Python爬虫数据抽取(三):正则表达式
目录
- 1. 为什么要使用正则表达式?
- 2. 什么是正则表达式?
- 3. re模块操作
- 4. 匹配单个字符
- 5. 匹配多个字符
- 6. 匹配分组
- 7. re模块的高级用法
-
- 7.1 使用search()方法进行匹配
- 7.2 使用findall()方法进行匹配
- 7.3 替换字符串
- 7.4 使用正则表达式分割字符串
1. 为什么要使用正则表达式?
首先,大家来看一个例子。一个文本文件里面存储了一些市场职位信息,格式如下所示:
Python3 高级开发工程师 上海互教教育科技有限公司上海-浦东新区2万/月02-18满员
测试开发工程师(C++/python) 上海墨鹍数码科技有限公司上海-浦东新区2.5万/每月02-18未满员
Python3 开发工程师 上海德拓信息技术股份有限公司上海-徐汇区1.3万/每月02-18剩余11人
测试开发工程师(Python) 赫里普(上海)信息科技有限公司上海-浦东新区1.1万/每月02-18剩余5人
Python高级开发工程师 上海行动教育科技股份有限公司上海-闵行区2.8万/月02-18剩余255人
python开发工程师 上海优似腾软件开发有限公司上海-浦东新区2.5万/每月02-18满员
现在,我们需要编写一个程序,从这些文本里面抓取所有职位的薪资。获取结果如下所示:
2
2.5
1.3
1.1
2.8
2.5
怎么做?大家可以先自己思考一下。这是典型的字符串处理。分析这里面的规律,可以发现,薪资的数字后面都有关键字万/月或者万/每月。根据我们学过的知识,我们不难写出下面的代码:
html_str = """
Python3 高级开发工程师 上海互教教育科技有限公司上海-浦东新区2万/月02-18满员
测试开发工程师(C++/python) 上海墨鹍数码科技有限公司上海-浦东新区2.5万/每月02-18未满员
Python3 开发工程师 上海德拓信息技术股份有限公司上海-徐汇区1.3万/每月02-18剩余11人
测试开发工程师(Python) 赫里普(上海)信息科技有限公司上海-浦东新区1.1万/每月02-18剩余5人
Python高级开发工程师 上海行动教育科技股份有限公司上海-闵行区2.8万/月02-18剩余255人
python开发工程师 上海优似腾软件开发有限公司上海-浦东新区2.5万/每月02-18满员
"""
# 将字符串html_str中每一行的数据提取出来存入到一个列表中
position_info_list = html_str.splitlines()
for position_info in position_info_list: # 遍历
if position_info: # 判断是否有数据
# 查找万/月或者是万/每月的索引
idx = position_info.find("万/月") if position_info.find("万/月") != -1 else position_info.find("万/每月")
end_pos = idx # 记录结束位置
if idx == -1:
continue # 上面两种都没找到
find_start = idx - 1 # 记录万字前的位置
while position_info[find_start].isdigit() or position_info[find_start] == ".":
find_start -= 1
start_pos = find_start + 1 # 开始位置
print(position_info[start_pos: end_pos]) # 切片获取薪资
运行一下,发现完全可以。如图所示:

在你高兴完之后,我们再看看写的代码。怎么样?太麻烦了,是不是。为了从每行获取薪资对应的数字,我们可是写了不少行代码。这种从字符串中搜索出某种特征的子串有没有更简单的方法呢?解决方案就是我们今天要介绍的正则表达式。如果我们使用正则表达式,代码可以这样:
import re
html_str = """
Python3 高级开发工程师 上海互教教育科技有限公司上海-浦东新区2万/月02-18满员
测试开发工程师(C++/python) 上海墨鹍数码科技有限公司上海-浦东新区2.5万/每月02-18未满员
Python3 开发工程师 上海德拓信息技术股份有限公司上海-徐汇区1.3万/每月02-18剩余11人
测试开发工程师(Python) 赫里普(上海)信息科技有限公司上海-浦东新区1.1万/每月02-18剩余5人
Python高级开发工程师 上海行动教育科技股份有限公司上海-闵行区2.8万/月02-18剩余255人
python开发工程师 上海优似腾软件开发有限公司上海-浦东新区2.5万/每月02-18满员
"""
salary_list = re.findall(r"([\d.]+)万/每?月", html_str)
for salary in salary_list:
print(salary)
运行一下看看,结果是一样的。但是代码却简单多了。从上面的例子可以看出,用正则表达式关键的地方在于如何写出正确的表达式语法。正则表达式非常强大,语法非常复杂,如果你英文阅读能力还可以,那太好了,点击这里,参考Python官方文档里面的描述 。具体的使用细节包括语法都在里面。本文会给大家介绍一些常见的正则表达式语法。
2. 什么是正则表达式?
