MySQL系列:innodb源码分析之page结构解析
在 表空间结构分析当中,我们知道innodb的最小物理存储分配单位是page页,在MySQL-3.23版本的源码中,页只有两种页,一种是index page,一种是undo page。其类型值定义在fil0fil.h当中。
FIL_PAGE_INDEX 数据索引页,在表空间的inode page和xdes page都是属于这类。
FIL_PAGE_UNDO_LOG 事务回滚日志页。
在这里我们主要分析的是 index page,undo log page在事务部分来介绍。不管是index page还是undo log page都是由三部分组成,page_header、page_body、page_trailer三部分组成。针对index page来分析者三部分结构。
1.page header
page header是page的头信息,占用38个字节,分别存储以下信息:
FIL_PAGE_SPACE 4字节 page所属的表空间的space id
FIL_PAGE_OFFSET 4字节 page no,一般是在表空间的物理偏移量
FIL_PAGE_PREV 4 字节 前一页的page no (B+tree的叶子节点是通过链表串起来的,有前后关系)
FIL_PAGE_NEXT 4字节 后一页的page no
FIL_PAGE_LSN 8字节 更改记录时最大的redo log lsn,一般用在redo log恢复时使用
FIL_PAGE_TYPE 2字节 page的类型
FIL_PAGE_FILE_FLUSH_LSN 8字节 space文件最后被flush是的redo log lsn,这个值只会在space的第一个页中被设置
FIL_PAGE_ARCH_LOG_NO 4字节 最后被归档的archive log file 序号,这个值只会在space的第一个页中被设置
2.page trailer
page trailer是在文件末尾的最后8个字节, 低位4个字节是用来表示page页中数据的checksum,高位4位是用来存储FIL_PAGE_LSN的部分信息,关于checksum的计算是通过buf_calc_page_checksum这个函数来结算得到的,基本是通过对page中数据作为参数用ut_fold_binary来快速计算得到。在后续的版本中,page checksum是可以选择其他算法来做计算。这两个字在页保存到物理磁盘的时会进行更行,在页从物理磁盘读取出来的时候会被校验。宗旨就是保证页的完整性。
3.page body
index page body是由5部分组成,分别是body header、recorders、free recorders、free heap和page directory
组成。body header的结构定义如下:
#define PAGE_N_DIR_SLOTS 0 /*page directory拥有的slot个数*/
#define PAGE_HEAP_TOP 2 /*heap中空闲位置的偏移量*/
#define PAGE_N_HEAP 4 /*heap中的记录数,所有分配出去的记录数,free rec + PAGE_N_RECS + 2*/
#define PAGE_FREE 6 /*指向page中空闲空间的偏移量*/
#define PAGE_GARBAGE 8 /*已删除的记录字节数,用于重分配*/
#define PAGE_LAST_INSERT 10 /*最后插入记录的位置*/
#define PAGE_DIRECTION 12 /*记录的操作方向,PAGE_LEFT PAGE_RIGHT PAGE_SAME_REC PAGE_SAME_PAGE PAGE_NO_DIRECTION*/
#define PAGE_N_DIRECTION 14 /*同一方向连续插入的记录数*/
#define PAGE_N_RECS 16 /*页中存在的记录数,不包括infimum和supremum*/
#define PAGE_MAX_TRX_ID 18 /*修改当前页最大的事务ID*/
#define PAGE_HEADER_PRIV_END 26
#define PAGE_LEVEL 28 /*当前页在索引树的层位置*/
#define PAGE_BTR_SEG_LEAF 36 /*B+树叶子节点所在段的segment header信息*/
define PAGE_BTR_SEG_TOP (36 + FSEG_HEADER_SIZE) /*B+树非叶子节点所在段的segment header信息*/
innodb在把真个页可以用的空间当着一个heap,当需要插入记录的时候,首先会在PAGE FREE中找是否有合适的记录
可
以用,如果没有,就会在PAGE_HEAP_TOP的偏移上分配一个指定大小的rec_t的记录块,并将记录案主键值插入到
recorders
当中。那么recorders是通过什么样的方式组织的呢?
3.1记录的组织方式
在index page body中,rec(记录)组织方式采用的是单向链表的方式来组织的,最前面一个记录和最后面一个记录是innodb定义的虚拟记录,叫做infimum和supremum。这两个记录的物理物质是在body header后面紧接着的连个记录。
其偏移如下:
#define PAGE_DATA (PAGE_HEADER + 36 + 2 * FSEG_HEADER_SIZE)
#define PAGE_INFIMUM (PAGE_DATA + 1 + REC_N_EXTRA_BYTES) /*本page中索引最小的记录位置*/
#define PAGE_SUPREMUM (PAGE_DATA + 2 + 2 * REC_N_EXTRA_BYTES + 8) /*本page中索引最大的记录位置*/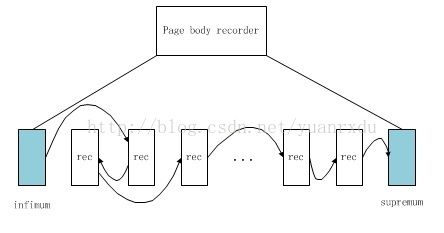
3.2body free list
除了有效记录以外,page中还有一类是之间使用过但被删除的记录,这类记录不会直接回收到heap中(因为
rec是逻辑
顺序关系进行组织
的,无法直接回收到heap中),innodb采用了page free recorders列表来组织和管理,
通过
body header中的
PAGE_FREE来进行定位,
PAGE_FREE指向第一个被删除的rec记录的页内偏移量。
示意图如下:

