阿里云天池Python训练营(day6打卡)
【ML&Py】×阿里云天池Python训练营(day6打卡)——1.集合、2.序列
- 一、学习内容概览
-
- 1.1 学习地址:[阿里云天池python训练营](https://tianchi.aliyun.com/specials/promotion/aicamppython)
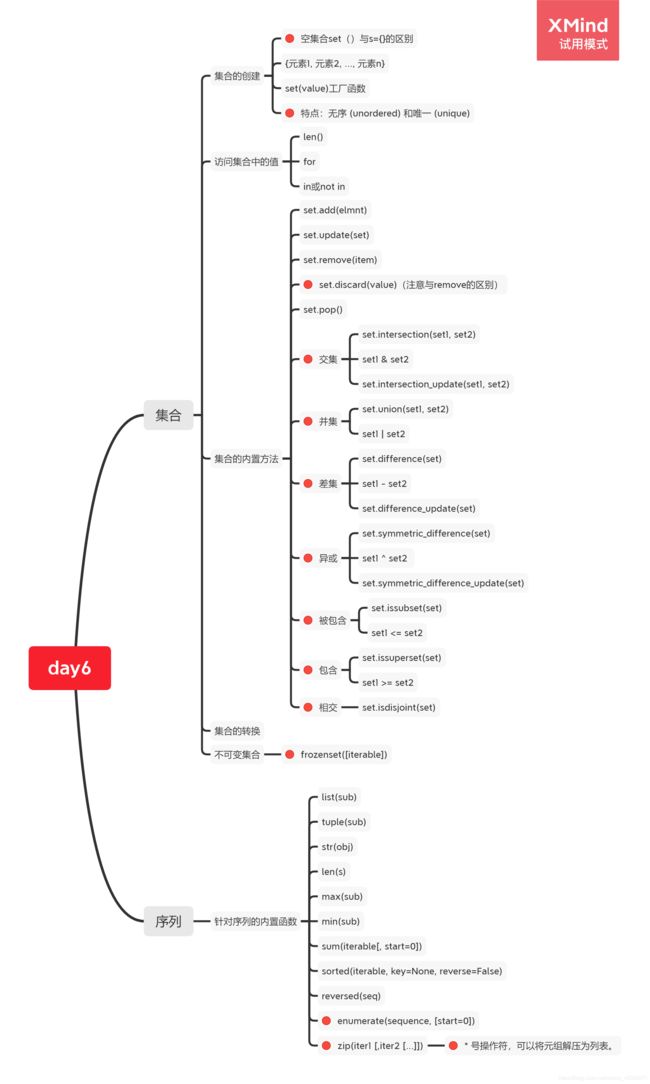
- 1.2 思维导图:
- 二、具体学习内容
-
- 2.1 集合
-
- 2.1.1 集合的创建
- 2.1.2 访问集合中的值
- 2.1.3 集合的内置方法
- 2.1.4 集合的转换
- 2.1.5 不可变集合
- 2.2 序列
-
- 2.2.1 针对序列的内置函数
- 三、学习总结
一、学习内容概览
1.1 学习地址:阿里云天池python训练营
1.2 思维导图:
二、具体学习内容
2.1 集合
Python 中set与dict类似,也是一组key的集合,但不存储value。由于key不能重复,所以,在set中,没有重复的key。
注意,key为不可变类型,即可哈希的值。
num = {
}
print(type(num)) # 2.1.1 集合的创建
- 先创建对象再加入元素。
- 在创建空集合的时候只能使用
s = set(),因为s = {}创建的是空字典。
basket = set()
basket.add('apple')
basket.add('banana')
print(basket) # {'banana', 'apple'}
- 直接把一堆元素用花括号括起来
{元素1, 元素2, ..., 元素n}。 - 重复元素在
set中会被自动被过滤。
basket = {
'apple', 'orange', 'apple', 'pear', 'orange', 'banana'}
print(basket) # {'banana', 'apple', 'pear', 'orange'}
- 使用
set(value)工厂函数,把列表或元组转换成集合。
a = set('abracadabra')
print(a)
# {'r', 'b', 'd', 'c', 'a'}
b = set(("Google", "Lsgogroup", "Taobao", "Taobao"))
print(b)
# {'Taobao', 'Lsgogroup', 'Google'}
c = set(["Google", "Lsgogroup", "Taobao", "Google"])
print(c)
# {'Taobao', 'Lsgogroup', 'Google'}
【例子】去掉列表中重复的元素
lst = [0, 1, 2, 3, 4, 5, 5, 3, 1]
temp = []
for item in lst:
if item not in temp:
temp.append(item)
print(temp) # [0, 1, 2, 3, 4, 5]
a = set(lst)
print(list(a)) # [0, 1, 2, 3, 4, 5]
从结果发现集合的两个特点:无序 (unordered) 和唯一 (unique)。
由于 set 存储的是无序集合,所以我们不可以为集合创建索引或执行切片(slice)操作,也没有键(keys)可用来获取集合中元素的值,但是可以判断一个元素是否在集合中。
2.1.2 访问集合中的值
- 可以使用
len()內建函数得到集合的大小。
s = set(['Google', 'Baidu', 'Taobao'])
print(len(s)) # 3
- 可以使用
for把集合中的数据一个个读取出来。
s = set(['Google', 'Baidu', 'Taobao'])
for item in s:
print(item)
# Baidu
# Google
# Taobao
- 可以通过
in或not in判断一个元素是否在集合中已经存在
s = set(['Google', 'Baidu', 'Taobao'])
print('Taobao' in s) # True
print('Facebook' not in s) # True
2.1.3 集合的内置方法
set.add(elmnt)用于给集合添加元素,如果添加的元素在集合中已存在,则不执行任何操作。
fruits = {
"apple", "banana", "cherry"}
fruits.add("orange")
print(fruits)
# {'orange', 'cherry', 'banana', 'apple'}
fruits.add("apple")
print(fruits)
# {'orange', 'cherry', 'banana', 'apple'}
set.update(set)用于修改当前集合,可以添加新的元素或集合到当前集合中,如果添加的元素在集合中已存在,则该元素只会出现一次,重复的会忽略。
