简单介绍
如今差点儿全部的O2O应用中都会存在“按范围搜素、离我近期、显示距离”等等基于位置的交互。那这种功能是怎么实现的呢?本文提供的实现方式,适用于全部数据库。
实现
为了方便以下说明,先给出一个初始表结构。我使用的是MySQL:
CREATE TABLE `customer` (
`id` INT(11) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '自增主键',
`name` VARCHAR(5) NOT NULL COMMENT '名称',
`lon` DOUBLE(9,6) NOT NULL COMMENT '经度',
`lat` DOUBLE(8,6) NOT NULL COMMENT '纬度',
PRIMARY KEY (`id`)
)
COMMENT='商户表'
CHARSET=utf8mb4
ENGINE=InnoDB
;实现过程主要分为四步:
1. 搜索
在数据库中搜索出接近指定范围内的商户,如:搜索出1公里范围内的。
2. 过滤
搜索出来的结果可能会存在超过1公里的。须要再次过滤。
假设对精度没有严格要求,能够跳过。
3. 排序
距离由近到远排序。
假设不须要。能够跳过。
4. 分页
假设须要2、3步。才须要对分页特殊处理。
假设不须要。能够在第1步直接SQL分页。
第1步数据库完毕,后3步应用程序完毕。
step1 搜索
搜索能够用以下两种方式来实现。
区间查找
customer表中使用两个字段存储了经度和纬度,假设提前计算出经纬度的范围。然后在这两个字段上加上索引,那搜索性能会非常不错。
那怎么计算出经纬度的范围呢?已知条件是移动设备所在的经纬度,还有满足业务要求的半径,这非常像初中的一道平面几何题:给定圆心坐标和半径,求该圆外切正方形四个顶点的坐标。而我们面对的是一个球体,能够使用spatial4j来计算。
<dependency>
<groupId>com.spatial4jgroupId>
<artifactId>spatial4jartifactId>
<version>0.5version>
dependency>// 移动设备经纬度
double lon = 116.312528, lat = 39.983733;
// 千米
int radius = 1;
SpatialContext geo = SpatialContext.GEO;
Rectangle rectangle = geo.getDistCalc().calcBoxByDistFromPt(
geo.makePoint(lon, lat), radius * DistanceUtils.KM_TO_DEG, geo, null);
System.out.println(rectangle.getMinX() + "-" + rectangle.getMaxX());// 经度范围
System.out.println(rectangle.getMinY() + "-" + rectangle.getMaxY());// 纬度范围计算出经纬度范围之后,SQL是这样:
SELECT id, name
FROM customer
WHERE (lon BETWEEN ? AND ?) AND (lat BETWEEN ? AND ?
);
须要给lon、lat两个字段建立联合索引:
INDEX `idx_lon_lat` (`lon`, `lat`)geohash
geohash的原理不讲了,具体能够看这篇文章,讲的非常具体。geohash算法能把二维的经纬度编码成一维的字符串。它的特点是越相近的经纬度编码后越类似,所以能够通过前缀like的方式去匹配周围的商户。
customer表要添加一个字段。来存储每个商户的geohash编码。而且建立索引。
CREATE TABLE `customer` (
`id` INT(11) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '自增主键',
`name` VARCHAR(5) NOT NULL COMMENT '名称' COLLATE 'latin1_swedish_ci',
`lon` DOUBLE(9,6) NOT NULL COMMENT '经度',
`lat` DOUBLE(8,6) NOT NULL COMMENT '纬度',
`geo_code` CHAR(12) NOT NULL COMMENT 'geohash编码',
PRIMARY KEY (`id`),
INDEX `idx_geo_code` (`geo_code`)
)
COMMENT='商户表'
CHARSET=utf8mb4
ENGINE=InnoDB
;在新增或改动一个商户的时候,维护好geo_code,那geo_code怎么计算呢?spatial4j也提供了一个工具类GeohashUtils.encodeLatLon(lat, lon)。默认精度是12位。这个存储做好后,就能够通过geo_code去搜索了。拿到移动设备的经纬度,计算geo_code,这时能够指定精度计算。那指定多长呢?我们须要一个geo_code长度和距离的对比表:
| geohash length | width | height |
|---|---|---|
| 1 | 5,009.4km | 4,992.6km |
| 2 | 1,252.3km | 624.1km |
| 3 | 156.5km | 156km |
| 4 | 39.1km | 19.5km |
| 5 | 4.9km | 4.9km |
| 6 | 1.2km | 609.4m |
| 7 | 152.9m | 152.4m |
| 8 | 38.2m | 19m |
| 9 | 4.8m | 4.8m |
| 10 | 1.2m | 59.5cm |
| 11 | 14.9cm | 14.9cm |
| 12 | 3.7cm | 1.9cm |
https://en.wikipedia.org/wiki/Geohash#Cell_Dimensions
假设我们的需求是1公里范围内的商户,geo_code的长度设置为5就能够了,GeohashUtils.encodeLatLon(lat, lon, 5)。计算出移动设备经纬度的geo_code之后,SQL是这样:
