关于ResNet50的解读
说起ResNet必然要提起He大佬,这真是神一样的存在,这不,不久前又有新的突破RegNet,真是厉害啊。
ResNet开篇之作在此,后面又出了各种变形啥的,ResNeXt,inception-ResNet等等吧,He大佬推荐的tf版本代码在此。keras ResNet50的在此。
总体:
这个网络结构主要是解决加深网络而不能减小loss的问题,如图下:

网络越深越好吗?不是,加一层acc或者其他指标就好了??并不是,既然网络加深了,又难以训练,效果又不好,谁还用深的网络?He大佬的残差学习结构网络大体上比其他模型深,152层,8倍VGG,但复杂性不高,且以ImageNet 测试集3.57%error got first ILSVRC 2015分类任务,同时取得ImageNet 检测,定位,COCO数据集检测,分割的第一。
在keras构建模型中,大多数都是序列化堆叠一些层,但这样有效果吗?
网络结构:
一般定义底层映射H(x),然后堆叠非线性层拟合F(x):=H(x)-x,最初的映射则为F(x)+x,于是我们认为优化后者即F(x)+x,比无参考的前者H(x)更容易【这是直接翻译的,具体啥意思我还没转过来弯】下面就是这个的building block,即有名的identity mapping【恒等映射】

直接将x加过来既没有增加参数,也没有增加复杂度。仍旧可以采用SGD优化器就行反向传播。
对于每层堆叠都采用残差学习模块,正如上图所言,有两层,F=W2*theta(W1*x),theta是激活函数relu,为简化计,忽略偏置。
F+x就是直接相连,每个元素对应相加,然后再用relu激活。如果F和x的维度不同,可采用线性映射Ws,Ws也可为方阵,如下:
y=F+Ws*x,作者证实,这种简单的恒等映射对于处理图1问题是足够的,而且是经济的【划算】。残差结构也不是一成不变的,也可以是其他形式,比如下面:2层或3层都是可以的,或者更多层,但是只有一层【即y=W1*x+x】没有发现优势。

