SRCNN代码解读(一)-----utils.py
SRCNN下载的代码一共三个.py文件:主函数main.py、网络结构函数model.py和工具函数utils.py。将分三篇文章写出代码中每一句的作用。
在Python开发中,将常用功能封装成为接口,并放入Utils中,直接调用,可以提升效率也就是存放使用的小函数。到底里面包含了哪些函数功能,一句句分析,因为代码和注释写在容易混,所以我分开写。
import部分
不管是什么语言,开始总是先进行导入,导入需要的文件,库包等,python也不例外。utils.py
import os
import glob
import h5py
import random
import matplotlib.pyplot as plt
from PIL import Image # for loading images as YCbCr format
import scipy.misc
import scipy.ndimage
import numpy as np
import tensorflow as tf
import部分注释
1.import os
导入os库,主要用于系统命令的处理,其中join和os.path.join这两个函数都是python的系统函数,都有“组合”、“连接”之意,但用法和应用场景千差万别.
1.join
用法: 用于连接字符串数组。将字符串、元组、列表中的元素以指定的字符(即分隔符)连接生成一个新的字符串
语法: ‘sep’.join(seq)
参数说明: sep:分隔符,可以为空;seq:要连接的元素序列、字符串、元组、字典等
返回值: 返回一个以分隔符sep连接各个元素后生成的新字符串
import os
sep='*'
seq="If you are fragrant, butterflies come"
print(sep.join(seq))

import os
a='*'
seq='If','you','are','fragrant','butterflies','come'
print(a.join(seq))

2.os.path.join
用法: 将多个路径组合后返回,但是不会生成
语法: os.path.join(path1[,path2[,path3[,…[,pathN]]]])
返回值: 将多个路径组合后返回
注意: 第一个绝对路径之前的参数将会被忽略
用os.path.join()连接两个文件名地址的时候,就比os.path.join(“D:”,“test.txt”)结果是D:\test.txt,并且在我们往里面写东西,然后保存,在这个目录下会生成这个文件,但是如果你不写东西,那么执行这句话之后,在D盘的目录下是不会有这个文件名称的。
1.如果各组件名首字母不包含’/’,则函数会自动加上
import os
Path1 = 'home'
Path2 = 'develop'
Path3 = 'code'
print ('Path = ',os.path.join(Path1,Path2,Path3))

2. 如果有一个组件是一个绝对路径,则在它之前的所有组件均会被舍弃
import os
Path1 = '/home'
Path2 = 'develop'
Path3 = 'code'
Path20 = os.path.join(Path1, Path2, Path3)
Path30 = os.path.join(Path2, Path1, Path3)
print('Path20 = ',Path20)
print('Path30 = ',Path30)

3. 如果最后一个组件为空,则生成的路径以一个’/'分隔符结尾
import os
Path1 = 'home'
Path2 = 'develop'
Path3 = ''
Path20 = os.path.join(Path1, Path2, Path3)
Path30 = os.path.join(Path2, Path1, Path3)
print('Path20 = ',Path20)

2.import glob
glob库是python自己带的一个文件操作相关模块,用它可以查找符合自己目的的文件,就类似于Windows下的文件搜索,支持通配符操作
PS: 通配符是一种特殊语句,主要有星号( * )和问号( ? ),用来模糊搜索文件。当查找文件夹时,可以使用它来代替一个或多个真正字符;当不知道真正字符或者懒得输入完整名字时,常常使用通配符代替一个或多个真正的字符。

