想看游戏视频吗?点这,这里应有尽有
原标题:运用python爬虫下载好看视频
前言:
之所以标题上写着游戏视频,有两个原因:1.是希望能吸引读者的眼球,但愿是我希望的吧!2.是我这次下载的视频也是有关游戏的。

文章目录
-
-
- 原标题:运用python爬虫下载好看视频
-
- 1.完成这个项目需要的模块
-
- 1.1 必须要模块
- 1.2 其他模块
- 2. 实现过程
- 3.最终代码和运行结果:
- 4.总结
-
1.完成这个项目需要的模块
1.1 必须要模块
既然是爬虫就少不了urllib模块,当然也少不了解析模块,这里我用的是bs4,
这两个模块都是第三方模块,需要额外下载。
1.2 其他模块
这里我还用到了json模块,主要是用来处理json格式的数据的。
另外,我也用到了sys和time模块,用来制作一个进度条,使最后结果更加fashion。
2. 实现过程
首先,我们要来到这个网址:好看视频
通过输入一个视频主题,我们可以搜索得到下面结果:(我输入的是 和平精英,因为我也是一个和平精英的游戏迷)

通过对上面的那个网址进行分析,我们可以发现,
https://haokan.baidu.com/videoui/page/search?query=%E5%92%8C%E5%B9%B3%E7%B2%BE%E8%8B%B1
我们只需要改变 query后面的视频名称,就可以匹配到相应的视频了。
现在,我们要做的就是得到这些视频的链接和名称了。
我们可以按电脑键盘上的F12建,也可以鼠标右键,然后在弹出来的窗口上点击检查。
然后,我们就可以看到下面结果了。
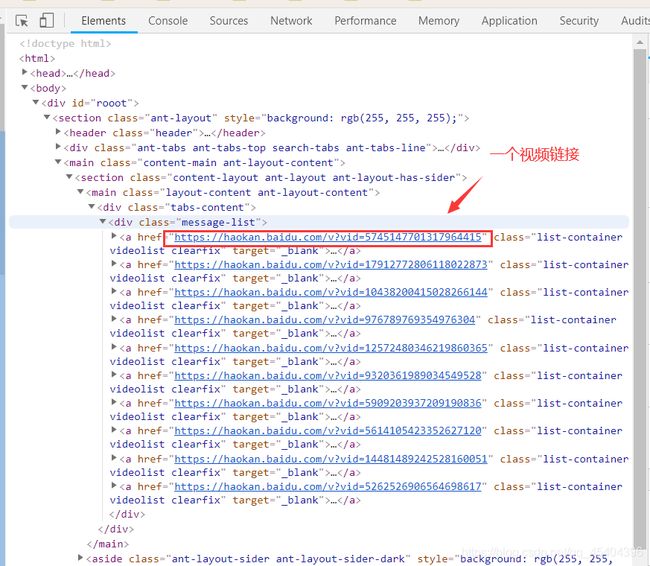
只不过这个视频链接好像是动态加载出来,根本爬不到,我们查看一下网页源代码就知道了。尽管这样,我们继续往这个界面下看,可以发现,这里有这些视频的链接和名称,但是是一个json数据,并且还是进行了编码的。

我们只需得到这些数据,并解码即可。
开始我是直接这样
text.read().decode()
的,可是,这样根本不能解码;于是,我就这样
text=response.read().decode('unicode-escape')
,虽然解了码,但是有警告。

查了一下资料,提示’/'是一个无效的转义字符。
我想了想,不如先解码,然后将‘/’替换,再编码,再解码即可。
text=response.read().decode()
text=text.replace('\/','/')
text=text.encode('utf-8').decode('unicode-escape')
这样,我们就可以得到这些链接和名称了。
我们选择其中一个视频进行播放。

可以发现这个视频的下载链接在一个 video标签下
这里我定义了一个方法,用来下载视频。
def Downlad(url,name): # 定义一个方法,通过传进来的参数url下载视频
response=request.urlopen(url=url)
text=response.read().decode('utf-8')
src=text[text.find('')]
url=src[src.find('src=')+4:src.find('>')]
request.urlretrieve(url=url,filename='./{}.mp4'.format(name))
传入第一个参数进入这个视频的链接,第二个参数是给下载的视频起的名称。
3.最终代码和运行结果:
from urllib import request
from urllib import parse
from bs4 import BeautifulSoup
import json
import time
import sys
def Time_1(): # 进度条函数
for i in range(1,101):
sys.stdout.write('\r')
sys.stdout.write('{0}%|{1}{2}'.format(i,int((i%101)/2)*'-','>'))
sys.stdout.flush()
time.sleep(0.05)
sys.stdout.write('\n')
def Downlad(url,name): # 定义一个方法,通过传进来的参数url下载视频
response=request.urlopen(url=url)
text=response.read().decode('utf-8')
src=text[text.find('')]
url=src[src.find('src=')+4:src.find('>')]
request.urlretrieve(url=url,filename='./{}.mp4'.format(name))
if __name__ == '__main__':
name=input('请输入你想看的视频名:')
query=parse.urlencode({'query':name})
url='https://haokan.baidu.com/videoui/page/search?{}'.format(query)
headers={'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3756.400 QQBrowser/10.5.4039.400'}
response=request.Request(url=url,headers=headers)
response=request.urlopen(response)
text=response.read().decode()
text=text.replace('\/','/')
text=text.encode('utf-8').decode('unicode-escape')
soup=BeautifulSoup(text,'lxml')
str1=str(soup.select('script#_page_data')[0])
str2=str1[str1.find('window.__PRELOADED_STATE__ =')+len('window.__PRELOADED_STATE__ ='):str1.rfind(';')]
dict1=json.loads(str2)
for i in range(len(dict1['list'])):
print('-->【{}】'.format(dict1['list'][i]['title']))
Downlad(url=dict1['list'][i]['url'],name=i+1)
Time_1()
print('所有视频下载完毕!')
运行结果:

运行完毕之后,你会发现在同一个文件夹下面多出几个.mp4文件,这些就是下载的视频了,就可以观看了。



4.总结
这个程序代码还可以更新一下,比如做一个ip代理池,这样就不会被封ip了吧!如果大家觉得我这个做的还可以,记得点赞;没给我点赞也可以,我会继续努力的。