python 数据处理(以Pandas为主)
python 数据处理:(以Pandas为主)
-
- 读取数据
- 添加、修改数据
-
- ①添加数据
- ②修改dataframe的列名字
- ③将某一列数据转换为自己想要表达的字段
- ④填充空值
- 删除数据
-
- ①删除指定一行的数据
- ②删除指定一列的数据
- ③删除具有空值的数据
- ③删除具有重复值的数据
- 合并数据
-
- ①按列合并数据
- ②按行合并
- 转换数据格式(转换某一列的类型)
-
- ①int转float
- ②str转datetime
- 查看数据
-
- ①查看dataframe中关于数值型数据的描述
- ②查看dataframe的属性描述,dataframe有多少行,各列数据的属性,占的内存是多少等
- ③初略的显示dataframe前几行
- ④统计某一个列中各个值出现的次数:value_counts
- ⑤快速了解dataframe有几行几列
- 保存数据
-
- ①dataframe转csv
- ②dataframe转json(转的类型有点多,我贴个链接,大家有兴趣的可以去了解一下)
读取数据

import pandas as pd
df = pd.read_csv('目标csv文件所在的绝对路径或者相对路径') //其他的读取语法类似,df是自取的名字,pd.read_csv()就是把目标csv文件转换为dataframe格式。
添加、修改数据
①添加数据
import pandas as pd
from numpy import nan as NaN
df1 = pd.DataFrame([['Snow','M',22],['Tyrion','M',32],['Sansa','F',18],['Arya','F',14]], columns=['name','gender','age'])

print("----------在最后新增一列---------------")
print("-------案例1----------")
# 在数据框最后加上score一列,元素值分别为:80,98,67,90
df1['score']=[80,98,67,90] # 增加列的元素个数要跟原数据列的个数一样

print("-------案例2----------")
print("---------在指定位置新增列:用insert()--------")
# 在gender后面加一列城市
# 在具体某个位置插入一列可以用insert的方法
# 语法格式:列表.insert(index, obj)
# index --->对象 obj 需要插入的索引位置。
# obj ---> 要插入列表中的对象(列名)
col_name=df1.columns.tolist() # 将数据框的列名全部提取出来存放在列表里
col_name.insert(2,'city') # 在列索引为2的位置插入一列,列名为:city,刚插入时不会有值,整列都是NaN
col_name.insert(col_name.index('age'),'education') # 在age列前面插入一列,列名叫education
df1=df1.reindex(columns=col_name) # DataFrame.reindex() 对原行/列索引重新构建索引值
df1['city'] = ['北京','山西','湖北','澳门'] # 给city列赋值
df1['education'] =['小学','初中','高中','大学']

print("----------新增行---------------")
# 重要!!先创建一个DataFrame,用来增加进数据框的最后一行
new_col=pd.DataFrame({'name':'lisa',
'gender':'F',
'city':'广州',
'education':'幼儿园',
'age':5,
'score':100},
index=[1]) # 自定义索引为:1 ,这里也可以不设置index
print("-------在原数据框df1最后一行新增一行,用append方法------------")
df1=df1.append(new_col,ignore_index=True) # ignore_index=True,表示不按原来的索引,从0开始自动递增
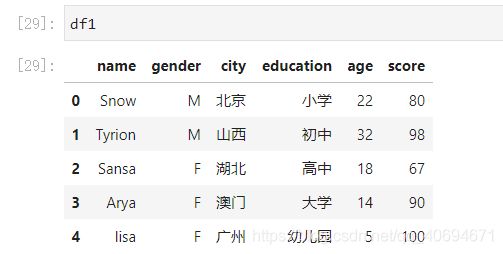
②修改dataframe的列名字
df1.rename(columns={'score':'mark'},inplace=True)

③将某一列数据转换为自己想要表达的字段
city_mapping = {
"北京": "Beijing",
"山西": "ShanXi",
"湖北": "HuBi",
"澳门": "AoMen",
"广州": "GuangZhou"}
df1['city'] = df1['city'].map(city_mapping)