glob模块的主要方法就是glob和iglob,该方法返回所有匹配的文件路径列表(list);该方法需要一个参数用来指定匹配的路径字符串(字符串可以为绝对路径也可以为相对路径),其返回的文件名只包括当前目录里的文件名,不包括子文件夹里的文件。glob.glob()可同时获取所有的匹配路径,而glob.iglob()一次只能获取一个匹配路径
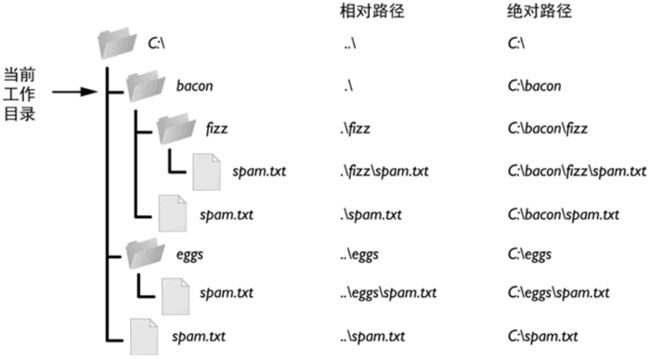
- 绝对路径: 总是从根文件夹开始,Window 系统中以盘符(C:、D:)作为根文件夹,而 OS X 或者 Linux 系统中以 / 作为根文件夹。
- 相对路径: 指的是文件相对于当前工作目录所在的位置。例如,当前工作目录为 “C:\Windows\System32”,若文件 demo.txt 就位于这个 System32 文件夹下,则 demo.txt 的相对路径表示为 “.\demo.txt”(其中 .\ 就表示当前所在目录)。
斜杠:/;反斜杠:\,windows地址分隔符,具体如图:
1.用法说明:
是获得C盘下的所有txt文件:
glob.glob(r’c:*.txt’) #加上r让字符串不转义
获得指定目录下的所有.jpg格式的图片
print glob.glob(r"E:/Picture/*/*.jpg")
2.用法实例:

import glob
print(glob.glob(r"F:/Code/SRCNN-test/test/*.jpg"))

import glob
a = glob.iglob(r"F:/Code/SRCNN-test/test/*.jpg")
for i in a:
print(i)