x = {
"apple", "banana", "cherry"}
y = {
"google", "baidu", "apple"}
x.update(y)
print(x)
# {'cherry', 'banana', 'apple', 'google', 'baidu'}
y.update(["lsgo", "dreamtech"])
print(y)
# {'lsgo', 'baidu', 'dreamtech', 'apple', 'google'}
set.remove(item)用于移除集合中的指定元素。如果元素不存在,则会发生错误。
fruits = {
"apple", "banana", "cherry"}
fruits.remove("banana")
print(fruits) # {'apple', 'cherry'}
set.discard(value)用于移除指定的集合元素。remove()方法在移除一个不存在的元素时会发生错误,而discard()方法不会。
fruits = {
"apple", "banana", "cherry"}
fruits.discard("banana")
print(fruits) # {'apple', 'cherry'}
set.pop()用于随机移除一个元素。
fruits = {
"apple", "banana", "cherry"}
x = fruits.pop()
print(fruits) # {'cherry', 'apple'}
print(x) # banana
由于 set 是无序和无重复元素的集合,所以两个或多个 set 可以做数学意义上的集合操作。
set.intersection(set1, set2)返回两个集合的交集。set1 & set2返回两个集合的交集。set.intersection_update(set1, set2)交集,在原始的集合上移除不重叠的元素。
a = set('abracadabra')
b = set('alacazam')
print(a) # {'r', 'a', 'c', 'b', 'd'}
print(b) # {'c', 'a', 'l', 'm', 'z'}
c = a.intersection(b)
print(c) # {'a', 'c'}
print(a & b) # {'c', 'a'}
print(a) # {'a', 'r', 'c', 'b', 'd'}
a.intersection_update(b)
print(a) # {'a', 'c'}
set.union(set1, set2)返回两个集合的并集。set1 | set2返回两个集合的并集。
a = set('abracadabra')
b = set('alacazam')
print(a) # {'r', 'a', 'c', 'b', 'd'}
print(b) # {'c', 'a', 'l', 'm', 'z'}
print(a | b)
# {'l', 'd', 'm', 'b', 'a', 'r', 'z', 'c'}
c = a.union(b)
print(c)
# {'c', 'a', 'd', 'm', 'r', 'b', 'z', 'l'}
set.difference(set)返回集合的差集。set1 - set2返回集合的差集。set.difference_update(set)集合的差集,直接在原来的集合中移除元素,没有返回值。
a = set('abracadabra')
b = set('alacazam')
print(a) # {'r', 'a', 'c', 'b', 'd'}
print(b) # {'c', 'a', 'l', 'm', 'z'}
c = a.difference(b)
print(c) # {'b', 'd', 'r'}
print(a - b) # {'d', 'b', 'r'}
print(a) # {'r', 'd', 'c', 'a', 'b'}
a.difference_update(b)
print(a) # {'d', 'r', 'b'}
set.symmetric_difference(set)返回集合的异或。set1 ^ set2返回集合的异或。set.symmetric_difference_update(set)移除当前集合中在另外一个指定集合相同的元素,并将另外一个指定集合中不同的元素插入到当前集合中。
a = set('abracadabra')
b = set('alacazam')
print(a) # {'r', 'a', 'c', 'b', 'd'}
print(b) # {'c', 'a', 'l', 'm', 'z'}
c = a.symmetric_difference(b)
print(c) # {'m', 'r', 'l', 'b', 'z', 'd'}