④填充空值
看情况,如果不想过滤(删除)某些数据,我们可以选择使用fillna()方法填充空值,这里,我使用数值’0’替代NaN,来填充DataFrame。具体填充什么视情况而定,一般填充空值的用0或者该列的平均值来填充的用法比较多。
①先给原先的df1添加两行数据,数据里含有空值
#print("----------新增行---------------")
new = pd.DataFrame({'name':'lisi',
'gender':'M',
'city':'Beijing',
'education':'初中',
'age':12,
'mark':NaN},
index=[1])
#print("-------在原数据框df1最后一行新增一行,用append方法------------")
df1 = df1.append(new,ignore_index=True) # ignore_index=True,表示不按原来的索引,从0开始自动递增
#print("----------新增行---------------")
new1 = pd.DataFrame({'name':'lisi',
'gender':'M',
'city':'Beijing',
'education':'初中',
'age':12,
'mark':NaN},
index=[1])
df1 = df1.append(new1,ignore_index=True) # ignore_index=True,表示不按原来的索引,从0开始自动递增

②填充空值
df1 = df1.fillna(0.0)

删除数据
①删除指定一行的数据
df1 = df1.drop(2,axis=0,inplace=False) #删除第3行

②删除指定一列的数据
df1 = df1.drop('education',axis=1,inplace=False) #删除education这一列

③删除具有空值的数据
df1.dropna(subset=['mark'],how='all',inplace=True) #删除mark列中具有空值那些行

③删除具有重复值的数据

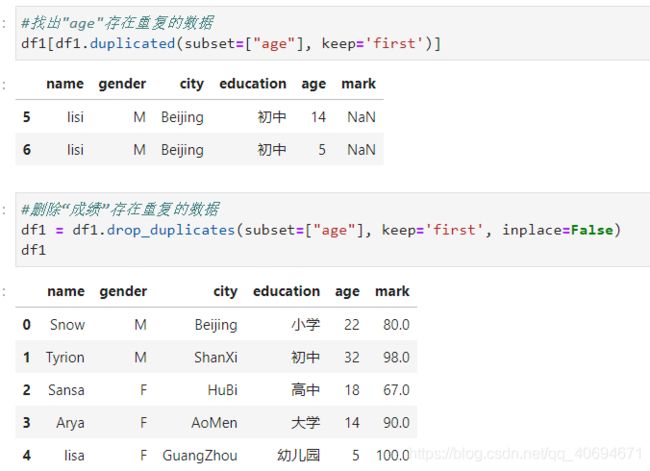
#找出"age"存在重复的数据
df1[df1.duplicated(subset=["age"], keep='first')]
#删除“成绩”存在重复的数据
df1 = df1.drop_duplicates(subset=["age"], keep='first', inplace=False)
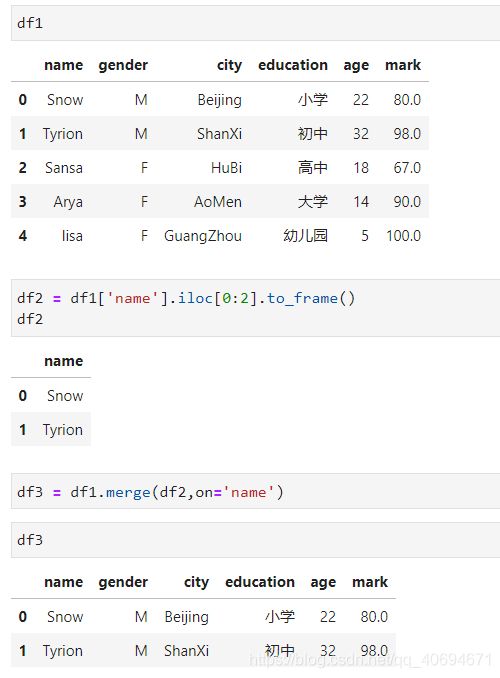
合并数据
①按列合并数据
②按行合并

转换数据格式(转换某一列的类型)
有时候,需要自己调整数据表中某一列的数据类型,有可能是int转float,也有可能是字符串转时间类型。具体需要转什么类型,是情况而定,在这里我就介绍两个比较常用的案例。
①int转float

②str转datetime
查看数据
①查看dataframe中关于数值型数据的描述
df_name.describe()
结果的索引将包括计数,平均值,标准差,最小值,最大值以及较低的百分位数和50。默认情况下,较低的百分位数为25,较高的百分位数为75。50百分位数与中位数相同。