body header除了用
PAGE_FREE来管理释放的记录外,还使用了
PAGE_GARBAGE来管理其空间大小,这个值表示所有删除的记录占用空间字节总和,以便删除的记录可以重复被使用,提高空间的使用率。
除了recorders和free recorders外,还有一个连续的空间,这个空间是用来做记录分配的,只有当free recorders中没有合适的记录空间的时候,才会在这个连续空间上分配记录。这个空间的地址偏移是在
PAGE_HEAP_TOP中的。
3.3directory slots
innodb为了快速查找记录,在body的后面定义了一个称之为 directory的目录槽(slots),每个槽位占用两个字节,采用的是逆序存储,也就是说mifimum的槽位总是在body最后2个字节上,其他的一次类推。每个槽位可以存储多个纪录。以下是各种slot的记录数描述范围(n_owned):| Infimum slot owned |
只有一条记录 |
| supremum slot owned |
1到8条记录 |
| 普通slot owned |
4到8条记录 |
如果普通slot在插入新的一条记录时,普通slot或者
supremum管理的记录数是8,这个时候会对
supremum进行split,产生一
个slots,所以
它的范围是从4开始。以下是directory的一个关系示意图:

从上可以看出,slot指向的rec中的owned代表的是向前有多少个rec属于这个slot管辖,中间被管辖的rec的owned = 0。通过directory的二分查找只能查到对应记录所属的slot,还需要通过owned内部的二分查找才能精确定位到对应的记录。这种设计的做法可以减小
directory对page空间的占用,又能有很好查找的效率。关于slot相关的函数说明:
page_dir_split_slot slot分裂函数,当一个slot管辖的范围内插入新的记录后超出其最大管理的记
录数,就会对其进行平均范围分裂。
page_dir_balance_slot slot均衡函数,当一个slot管辖的范围内有记录删除后,其管理的记录数小于
它最小范围,就会和邻近的slot做均
衡。
不管是均衡还是分裂,都是最大范围提高
directory存储空间效率和记录查找效率。
3.4index page结构关系图