在处理字符串时,经常会有查找符合某些复杂规则的字符串的需求。正则表达式就是用于描述这些规则的工具。换句话说,正则表达式就是记录文本规则的代码。对于接触过DOS/终端的用户来说,如果想匹配当前文件夹下所有的文本文件,可以输入dir *.txt/ls *.txt命令,按.txt文件将会被列出来。这里的*.txt即可理解为一个简单的正则表达式。
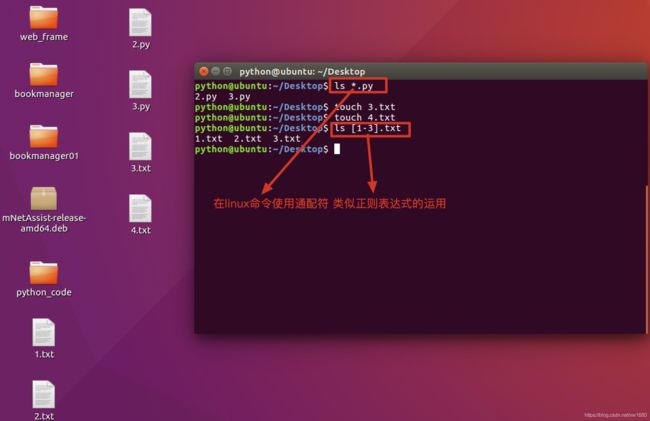
在数据库中使用正则表达式,如图所示:

3. re模块操作
Python提供了re模块,用于实现正则表达式的操作。在实现时,可以使用re模块提供的方法search()、 match()、findall()等进行字符串处理,也可以先使用re模块的compile()方法将模式字符串转换为正则表达式对象,然后再使用该正则表达式对象的相关方法来操作字符串。re模块在使用时,需要先应用import语句引入,具体代码如下:
import re
这里因为我们还没有学习匹配的规则,所以先学习一下match方法,其他的方法在本文末尾讲解。match()方法用于从字符串的开始处进行匹配,如果在起始位置匹配成功,则返回Match对象,否则返回None,语法格式如下:
re.match(pattern, string, [flags] )
参数说明:
1. pattern:表示模式字符串,由要匹配的正则表达式转换而来。
2. string:表示要匹配的字符串。
3. flags:可选参数,表示标志位,用于控制匹配方式,如是否区分字母大小写。
常用的flags如下表所示:
| 标志 | 说明 |
|---|---|
| A 或ASCII | 对于\w、\W、\b、\B、\d、\D、\s和\S只进行ASCII匹配(仅适用于Python 3.x) |
| I或IGNORECASE | 执行不区分字母大小写的匹配 |
| M或MULTILINE | 将^和$用于包括整个字符串的开始和结尾的每一行(默认情况下,仅适用于整个字符串的开始和结尾处) |
| S或DOTALL | 使用(.)字符匹配所有字符,包括换行符 |
| X或VERBOSE | 忽略模式字符串中未转义的空格和注释 |
例如,匹配字符串是否以amo_开头,不区分字母大小写,代码如下:
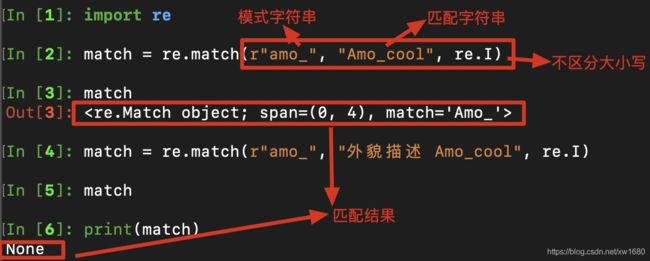
从上面的执行结果中可以看出,字符串Amo_cool是以amo_开头,所以返回一个Match对象,而字符串外貌描述 Amo_ cool不是以amo_开头,将返回None。这是因为match()方法从字符串的开始位置开始匹配,当第一个字母不符合条件时,则不再进行匹配,直接返回None。Match对象中包含了匹配值的位置和匹配数据。其中,要获取匹配值的起始位置可以使用Match对象的start() 方法 要获取匹配值的结束位置可以使用end()方法 通过span()方法可以返回匹配位置的元组 通过string属性可以获取要匹配的字符串。例如下面的代码:
import re
pattern = r"amo_" # 模式字符串
str1 = "Amo_cool amo_cool" # 要匹配的字符串
match = re.match(pattern, str1, re.I) # 匹配字符串 不区分大小写
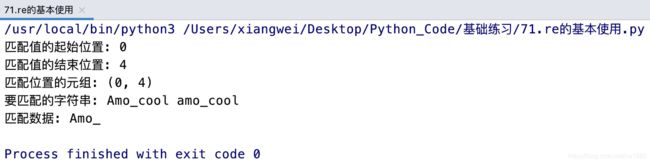
print(f"匹配值的起始位置: {match.start()}")
print(f"匹配值的结束位置: {match.end()}")
print(f"匹配位置的元组: {match.span()}")
print(f"要匹配的字符串: {match.string}")
print(f"匹配数据: {match.group()}"
运行结果如图所示:
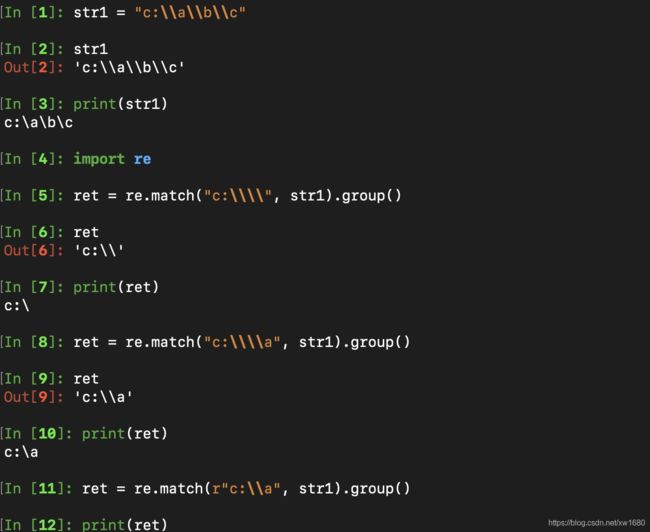
Python中字符串前面加上r表示原生字符串,与大多数编程语言相同,正则表达式里使用\作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符\,那么使用编程语言表示的正则表达式里将需要4个反斜杠\:前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。Python里的原生字符串很好地解决了这个问题,有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。如图所示:
4. 匹配单个字符
在上一小节中,了解到通过re模块能够完成使用正则表达式来匹配字符串。本小节,将要讲解正则表达式的单字符匹配,具体的规则,如下所示:
| 实例 | 描述 |
|---|---|
| . | 匹配除"\n"之外的任何单个字符。要匹配包括"\n"在内的任何字符,请使用"[.\n]"模式。 |
| \d | 匹配一个数字字符。等价于 [0-9]。 |
| \D | 匹配一个非数字字符。等价于 [^0-9]。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于[ \f\n\r\t\v]。 |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
| \w | 匹配包括下划线的任何单词字符。等价于"[A-Za-z0-9_]"。 |
| \W | 匹配任何非单词字符。等价于"[^A-Za-z0-9_]"。 |
| […] | 用来表示一组字符,单独列出:[amk] 匹配 ‘a’,‘m’或’k’ |
| [^…] | 不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。 |
| ^ | 匹配字符串的开头 |
| $ | 匹配字符串的结尾 |
例子如下:
5. 匹配多个字符
匹配多个字符的相关格式:
| 实例 | 描述 |
|---|---|
| re* | 匹配0个或多个的表达式 。 |
| re+ | 匹配1个或多个的表达式。 |
| re? | 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式。 |
| re{n} | 匹配n个前面表达式。例如,o{2}不能匹配Bob中的o,但是能匹配food中的两个o。 |
| re{n,} | 精确匹配n个前面表达式。例如,o{2,}不能匹配Bob中的o,但能匹配foooood中的所有o。o{1,}等价于o+。o{0,}则等价于o*。 |
| re{n,m} | 匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式 |
例子如下:
6. 匹配分组
| 实例 | 描述 |
|---|---|
| a|b | 匹配a或b |
| (re) | 匹配括号内的表达式,也表示一个组 |
| \num | 引用分组num匹配到的字符串 |
| (?P |
分组起别名 |
| (?P=name) | 引用别名为name分组匹配到的字符串 |
练习1:匹配出0-100之间的数字
result = re.match(r"[1-9]?\d$|100", "70").group()
练习2:匹配出163、126、qq、sina邮箱
要求:可使用英文小写 数字 下划线,下划线不能在首尾且@符号之前有4到16位字符
![]()
result = re.match(r"^[a-z0-9][a-z0-9_]{2,14}[a-z0-9]@(163|126|qq|sina)\.com$", "[email protected]").group()
练习3:匹配出amo666
import re
str1 = "amo666"
pattern1 = r"<([a-zA-Z]*)><([a-zA-Z]*)>.*"
match_obj1 = re.match(pattern1, str1)
print(match_obj1.group())
pattern2 = r"<(?P[a-zA-Z]*)><(?P[a-zA-Z]*)>.*"
match_obj2 = re.match(pattern2, str1)
print(match_obj2.group())
执行结果如下:
amo666
amo666
7. re模块的高级用法
7.1 使用search()方法进行匹配
search()方法用于在整个字符串中搜索第一个匹配的值, 如果匹配成功,则返回Match对象,否则返回None,语法格式如下:
re. search(pattern, string, [flags])
参数说明:
- pattern:表示模式字符串,由要匹配的正则表达式转换而来。
- string:表示要匹配的字符串。
- flags:可选参数,表示标志位,用于控制匹配方式,如是否区分字母大小写。
例如,搜索第一个以amo_开头的字符串,不区分字母大小写,代码如下:
import re
match_obj1 = re.search(r"amo_\w+", "Amo_SHOP amo_shop", re.I)
print(match_obj1)
match_obj2 = re.search(r"amo_\w+", "项目名称Amo_SHOP amo_shop", re.I)
print(match_obj2)
执行结果如下:

从上面的运行结果中可以看出,search()方法不仅仅是在字符串的起始位置搜索,其他位置有符合的匹配也可以。
