Python操作MySQL之SQLAlchemy
概述
SQLAlchemy是Python编程语言下的一款ORM框架,该框架建立在数据库API之上,使用关系对象映射进行数据库操作,简言之便是:将对象转换成SQL,然后使用数据API执行SQL并获取执行结果。
ORM技术
数据库表是一个二维表,包含多行多列。把一个表的内容用Python的数据结构表示出来的话,可以用一个list表示多行,list的每一个元素是tuple,表示一行记录。比如,包含id和name的user表:
[
('1', 'Michael'),
('2', 'Bob'),
('3', 'Adam')
]Python的DB-API返回的数据结构就是像上面这样表示的。
但是用tuple表示一行很难看出表的结构。如果把一个tuple用class实例来表示,就可以更容易地看出表的结构来:
class User(object):
def __init__(self, id, name):
self.id = id
self.name = name
[
User('1', 'Michael'),
User('2', 'Bob'),
User('3', 'Adam')
]上述就是ORM技术:Object-Relational Mapping,把关系数据库的表结构映射到对象上。
SQLAlchemy
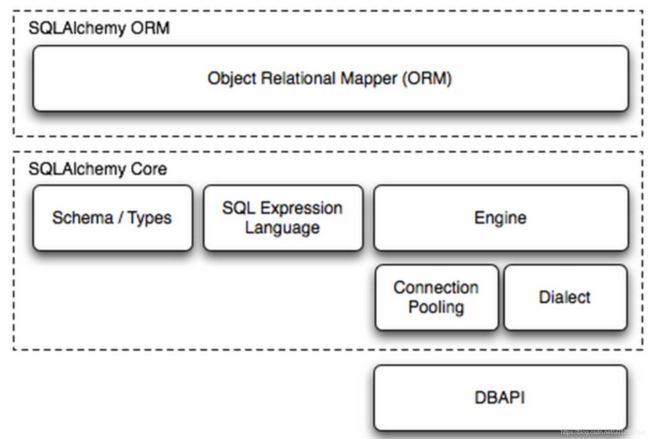
SQLAlchemy-初始化连接
SQLAlchemy本身无法操作数据库,其必须依赖pymsql等第三方插件,Dialect用于和数据API进行交流,根据配置文件的不同调用不同的数据库API,从而实现对数据库的操作。
# pymysql
DB_CONNECT_STRING = 'mysql+pymysql://root:[email protected]:3306/db_stable'
# MySQL-Python
DB_CONNECT_STRING = 'mysql+mysqldb://root:[email protected]:3306/db_stable'
# MySQL-Connector
DB_CONNECT_STRING = 'mysql+mysqlconnector://root:[email protected]:3306/db_stable'
create_engine()返回一个Engine的实例,并且它表示通过数据库语法处理细节的核心接口,在这种情况下,数据库语法将会被解释成python的类方法。
echo参数为True时,会显示每条执行的SQL语句,可以关闭。
from sqlalchemy import create_engine
# 初始化数据库连接
DB_CONNECT_STRING = 'mysql+pymysql://root:[email protected]:3306/db_stable'
Engine = create_engine(DB_CONNECT_STRING, echo=True, pool_recycle=3600)
SQLAlchemy-创建表
__tablename__ 属性:数据库中该表的名称
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Index
from sqlalchemy.orm import sessionmaker, relationship
from sqlalchemy import create_engine
# 创建对象的基类,declarative_base() 创建了一个 Base类,这个类的子类可以自动与一个表关联。
Base = declarative_base()
# 创建单表
class Params(Base):
__tablename__ = "t_params"
__table_arge__ = {"extend_existing": True, "useexisting": True}
id = Column(Integer, primary_key=True, autoincrement=True)
package = Column(CHAR(255), nullable=False)
project = Column(CHAR(255), nullable=False)
platform = Column(CHAR(255), nullable=False)
prefix = Column(CHAR(255))
activity = Column(CHAR(255))
# 一对多,外键ForeignKey
class Devices(Base):
__tablename__ = "t_devices"
__table_arge__ = {"extend_existing": True, "useexisting": True}
id = Column(Integer, primary_key=True, autoincrement=True)
sn = Column(CHAR(255), nullable=False)
platform = Column(CHAR(50), nullable=False)
idfa = Column(CHAR(255))
uuid = Column(CHAR(255))
unionid = Column(CHAR(255))
product = Column(CHAR(255))
os_version = Column(CHAR(255))
class Jobs(Base):