3.import h5py
1.HDF5
HDF5:Hierarchical Data Format Version 5, 层次性数据格式第五版。是一种为存储和处理大容量科学数据设计的文件格式及相应库文件。HDF5 文件一般以 .h5 或者 .hdf5 作为后缀名,需要专门的软件才能打开预览文件的内容。是一种常见的跨平台数据储存文件,可以存储不同类型的图像和数码数据,并且可以在不同类型的机器上传输,同时还有统一处理这种文件格式的函数库。HDF5适用于单机大规模数据应用,比如神经网络训练、股票回测、CFD计算、大数据体处理等等,python中常用的接口模块也就是使用工具为 h5py。
一个 HDF5 文件是存储两类对象的容器,这两类对象分别为:
- dataset:类似数组的数据集合;
- group;类似目录的容器,其中可以包含一个或多个 dataset 及其它的 group。
2.H5py
h5py是Python语言用来操作HDF5的模块.(库有问题暂时不写),剩下的都是基础的python库。
异常处理
在各种语言编程中,都会遇到一些错误异常。在python中有错误和异常俩种情况,错误最常见的情况就是语法错误SyntaxError,在运行过程中会有倒三角的箭头标明错误位置。另外一种就是异常,这种情况语句语法格式都没有错误,只是在运行过程中有错误。在python中,语法错误是直接显示在相关终端窗口,而异常可以进行错误提示,也可以进行捕捉处理。而捕捉异常处理通常使用try/except的语句。try异常进行捕捉except对错误进行处理。如果你不想在异常发生时结束你的程序,只需在try里捕获它。
try:
xrange#被检测的语句
except:
xrange = range#处理异常的语句
1.案例演示:
print("请输入账号")
try:
num = input(">>:");
print("您输入的数字是:%d"%(int(num)))
except:
print("您输入的是无效数据!")
print("请输入密码")
num = input(">>:")
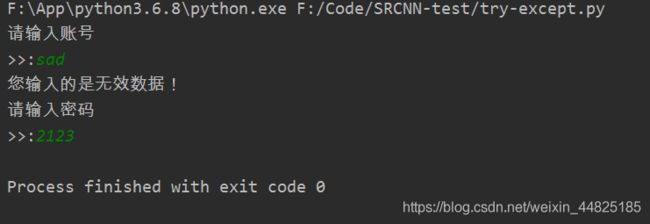
在Python编程中:%s表示格化式一个对象为字符,%d表示整数。except后面是可以跟不同的异常类型,这里省略
tf.app.flags.FLAGS
tf.app.flags 模块是Tensorflow提供的功能,用于为Tensorflow程序实现命令行标志。
也就是 tf.app.flags.FLAGS 用来命令行运行代码时传递参数.tf.app.flags.DEFINE_xxx()就是添加命令行的optional argument(可选参数),而tf.app.flags.FLAGS可以从对应的命令行参数取出参数。
import tensorflow as tf
FLAGS = tf.app.flags.FLAGS
# 基本模型参数
# 定义integer型flag
tf.app.flags.DEFINE_integer(name='batch_size', default=128,
help='Number of images to process in a batch.')
# 定义string型flag
tf.app.flags.DEFINE_string(name='data_dir', default='cifar-10-binary',
help='Path to the CIFAR-10 data directory.')
print(FLAGS.batch_size)
print(FLAGS.data_dir)
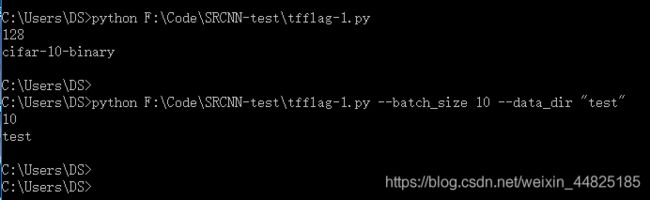
**提示:**命令行运行.py文件,直接输入python然后再打开要运行的.py文件左键直接拖拽就可以了不用自己输入位置太麻烦;在命令行设置参数时–batch_size前的空格和–data_dir前后的空格都必须有。
Def部分
1.Python函数
函数是组织好的,可重复使用,用来实现单一或者相关联功能的代码段。函数能提高代码的重复利用率,Python中有许多内建函数比如print(),但是有时候需要自己创建函数,这种函数叫做用户的自定义函数。再说的简单直白一点,函数就是给一段代码起一个名字,然后在其它地方用这个名字代替这一段代码来被使用其功能。在Python中函数必须遵守先定义再调用的规则否则将会报错。而函数的定义和调用就是它的使用方法。关于函数内容太多,作个简介知道是什么就ok了其它内容遇到再学习记录。
2.函数的注释
Python中函数的注释用" " “注释内容” " "的方法实现。如下图中红色框部分:
3.函数的定义和调用
1.函数定义语法格式
Python函数的定义需要使用关键字def,语法格式如下:
def 函数名(参数列表):
函数体
return 返回值列表
2.函数调用格式
变量名 = 函数名()
3.实例
utils.py一共有9个()函数,一个个来,全部征服!!!
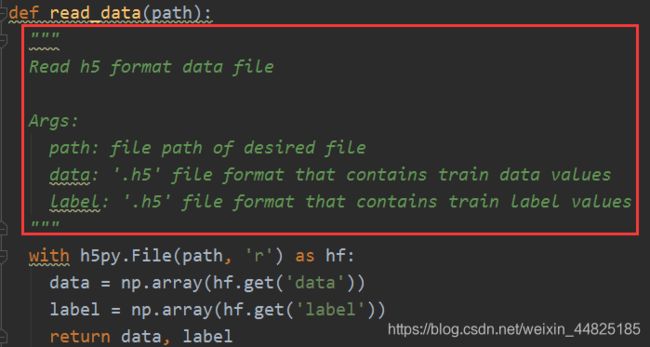
1.def read_data(path)–读取.h5文件的data和label数据,转化np.array格式
注释部分:
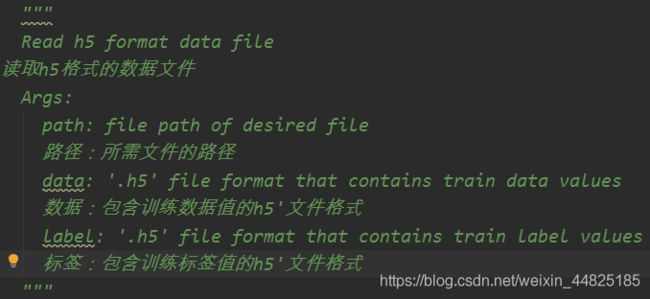
函数体:
with h5py.File(path, 'r') as hf:
data = np.array(hf.get('data'))
label = np.array(hf.get('label'))
return data, label
第一句 with h5py.File(path, ‘r’) as hf拆成俩部分with…as…和h5py.File(path, ‘r’)俩部分。这个函数本身就是读取数据而with语句就是用来实现读取需要的.h5数据文件的。在任何一门编程语言中都会涉及到文件中数据的I/O等这些常见的资源管理操作。但资源是有限的,在使用之后必须释放,不然轻则造成系统运行缓慢重则系统崩溃。虽然在不同的编程语言中有不同的文件关闭操作,比如Python中的close()但即便使用 close() 做好了关闭文件的操作,如果在打开文件或文件操作过程中抛出了异常,还是无法及时关闭文件。在python中引入with…as…来操作上下文管理器(context manager),它能够帮助我们自动分配并且释放资源。先了解普通的文件处理方法:
file = open("./test/IO.txt")
data = file.read()
file.close()#文件使用完毕后必须关闭,因为文件对象会占用操作系统的资源,并且操作系统同一时间能打开的文件数量也是有限的
print("读取的数据内容:",data)
#如果用一句话实现:
print("读取的数据内容:",(open("./test/IO.txt")).read())