7.2 使用findall()方法进行匹配
findall()方法用于在整个字符串中搜索所有符合正则表达式的字符串,并以列表的形式返回。如果匹配成功,则返回包含匹配结构的列表,否则返回空列表。其语法格式如下:
re. findall(pattern, string, [flags])
参数说明:
- pattern:表示模式字符串,由要匹配的正则表达式转换而来。
- string:表示要匹配的字符串。
- flags:可选参数,表示标志位,用于控制匹配方式,如是否区分字母大小写。
例如,搜索以amo_开头的字符串,不区分字母大小写,代码如下:
import re
result1 = re.findall(r"amo_\w+", "Amo_SHOP amo_shop", re.I)
print(result1)
result2 = re.findall(r"amo_\w+", "项目名称Amo_SHOP amo_shop")
print(result2)
执行结果如下:
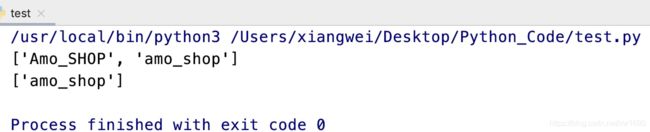
如果在指定的模式字符串中,包含分组,则返回与分组匹配的文本列表。例如:
import re
result1 = re.findall(r"[1-9]{1,3}(\.[0-9]{1,3}){3}", "127.0.0.1 192.168.31.157")
print(result1)
上面的代码的执行结果如下:
['.1', '.157']
从上面的结果中可以看出,并没有得到匹配的IP地址,这是因为在模式字符串中出现了分组,所以得到的结果是根据分组进行匹配的结果,即(\.[0一9]{1,3})匹配的结果。如果想获取整个模式字符串的匹配,可以将整个模式字符串使用一对小括号进行分组,然后在获取结果时,只取返回值列表的每个元素(是一个元组)的第1个元素。代码如下:
import re
str1 = "127.0.0.1 192.168.31.157"
result1 = re.findall(r"([1-9]{1,3}(\.[0-9]{1,3}){3})", str1)
for item in result1:
print(item[0])
执行结果如下:
127.0.0.1
192.168.31.157
7.3 替换字符串
sub()方法用于实现字符串替换,语法格式如下:
re. sub( pattern, repl, string, count, flags)
参数说明:
- pattern:表示模式字符串,由要匹配的正则表达式转换而来。
- repl: 表示替换的字符串。
- string:表示要被查找替换的原始字符串。
- count:可选参数,表示模式匹配后替换的最大次数,默认值为0,表示替换所有的匹配。
- flags:可选参数,表示标志位,用于控制匹配方式,如是否区分字母大小写。
例如,隐藏中奖信息中的手机号码,代码如下:
import re
pattern = r"1[34578]\d{9}"
str1 = "中奖号码为: 84978981 联系电话为: 13611111111"
result = re.sub(pattern, "1XXXXXXXXXX", str1)
print(result)
执行结果如下:
中奖号码为: 84978981 联系电话为: 1XXXXXXXXXX
7.4 使用正则表达式分割字符串
split()方法用于实现根据正则表达式分割字符串,并以列表的形式返回,其作用与字符串对象的split()方法类似,所不同的就是分割字符由模式字符串指定。语法格式如下:
re.split(pattern, string, [maxsplit], [flags])
参数说明:
- pattern:表示模式字符串,由要匹配的正则表达式转换而来。
- string:表示要匹配的字符串。
- maxsplit:可选参数,表示最大的拆分次数。
- flags:可选参数,表示标志位,用于控制匹配方式,如是否区分字母大小写。
例如,从给定的URL地址中提取出请求地址和各个参数,代码如下:
import re
pattern = r"[?|&]"
url = "https://study.163.com/courses-search?keyword=python&username=amo"
result = re.split(pattern, url)
print(result)
执行结果如下:
['https://study.163.com/courses-search', 'keyword=python', 'username=amo']
关于正则表达式的贪婪和非贪婪 可以点击这里正则表达式的贪婪模式与非贪婪模式参考。