Python--使用opencv图片数据增强
在进行模型训练的时候会遇到数据量小的问题。针对一些小数据集可以进行离线数据增强,一定程度上能防止模型过拟合。
下面是一些使用opencv库进行图片数据增强的方法。
具体函数使用方法,调参啥的可以自查opencv函数手册,也可以百度具体方法。
https://docs.opencv.org/
1、翻转
# 翻转
def flip(pic):
img = []
h_pic = cv2.flip(pic, 1) # 水平翻转
v_pic = cv2.flip(pic, 0) # 垂直翻转
hv_pic = cv2.flip(pic, -1) # 水平垂直翻转
img.append(h_pic)
img.append(v_pic)
img.append(hv_pic)
return img
2、旋转
# 旋转
def rotate(pic):
scale = 1.0
rows, cols = pic.shape[:2]
img = []
angle = [45, 90, 135, 180, 225, 275, 320]
center = (cols / 2, rows / 2) # 取图像的中点
for a in angle:
M = cv2.getRotationMatrix2D(center, a, scale) # 获得图像绕着某一点的旋转矩阵
pic = cv2.warpAffine(pic, M, (cols, rows), borderValue=(255, 255, 255))# cv2.warpAffine()的第二个参数是变换矩阵,第三个参数是输出图像的大小
img.append(pic)
return img
3、加噪声
# 噪声
def noise(pic):
for i in range(1500):
pic[random.randint(0, pic.shape[0] - 1)][random.randint(0, pic.shape[1] - 1)][:] = 255
return pic
# random.randint(a, b)
# 用于生成一个指定范围内的整数。其中参数a是下限,参数b是上限,生成的随机数n: a <= n <= b
4、模糊
# 高斯模糊
def gussian(pic):
img = []
temp = cv2.GaussianBlur(pic, (9, 9), 1.5) #高斯模糊
dst = cv2.blur(pic, (11, 11), (-1, -1)) #均值滤波
# cv2.GaussianBlur(图像,卷积核,标准差)
img.append(temp)
img.append(dst)
return img
5、光照
# 光照
def light(pic):
img = []
contrast = 1 #对比度
brightness = 100 #亮度
pic_turn1 = cv2.addWeighted(pic,contrast,pic,0,brightness)
pic_turn2 = cv2.addWeighted(pic, 1.5, pic, 0, 50)
img.append(pic_turn1)
img.append(pic_turn2)
# cv2.addWeighted(对象,对比度,对象,对比度)
#cv2.addWeighted()实现的是图像透明度的改变与图像的叠加
return img
6、仿射
# 仿射
def fangshe(pic):
rows, cols = pic.shape[:2]
point1 = np.float32([[50, 50], [300, 50], [50, 200]])
point2 = np.float32([[10, 100], [300, 50], [100, 250]])
M = cv2.getAffineTransform(point1, point2)
dst = cv2.warpAffine(pic, M, (cols, rows), borderValue=(255, 255, 255))
# 对图像进行变换(三点得到一个变换矩阵)
# 我们知道三点确定一个平面,我们也可以通过确定三个点的关系来得到转换矩阵
# 然后再通过warpAffine来进行变换
return dst
批量增强
遍历文件下面的图片,每张都增强一遍。需要注意的是,我采用的方法将每张图片都使用了一样的增强方法。如果对文件下图片进行随机赋予不同的增强方式,模型训练效果会更好,比如imgaug这个库就能实现。后续我会更新数据增强2.0版本,这
不过具体还是要结合自己的数据集,有些使用imgaug效果不一定会好,可能它变太多,加入的噪声太多了。
if __name__ == '__main__':
print('读取图像开始')
cate=['D:/me/animal/test/186/']
img_all = []
for idx, folder in enumerate(cate):
folder1 = folder.split('/')
id = folder1[4]
print(id, folder)
p = path_re + id + '/' #保存路径
for im in glob.glob(folder + '/*.jpg'): #遍历文件夹下的图片
try:
img = cv2.imread(im)
#img = cv2.resize(img,(224,224)) 裁剪
noi = noise(img) # 噪声
fli = flip(img) # 翻转
rot = rotate(img) # 旋转
guss = gussian(img) # 模糊
li = light(img) # 光线
fan = fangshe(img) # 仿射
img_all.append(img)
img_all.append(fan)
img_all = img_all + rot + fli +li + guss
img_all.append(noi)
im = im.split('\\')
im = im[1].split('.')[0]
for k, imge in zip(range(len(img_all)), img_all):
imge = cv2.resize(imge,(224,224))
cv2.imwrite(p + im + str(k) + '_.jpg', imge) #保存图片
except:
print(im)
img_all = []
结果示例:
需要数据增强的文件:
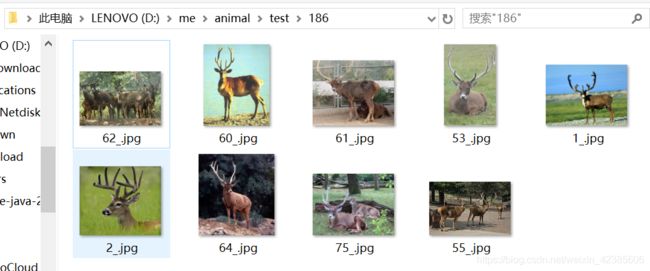
增强之后:
根据上面贴的代码,我在每种方法上都会通过调整多变几张。
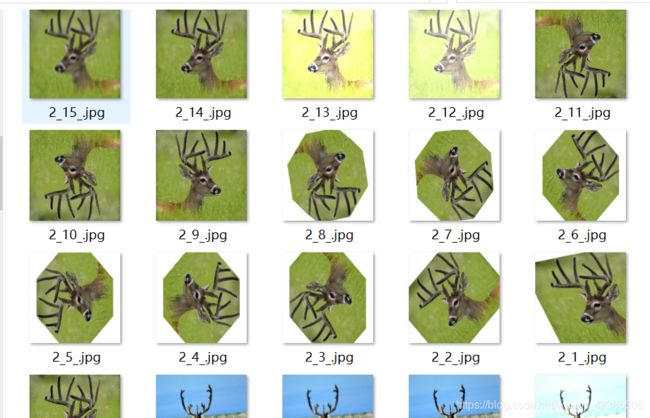
完整代码可见my github
本篇链接:
https://blog.csdn.net/weixin_42385606/article/details/105956416