4页的操作
innodb的index page对记录的操作主要有3种:查找记录、插入记录、删除记录。关于page的操作实现在page0cur.*
当中,
在这些操作的中,innodb定义了一个page_cur_t,也就是page的游标,它是个逻辑概念的游标,只在内存中
有效。这个page cur是指向当前操作的记录。
定义如下:
typedef struct page_cur_struct
{
byte* rec; /*游标记录的指针*/
}page_cur_t;4.1查询操作
我们知道在innodb的B+Tree索引搜索中,只能找到对应记录所在的index page,那么找到page后,会在页中进行记录查找,这个页内查找过程如下:
1.先通过key在page的directory slots中进行二分查找,找到key对应的slot
2.因为slot是管理多个记录(普通的slot owned = [4,8]),所以会再根据KEY在对应的slot管理的记录中一次二分查找,直到找到记录为止。
页内查找的实现在page0cur.c的page_cur_search_with_match函数当中,这个函数除了返回查找的记录以外,还会记录二分查找过程中匹配的字节数和经过的跳数。值得注意的是这个函数支持四种模式的查找,分别定义如下:
#define PAGE_CUR_G 1 /*大于查询*/
#define PAGE_CUR_GE 2 /*大于等于查询*/
#define PAGE_CUR_L 3 /*小于查询*/
#define PAGE_CUR_LE 4 /*小于等于查询*/4.2插入操作
在记录插入之前,会通过要插入记录KEY找到要插入的位置,查找的模式是PAGE_CUR_LE,具体步骤如下:
1.通过记录的key和记录查找函数查找要插入的位置(操作page cur指向插入记录的前一个记录)
2.修改前后记录的关联关系和插入记录的关联关系
3.修改page游标方向计数器、page last insert
4.修改所在的slot的owned数值,如果超出范围,进行split slot
5.因为插入记录是对页进行修改,所以记录插入记录的mtr log。以便异常时对页的恢复。
插入记录的mtr log构造比较复杂,以下是它的结构示意图:

这里要解释的是mismach_index这个变量,innodb为了节省存储空间,前后两条记录会做相同比较,这个变量就是插入的记录和其前面的记录从开始位置相同字节数,这样rec data是存储了与之前记录不同的数据。
一条记录的插入示意图:

整记录插入过程在page0cur.c中的page_cur_insert_rec_low函数中实现的。
4.3删除操作
记录删除也是首先会通过删除记录的key或者记录地址来确定操作page cur.操作步骤如下:
1.通过记录信息确定page cur
2.添加一条删除记录的mtr log
3.将记录前后对应关联关系进行删除和更改
4.设置page last insert和其他的头信息(n _rec)
5.将记录插入到body header free列表的起始位置,并修改PAGE_GARBAGE
6.设置所在slot的owned,如果小于管辖范围的最小值,进行slot的均衡化。
删除的mtr log格式如下:

删除记录示意图:
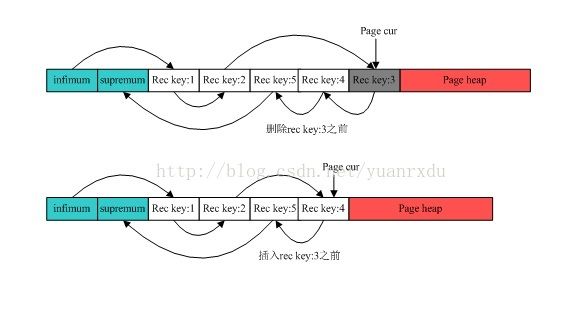
5.小结
innodb的index page结构是一个高效利用空间的存储结构,不仅考虑到查询的速度,也考虑了合理的利用存储空
间的存储效率。innodb在这两者之间找到了比较好的平衡点。页除了提供基本的插入删除查询操作外,还提供批量
拷贝记录、批量删除记录等功能。当这些都是基于基本的插入删除操作之上的。批量操作函数如下:
| page_copy_rec_list_end |
将page中的rec之后的记录全部复制到new page,包括rec |
| page_copy_rec_list_start |
将page中在rec之前的记录全部拷贝到new page当中,不包括rec |
| page_delete_rec_list_end |
将page中的rec之后的记录全部删除,包括rec |
| page_delete_rec_list_start |
将page中在rec之前的记录全部删除,不包括rec |
| page_move_rec_list_end |
将page中rec之后的记录全部move到new page中,包括rec,这些记录在page是被删除的 |
| page_move_rec_list_start |
将page中rec之前的记录全部move到new page中,不包括rec,这些记录在page是被删除的 |
innodb提供这些函数主要是方便上层调用。通过分析page的结构可以很好的理解innodb的记录组织方式,也有利于去理解B+Tree的索引方式。
索引页相关参考: http://blog.jcole.us/2013/01/07/the-physical-structure-of-innodb-index-pages/