print(a ^ b) # {'m', 'r', 'l', 'b', 'z', 'd'}
print(a) # {'r', 'd', 'c', 'a', 'b'}
a.symmetric_difference_update(b)
print(a) # {'r', 'b', 'm', 'l', 'z', 'd'}
set.issubset(set)判断集合是不是被其他集合包含,如果是则返回 True,否则返回 False。set1 <= set2判断集合是不是被其他集合包含,如果是则返回 True,否则返回 False。
x = {
"a", "b", "c"}
y = {
"f", "e", "d", "c", "b", "a"}
z = x.issubset(y)
print(z) # True
print(x <= y) # True
x = {
"a", "b", "c"}
y = {
"f", "e", "d", "c", "b"}
z = x.issubset(y)
print(z) # False
print(x <= y) # False
set.issuperset(set)用于判断集合是不是包含其他集合,如果是则返回 True,否则返回 False。set1 >= set2判断集合是不是包含其他集合,如果是则返回 True,否则返回 False。
x = {
"f", "e", "d", "c", "b", "a"}
y = {
"a", "b", "c"}
z = x.issuperset(y)
print(z) # True
print(x >= y) # True
x = {
"f", "e", "d", "c", "b"}
y = {
"a", "b", "c"}
z = x.issuperset(y)
print(z) # False
print(x >= y) # False
set.isdisjoint(set)用于判断两个集合是不是不相交,如果是返回 True,否则返回 False。
x = {
"f", "e", "d", "c", "b"}
y = {
"a", "b", "c"}
z = x.isdisjoint(y)
print(z) # False
x = {
"f", "e", "d", "m", "g"}
y = {
"a", "b", "c"}
z = x.isdisjoint(y)
print(z) # True
2.1.4 集合的转换
se = set(range(4))
li = list(se)
tu = tuple(se)
print(se, type(se)) # {0, 1, 2, 3} 2.1.5 不可变集合
Python 提供了不能改变元素的集合的实现版本,即不能增加或删除元素,类型名叫frozenset。需要注意的是frozenset仍然可以进行集合操作,只是不能用带有update的方法。
frozenset([iterable])返回一个冻结的集合,冻结后集合不能再添加或删除任何元素。
a = frozenset(range(10)) # 生成一个新的不可变集合
print(a)
# frozenset({0, 1, 2, 3, 4, 5, 6, 7, 8, 9})
b = frozenset('lsgogroup')
print(b)
# frozenset({'g', 's', 'p', 'r', 'u', 'o', 'l'})
2.2 序列
在 Python 中,序列类型包括字符串、列表、元组、集合和字典,这些序列支持一些通用的操作,但比较特殊的是,集合和字典不支持索引、切片、相加和相乘操作。
2.2.1 针对序列的内置函数
list(sub)把一个可迭代对象转换为列表。
a = list()
print(a) # []
b = 'I Love LsgoGroup'
b = list(b)
print(b)
# ['I', ' ', 'L', 'o', 'v', 'e', ' ', 'L', 's', 'g', 'o', 'G', 'r', 'o', 'u', 'p']
c = (1, 1, 2, 3, 5, 8)
c = list(c)
print(c) # [1, 1, 2, 3, 5, 8]
tuple(sub)把一个可迭代对象转换为元组。
a = tuple()
print(a) # ()
b = 'I Love LsgoGroup'
b = tuple(b)
print(b)
# ('I', ' ', 'L', 'o', 'v', 'e', ' ', 'L', 's', 'g', 'o', 'G', 'r', 'o', 'u', 'p')
c = [1, 1, 2, 3, 5, 8]
c = tuple(c)
print(c) # (1, 1, 2, 3, 5, 8)
str(obj)把obj对象转换为字符串
a = 123
a = str(a)
print(a) # 123