在卷积层和全连接层都是可用的。
下面看看keras版本的代码:其实我之前就看过了这个版本的代码了
1.恒等映射部分
def _shortcut(input, residual):
"""Adds a shortcut between input and residual block and merges them with "sum"
"""
# Expand channels of shortcut to match residual.
# Stride appropriately to match residual (width, height)
# Should be int if network architecture is correctly configured.
input_shape = K.int_shape(input)
residual_shape = K.int_shape(residual)
stride_width = int(round(input_shape[ROW_AXIS] / residual_shape[ROW_AXIS]))
stride_height = int(round(input_shape[COL_AXIS] / residual_shape[COL_AXIS]))
equal_channels = input_shape[CHANNEL_AXIS] == residual_shape[CHANNEL_AXIS]
shortcut = input
# 1 X 1 conv if shape is different. Else identity.
if stride_width > 1 or stride_height > 1 or not equal_channels:
shortcut = Conv2D(filters=residual_shape[CHANNEL_AXIS],
kernel_size=(1, 1),
strides=(stride_width, stride_height),
padding="valid",
kernel_initializer="he_normal",
kernel_regularizer=l2(0.0001))(input)
return add([shortcut, residual])如果不同width或height及channel,那么采用卷积使得结果相同,如果相同就是简单的相加(add)
下面验证一下不同时的情况:这里有个潜在的约束,就是residual是经过卷积后的,HW肯定比x要小(相同的情况则是上句的直接相加)至于是不是整数倍,这个不一定,因为上面的代码其实是固定了核的大小,如果不固定的话会更加灵活,那就要考虑余数与核大小的关系了。视input1为x,input2为residual。
>>> input1
>>> input2
>>> _shortcut(input1,input2)
Traceback (most recent call last):
File "", line 1, in
_shortcut(input1,input2)
File "D:\python36\new\keras-resnet\resnet.py", line 92, in _shortcut
return add([shortcut, residual])
File "D:\python36\lib\site-packages\keras\layers\merge.py", line 555, in add
return Add(**kwargs)(inputs)
File "D:\python36\lib\site-packages\keras\engine\base_layer.py", line 425, in __call__
self.build(unpack_singleton(input_shapes))
File "D:\python36\lib\site-packages\keras\layers\merge.py", line 91, in build
shape)
File "D:\python36\lib\site-packages\keras\layers\merge.py", line 61, in _compute_elemwise_op_output_shape
str(shape1) + ' ' + str(shape2))
ValueError: Operands could not be broadcast together with shapes (6, 16, 3) (5, 16, 3) 考虑卷积核大小可以改变,那么可以直接采用下面的卷积
>>> Conv2D(filters=3,kernel_size=(2,2),strides=(3,2))(input1)
>>> input1_=Conv2D(filters=3,kernel_size=(2,2),strides=(3,2))(input1)
>>> _shortcut(input1_,input2)
2.关于残差模块,下面是bottleneck,也就是采用了3层卷积
def bottleneck(filters, init_strides=(1, 1), is_first_block_of_first_layer=False):
"""Bottleneck architecture for > 34 layer resnet.
Follows improved proposed scheme in http://arxiv.org/pdf/1603.05027v2.pdf
Returns:
A final conv layer of filters * 4
"""
def f(input):
if is_first_block_of_first_layer:
# don't repeat bn->relu since we just did bn->relu->maxpool
conv_1_1 = Conv2D(filters=filters, kernel_size=(1, 1),
strides=init_strides,
padding="same",
kernel_initializer="he_normal",
kernel_regularizer=l2(1e-4))(input)
else:
conv_1_1 = _bn_relu_conv(filters=filters, kernel_size=(1, 1),
strides=init_strides)(input)
conv_3_3 = _bn_relu_conv(filters=filters, kernel_size=(3, 3))(conv_1_1)
residual = _bn_relu_conv(filters=filters * 4, kernel_size=(1, 1))(conv_3_3)
return _shortcut(input, residual)
return f上面所指的第一层是
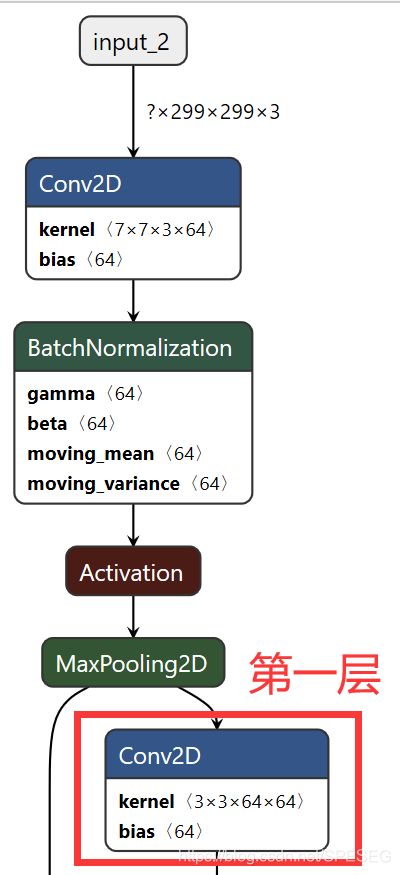
因为代码作者采用的是循环的操作,这个第一层就是开始循环的第一层。
he大佬的2层卷积即basic_block中,当维度不同时可以采用补零或者上面所提的投影【代码作者采用的是卷积,如下方框】


步长为2.至于为何为2,不是1,两个大佬都没说。
he大佬在卷积后激活前采用BN层,根据某个实践,没有用dropout,并没有解释或者对照试验。
下面的34层恰好就是repetition中的3463
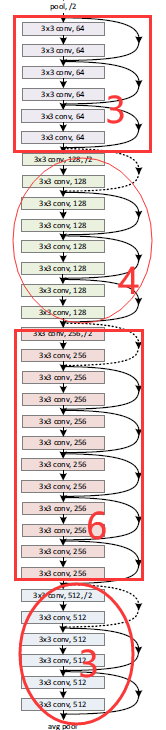
resnet34=ResnetBuilder.build((299,299,3),20,basic_block, [3, 4, 6, 3])3关于代码中细节
可能不同的tf版本运行结果报错,请直接修改数据格式,将判断是不是tf后台那里改了就好。
另外,随意增加循环层或者说resnet层数其实并不能提高acc或其他指标,可见我的具体实践。
最后的avg其实就gap
另外有相关问题可以加入QQ群讨论,不设微信群
QQ群:868373192
语音图像视频推荐深度-学习群