SELECT id, name
FROM customer
WHERE geo_code LIKE CONCAT(?, '%');
这样会比区间查找快非常多,而且得益于geo_code的类似性,能够对热点区域做缓存。
但这样使用geohash还存在一个问题。geohash终于是在地图上铺上了一个网格。每个网格代表一个geohash值。当传入的坐标接近当前网格的边界时。用上面的搜索方式就会丢失它附近的数据。
比方下图中,在绿点的位置搜索不到白家大院,绿点和白家大院在划分的时候就分到了两个格子中。
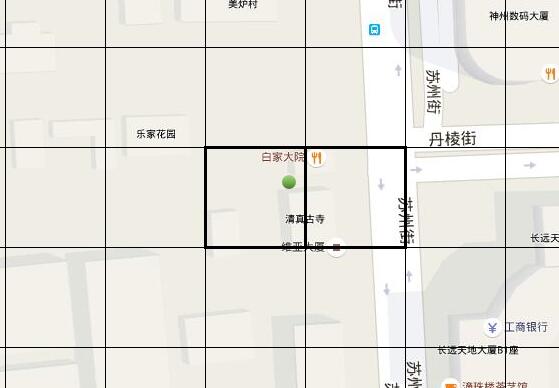
解决问题思路也比較简单,我们查询时。除了使用绿点的geohash编码进行匹配外,还使用周围8个网格的geohash编码,这样能够避免这个问题。那怎么计算出周围8个网格的geohash呢。能够使用geohash-java来解决。
<dependency>
<groupId>ch.hsrgroupId>
<artifactId>geohashartifactId>
<version>1.3.0version>
dependency>// 移动设备经纬度
double lon = 116.312528, lat = 39.983733;
GeoHash geoHash = GeoHash.withCharacterPrecision(lat, lon, 10);
// 当前
System.out.println(geoHash.toBase32());
// N, NE, E, SE, S, SW, W, NW
GeoHash[] adjacent = geoHash.getAdjacent();
for (GeoHash hash : adjacent) {
System.out.println(hash.toBase32());
}终于我们的sql变成了这样:
SELECT id, name
FROM customer
WHERE geo_code LIKE CONCAT(?, '%') OR geo_code LIKE CONCAT(?
, '%') OR geo_code LIKE CONCAT(?, '%') OR geo_code LIKE CONCAT(?, '%') OR geo_code LIKE CONCAT(?
, '%') OR geo_code LIKE CONCAT(?, '%') OR geo_code LIKE CONCAT(?, '%') OR geo_code LIKE CONCAT(?, '%') OR geo_code LIKE CONCAT(?, '%');
原来的1次查询变成了9次查询,性能肯定会下降,这里能够优化下。还用上面的需求场景,搜索1公里范围内的商户。从上面的表格知道。geo_code长度为5时,网格宽高是4.9KM,用9个geo_code查询时,范围太大了,所以能够将geo_code长度设置为6。即缩小了查询范围,也满足了需求。还能够继续优化,在存储geo_code时,仅仅计算到6位,这样就能够将sql变成这样:
SELECT id, name
FROM customer
WHERE geo_code IN (?, ?, ?, ?
, ?
, ?, ?
, ?, ?);
这样将前缀匹配换成了直接匹配,速度会提升非常多。
step2 过滤
上面两种搜索方式,都不是精确搜索,仅仅是尽量缩小搜索范围。提升响应速度。所以须要在应用程序中做过滤,把距离大于1公里的商户过滤掉。计算距离相同使用spatial4j。
// 移动设备经纬度
double lon1 = 116.3125333347639, lat1 = 39.98355521792821;
// 商户经纬度
double lon2 = 116.312528, lat2 = 39.983733;
SpatialContext geo = SpatialContext.GEO;
double distance = geo.calcDistance(geo.makePoint(lon1, lat1), geo.makePoint(lon2, lat2))
* DistanceUtils.DEG_TO_KM;
System.out.println(distance);// KM过滤代码就不写了。遍历一遍搜索结果就可以。
step3 排序
相同。排序也须要在应用程序中处理。排序基于上面的过滤结果做就能够了Collections.sort(list, comparator)。
step4 分页
假设须要2、3步,仅仅能在内存中分页,做法也非常easy。能够參考这篇文章。
总结
全文的重点都在于搜索怎样实现,更好的利用数据库的索引,两种搜索方式以百万数据量为切割线,第一种适用于百万以下。另外一种适用于百万以上,未经过严格验证。
可能有人会有疑问,过滤和排序都在应用层做。内存占用会不会非常严重?这是个潜在问题,但大多数情况下不会。
看我们大部分的应用场景,都是单一种类POI(Point Of Interest)的搜索,如酒店、美食、KTV、电影院等等,这种数据密度是非常小。1公里内的酒店。能有多少家,50家都算多的,所以终于要看具体业务数据密度。本文没有分析原理,仅仅讲了具体实现。有关分析的文章能够看參考链接。
參考
http://www.infoq.com/cn/articles/depth-study-of-Symfony2
http://tech.meituan.com/lucene-distance.html
http://blog.csdn.net/liminlu0314/article/details/8553926
http://janmatuschek.de/LatitudeLongitudeBoundingCoordinates
http://www.cnblogs.com/LBSer/p/3310455.html
http://cevin.net/geohash/
本文来自:高爽|Coder,原文地址:http://blog.csdn.net/ghsau/article/details/50591932,转载请注明。