的行(position)来跳过出错的行以解决
具体方法是在master查询日志文件最新的position
然后在slave重新change master to XXX(具体命令上面有写),其中position设为最新的即可
自动同步原理
master库会把所有数据库操作写到日志文件(因此master配置中有bin-log的配置)
slave会读取master的日志文件且在slave在操作一次,以实现同步
由于是在slave重复执行一次master的sql,因此,当slave的数据与master不同,就有可能会出错
例如经典delete错误:假设slave没有主键=13的行,但是master有且delete了主键为13的行,那在slave delete时就会找不到行,就会出错
slave可设置从master的哪个log文件的哪行(position)开始同步
也因此slave有change master to xxxx的操作