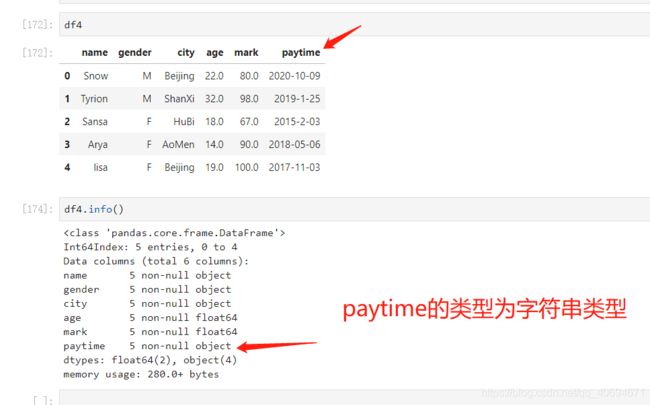
②查看dataframe的属性描述,dataframe有多少行,各列数据的属性,占的内存是多少等
name.info()
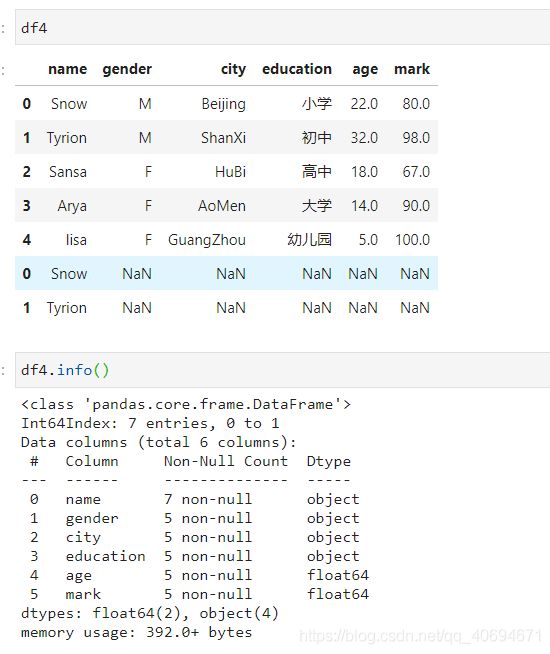
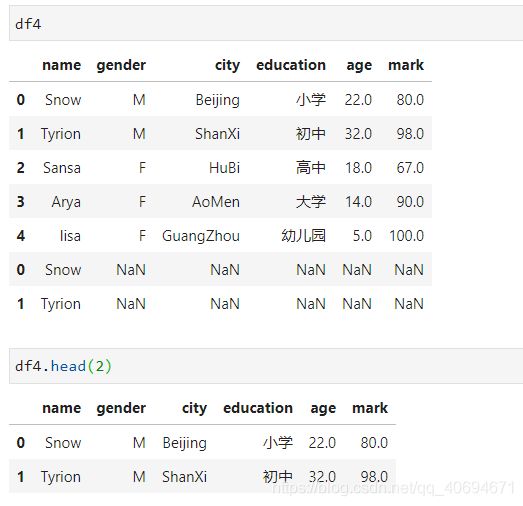
③初略的显示dataframe前几行
有时候dataframe的行数太大,显示全部需要非常多的时间,一般显示前几行就够了。
name.head(x) # 不输入x则表示默认显示前5行
④统计某一个列中各个值出现的次数:value_counts

⑤快速了解dataframe有几行几列

保存数据
将最终的处理好的dataframe转换为文件形式保存。这里我介绍两个个常用的形式
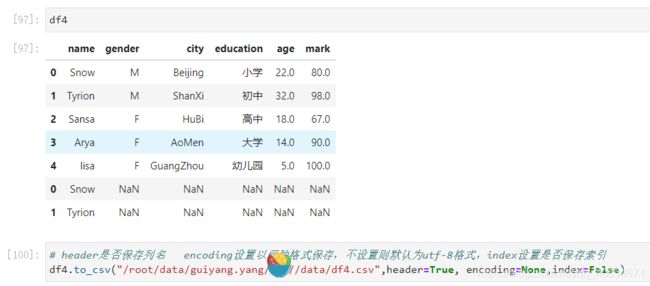
①dataframe转csv
# header是否保存列名 encoding设置以何种格式保存,不设置则默认为utf-8格式,index设置是否保存索引
dataframe_name.to_csv("路径+名字",header=True, encoding=None,index=False)

②dataframe转json(转的类型有点多,我贴个链接,大家有兴趣的可以去了解一下)
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.to_json.html
如果各位路过朋友觉得对自己有帮助的话,麻烦关注一下小编或者点个赞再走哦~