__tablename__ = "t_jobs"
__table_arge__ = {"extend_existing": True, "useexisting": True}
id = Column(Integer, autoincrement=True, primary_key=True)
device_id = Column(Integer, ForeignKey("t_devices.id"))
user_name = Column(CHAR(255))
business = Column(CHAR(255))
version = Column(CHAR(50))
job_type = Column(CHAR(50))
submit_time = Column(DATETIME)
end_time = Column(DATETIME)
job_status = Column(Integer)
config_name = Column(CHAR(255))
# 多对多
class ServerToGroup(Base):
__tablename__ = 'servertogroup'
nid = Column(Integer, primary_key=True, autoincrement=True)
server_id = Column(Integer, ForeignKey('server.id'))
group_id = Column(Integer, ForeignKey('group.id'))
class Group(Base):
__tablename__ = 'group'
id = Column(Integer, primary_key=True)
name = Column(String(64), unique=True, nullable=False)
class Server(Base):
__tablename__ = 'server'
id = Column(Integer, primary_key=True, autoincrement=True)
hostname = Column(String(64), unique=True, nullable=False)
port = Column(Integer, default=22)
多对多关系:需要转换成1对多关系,需要一张中间表来转换,这张中间表里面需要存放学生表里面的主键和课程表里面的主键,此时学生与中间表示1对多关系,课程与中间表是1对多关系,学生与课程是多对多关系。
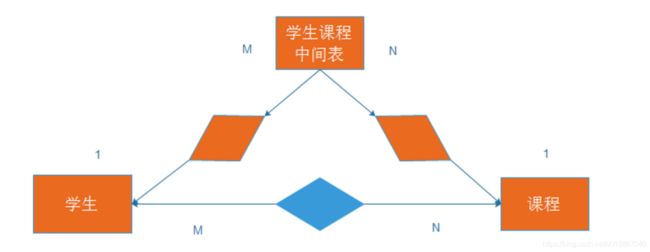
SQLAlchemy-创建会话(操作表)
sessionmaker() 会生成一个数据库会话类。这个类的实例可以当成一个数据库连接,它同时还记录了一些查询的数据,并决定什么时候执行 SQL 语句。
from sqlalchemy.orm import sessionmaker
# 创建Session对象(mysql操作对象)
Session = sessionmaker(bind=Engine, autoflush=True, expire_on_commit=True)
SQLAlchemy-增、删、改、查
新增:
@auto_close
def insert_job(body, session=None):
item = Jobs(**body)
session.add(item)
session.flush()删除:
@auto_close
def delete_job(data, jobId, session=None):
session.query(Jobs).filter(Jobs.id == jobId).delete
更新:
@auto_close
def update_job(data, jobId, session=None):
session.query(Jobs).filter(Jobs.id == jobId).update(data)
查询
@auto_close
def get_jobId(sub_time, session=None):
item = session.query(Jobs).filter(Jobs.submit_time == sub_time).first()
jobId = item.id
return jobId注意:
1.通过Session的query()方法创建一个查询对象。这个函数的参数数量是可变的,参数可以是任何类或者是类的描述的集合。
2.查询出来的数据sqlalchemy直接给映射成一个对象(或者是每个元素为这种对象的列表),对象和创建表时候的class是一致的,可以直接通过对象的属性直接调用。如:item.id
3.first():返回查询的第一个结果,如果没有结果,则返回None
all():以列表形式返回查询的所有结果
count():返回查询结果的数量
SQLAlchemy-查询
查询过滤器
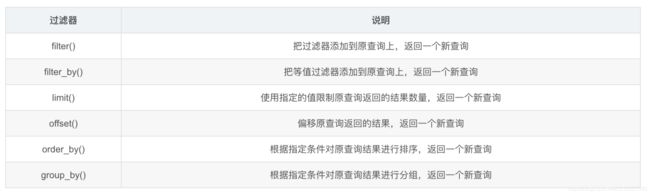
使用举例:
filter():过滤表的条件
filter: 可以像写 sql 的 where 条件那样写 > < 等条件,但引用列名时,需要通过"类名.属性名"的方式。
filter_by: 可以使用 python 的正常参数传递方法传递条件,指定列名时,不需要额外指定类名。参数名对应类中的属性名,但似乎不能使用 > < 等条件。
当使用filter的时候条件之间是使用“==",fitler_by使用的是"="。
user1 = session.query(User).filter_by(id=1).first()
user1 = session.query(User).filter(User.id==1).first()