由于文件读写时都有可能产生IOError,一旦出错,后面的f.close()就不会调用。所以,为了保证无论是否出错都能正确地关闭文件,我们可以使用try … finally来实现:
file = open("/tmp/foo.txt")
try:
data = file.read()
finally:
file.close()
但是还有一个更简洁的实现,就是用with as,with语句的目的是简化try/finally模式,用于保证一段代码运行完毕之后能够执行某项操作,即便代码由于异常、return语句或者sys.exit()调用而中止。
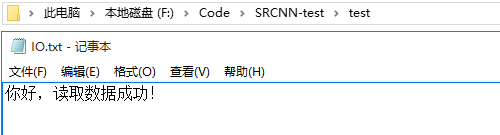
with open("./test/IO.txt") as content:
data = content.read()
print("读取的数据内容:",data)
#或者
with open("./test/IO.txt") as content:
print("读取的数据内容:",content.read())
还有就是np.array()这个函数,它的功能就是把数据转化为矩阵:
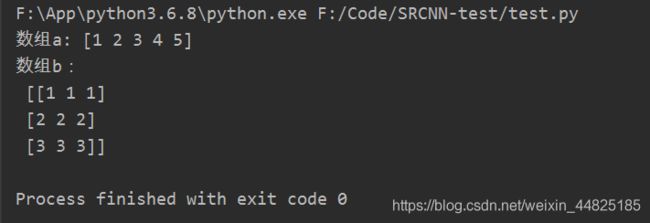
import numpy as np
a = np.array([1,2,3,4,5])
b = np.array([[1,1,1],[2,2,2],[3,3,3]])
print("数组a:",a)
print("数组b:\n",b)
2.def preprocess(path, scale=3)–对路径下的image裁剪成scale整数倍,再对image缩小1/scale倍后,放大scale倍以得到低分辨率图input_,调整尺寸后的image为高分辨率图label_
注释部分:
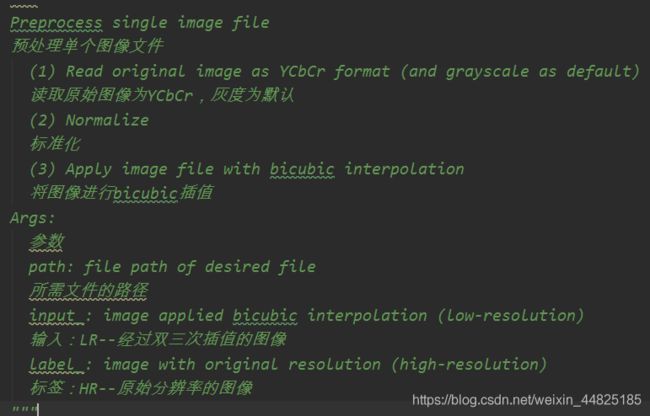
函数体:
image = imread(path, is_grayscale=True)
label_ = modcrop(image, scale)
# Must be normalized
image = image / 255.
label_ = label_ / 255.
input_ = scipy.ndimage.interpolation.zoom(label_, (1./scale), prefilter=False)
input_ = scipy.ndimage.interpolation.zoom(input_, (scale/1.), prefilter=False)
前俩行就是读入灰度图像
scipy.ndimage.interpolation.zoom(),根据scale进行裁剪,随后进行裁剪,最后是插值。关于插值scipy.ndimage.interpolation.zoom(),演示如下:
import numpy as np
import scipy.ndimage
x = np.arange(16).reshape(4, 4)
#arange(16)生成数组,只有结束项16即0-15,shape就是4*4的
print('Original array:')
print(x)
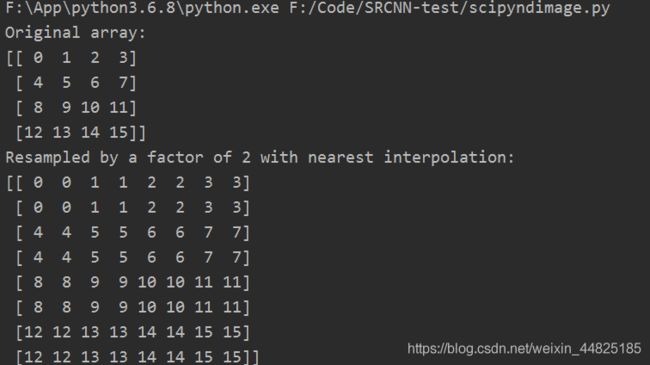
print('Resampled by a factor of 2 with nearest interpolation:')
print(scipy.ndimage.zoom(x, 2, order=0))