len(s)返回对象(字符、列表、元组等)长度或元素个数。s– 对象。
a = list()
print(len(a)) # 0
b = ('I', ' ', 'L', 'o', 'v', 'e', ' ', 'L', 's', 'g', 'o', 'G', 'r', 'o', 'u', 'p')
print(len(b)) # 16
c = 'I Love LsgoGroup'
print(len(c)) # 16
max(sub)返回序列或者参数集合中的最大值
print(max(1, 2, 3, 4, 5)) # 5
print(max([-8, 99, 3, 7, 83])) # 99
print(max('IloveLsgoGroup')) # v
min(sub)返回序列或参数集合中的最小值
print(min(1, 2, 3, 4, 5)) # 1
print(min([-8, 99, 3, 7, 83])) # -8
print(min('IloveLsgoGroup')) # G
sum(iterable[, start=0])返回序列iterable与可选参数start的总和。
print(sum([1, 3, 5, 7, 9])) # 25
print(sum([1, 3, 5, 7, 9], 10)) # 35
print(sum((1, 3, 5, 7, 9))) # 25
print(sum((1, 3, 5, 7, 9), 20)) # 45
sorted(iterable, key=None, reverse=False)对所有可迭代的对象进行排序操作。iterable– 可迭代对象。key– 主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。reverse– 排序规则,reverse = True降序 ,reverse = False升序(默认)。- 返回重新排序的列表。
x = [-8, 99, 3, 7, 83]
print(sorted(x)) # [-8, 3, 7, 83, 99]
print(sorted(x, reverse=True)) # [99, 83, 7, 3, -8]
t = ({
"age": 20, "name": "a"}, {
"age": 25, "name": "b"}, {
"age": 10, "name": "c"})
x = sorted(t, key=lambda a: a["age"])
print(x)
# [{'age': 10, 'name': 'c'}, {'age': 20, 'name': 'a'}, {'age': 25, 'name': 'b'}]
reversed(seq)函数返回一个反转的迭代器。seq– 要转换的序列,可以是 tuple, string, list 或 range。
s = 'lsgogroup'
x = reversed(s)
print(type(x)) # enumerate(sequence, [start=0])
【例子】用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
seasons = ['Spring', 'Summer', 'Fall', 'Winter']
a = list(enumerate(seasons))
print(a)
# [(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')]
b = list(enumerate(seasons, 1))
print(b)
# [(1, 'Spring'), (2, 'Summer'), (3, 'Fall'), (4, 'Winter')]
for i, element in a:
print('{0},{1}'.format(i, element))
# 0,Spring
# 1,Summer
# 2,Fall
# 3,Winter
zip(iter1 [,iter2 [...]])- 用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的对象,这样做的好处是节约了不少的内存。
- 我们可以使用
list()转换来输出列表。 - 如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用
*号操作符,可以将元组解压为列表。
a = [1, 2, 3]
b = [4, 5, 6]
c = [4, 5, 6, 7, 8]
zipped = zip(a, b)
print(zipped) # 三、学习总结
集合的内容在之前学的python教学中接触的不多,还好里面的概念都是以前初高中数学的内容,配合函数名加上例子还是可以理解的,后面的序列感觉是前面方法的总结,相对而言比前两天学到的内容简单。还是好好总结,变成自己掌握的东西
第六天打卡完成,坚持下去~加油ヾ(◍°∇°◍)ノ゙