# 条件:== 、!=、like、in、非、>、between
ret = session.query(Users).filter(Users.name =='alex').all()
ret = session.query(Users).filter(Users.name !='alex').all()
ret = session.query(Users).filter(Users.name.like("%alex%")).all()
ret = session.query(Users).filter(Users.id.in_([1,3,4])).all()
ret = session.query(Users).filter(~Users.id.in_([1,3,4])).all() # not in ~为通配符非
ret = session.query(Users).filter(~Users.name.like('e%')).all()
ret = session.query(Users).filter(Users.id > 1, Users.name == 'eric').all()
ret = session.query(Users).filter(Users.id.between(1, 3), Users.name == 'eric').all()
# AND 以下两个功能一致
ret = session.query(Users).filter(and_(Users.name == 'fengxiaoqing', Users.id ==10001)).all()
ret = session.query(Users).filter(Users.name == 'fengxiaoqing').filter(Users.address == 'chengde').all()
# OR
ret = session.query(Users).filter(or_(Users.name == 'fengxiaoqing', Users.age ==18)).all()
ret = session.query(Users).filter(
or_(
Users.id < 2,
and_(Users.name == 'eric', Users.id > 3),
Users.extra != ""
)).all()其余函数:
# order_by:排序 limit:指定行数
item = session.query(Jobs).order_by(Jobs.id).limit(4)
# desc:倒序显示 asc:升序
item = session.query(Jobs).order_by(Jobs.id.desc(),Jobs.device_id.asc())
# group_by
ret = session.query(Users).group_by(Users.extra).all()
# func
ret = session.query(
func.max(Users.id),
func.sum(Users.id),
func.min(Users.id)).group_by(Users.name).all()
ret = session.query(
func.max(Users.id),
func.sum(Users.id),
func.min(Users.id)).group_by(Users.name).having(func.min(Users.id) >2).all()
连接查询join
ret = session.query(Users, Favor).filter(Users.id == Favor.nid).all()
ret = session.query(Person).join(Favor).all()
ret = session.query(Person).join(Favor, isouter=True).all()子查询
ret = session.query(Users).filter(Users.id.in_(session.query(Users.id).filter_by(name='eric'))).all()联合查询union
q1 = session.query(Users.name).filter(Users.id > 2)
q2 = session.query(Favor.caption).filter(Favor.nid < 2)
ret = q1.union(q2).all()
q1 = session.query(Users.name).filter(Users.id > 2)
q2 = session.query(Favor.caption).filter(Favor.nid < 2)
ret = q1.union_all(q2).all()
参考
https://www.cnblogs.com/ccorz/p/5711955.html
https://blog.csdn.net/wuqing942274053/article/details/72571650
https://www.liaoxuefeng.com/wiki/001374738125095c955c1e6d8bb493182103fac9270762a000/0014021031294178f993c85204e4d1b81ab032070641ce5000
mysql查询操作:
https://blog.csdn.net/u012867040/article/details/54380900
https://blog.csdn.net/u012867040/article/details/59115271