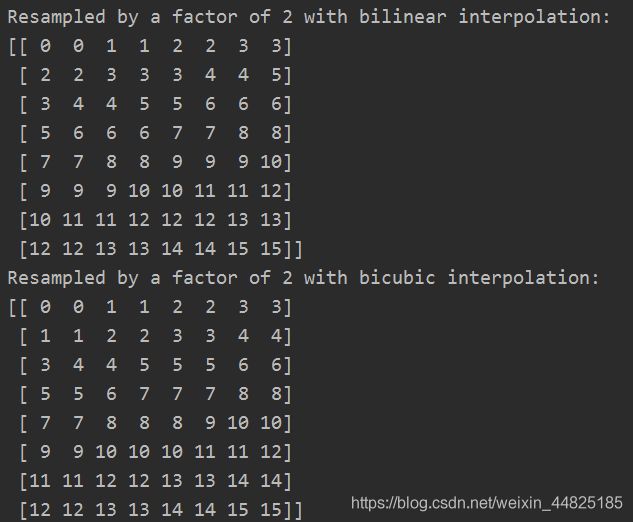
print('Resampled by a factor of 2 with bilinear interpolation:')
print(scipy.ndimage.zoom(x, 2, order=1))
print('Resampled by a factor of 2 with bicubic interpolation:')
print(scipy.ndimage.zoom(x, 2, order=3))
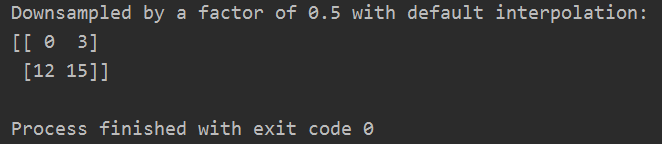
print('Downsampled by a factor of 0.5 with default interpolation:')
print(scipy.ndimage.zoom(x, 0.5))
2.def preprocess(path, scale=3)–对路径下的image裁剪成scale整数倍,再对image缩小1/scale倍后,放大scale倍以得到低分辨率图input_,调整尺寸后的image为高分辨率图label_
input_ = scipy.ndimage.interpolation.zoom(label_, (1./scale), prefilter=False)
input_ = scipy.ndimage.interpolation.zoom(input_, (scale/1.), prefilter=False)
通过把图片先缩小再放大 ,得到模糊图像(后面要用的input),原始图像就是label,然后把所有的图像裁剪成3333,和2121 分别添加到两个list中, 把两个list分别转成array,得到n33331 和n21211,然后存成.h5文件格式,再读出。最后返回图像和标签。
3.def prepare_data(sess, dataset)
filenames = os.listdir(dataset)
os.listdir(path): 返回输入路径下的文件和列表名称,即获得指定目录中的内容。
import os
path="F:\\Code\\SRCNN-test\\test"
# for i in path:
print(os.listdir(path))

data_dir = os.path.join(os.getcwd(), dataset)
os.getcwd(): 获得当前路径,该函数不需要传递参数,它返回当前的目录。需要说明的是,当前目录并不是指脚本所在的目录,而是所运行脚本的目录。
import os
print(os.getcwd())

data = glob.glob(os.path.join(data_dir, "*.bmp"))
#用它可以查找符合特定规则的文件路径名(data_dir下的所有.bmp文件)
os.sep
首先,python是跨平台的。在 Windows 上,文件的路径分割符号是 \ ,在 Linux 上 是 /。为了让你的代码在不同的平台上都能运行,那么你写路径的时候是写 / 还是写 \ 呢?使用 os.sep 的话,你就不用去考虑这个了,os.sep 根据你所处的平台,自动地采用相应的分割符号。举例:Linux下一个路径, /usr/share/python,那么上面的 os.sep 就是 / ,Windows下一个路径, C:\Users\Desktop, 那么上面的 os.sep 就是 \ 。
4.def make_data(sess, data, label)
参考文献:
1.python-基础语法-glob.glob()