深度学习系列:阿里DIN模型的原理和代码实现
一、前言
今天介绍阿里巴巴的DIN网络,不得不说,阿里妈妈的大佬是真的多,经常都会更新非常多的创造性的东西,比如DIN中使用的自适应正则化技术以及Dice激活函数以及注意力机制的使用,并且值得注意的是DIN网络中使用的注意力机制还挺多的,哈哈哈,下面就来介绍一下阿里妈妈推荐部门大佬们的主要工作吧;
论文地址:https://arxiv.org/abs/1706.06978
代码地址:https://github.com/zhougr1993/DeepInterestNetwork
二、算法原理
(1)深度兴趣网络主要考虑到用户兴趣的变化性,用户当前的兴趣可能只和历史信息中的一部分有关,并且考虑了用户兴趣的广泛性,比如一位用户浏览了运动类食品类书籍类的物品,那么这几类之间的关系就不是很大了,为了解决这类似的问题就提出了DIN网络;
(2)下图介绍了阿里推荐的流程:采集用户历史行为信息;通过matching获得候选广告;排序ranking得到每个广告的概率进行排序;记录用户在当前广告下点击与否作为标签;

模型的整体框架如下:先看一个basemodel吧,basemodel就是将用户特征,进行sum pooling输入给全连接层,和sigmoid函数得到一个输出的结果;
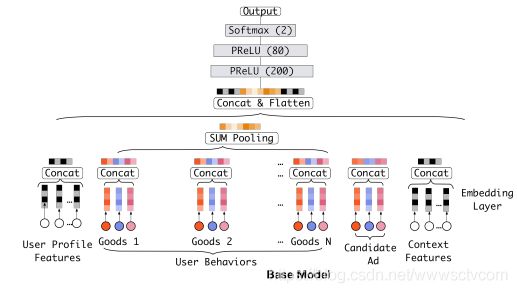
阿里巴巴的模型则是,利用注意力机制对用户的兴趣进行进行一个加权最后再使用一个sum pooling;

其中,va代表的是候选广告的嵌入向量,ej是用户历史中的兴趣;通过注意力机制来表示用户对于不同历史信息中的关注的重点部分;

(3)采用的特征:包括用户信息,用户行为信息,商品信息等等;其中包含了很多多值离散特征,多值离散特征就下一篇文章介绍一下怎处理吧;

(4)Dice函数(Data Adaptive Activation Function)是根据Pleakyrelu激活函数演化而来的,它的分割点不是严格的零点,而是根据数据来进行变化的,两者图像如下图所示;

Dice函数的公式如下所示,其中sigmoid函数中e的指数其实就是批量归一化算法;
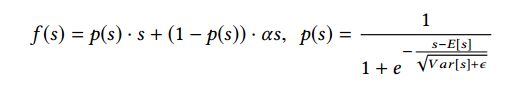
(5)自适应正则:在实际的用户数据中,会出现部分用户feature id出现频率很高从而导致噪声的增加,这对训练的结果也是有很大影响的,所以自适应正则的目的就是解决这个问题,方法就是根据用户feature id的出现频次来决定正则化的强度;
根据论文中的公式:公式(4)代表L2正则化,其中D代表embedding的维度,K代表整个特征空间数量, 代表是否x中有特征id j,
代表是否x中有特征id j,![]() 代表特征id j出现的频次;如果
代表特征id j出现的频次;如果![]() 越小那么正则权重就越大,相应的就达到了将正则强度加大的目的,如果
越小那么正则权重就越大,相应的就达到了将正则强度加大的目的,如果![]() 越小那么结果则反之,随后的表示则如图中所示;
越小那么结果则反之,随后的表示则如图中所示;

(6)测试指标:如下是推荐系统中常用的评价指标,
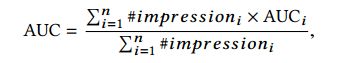
改进后的评价指标公式如下图所示,

经过测试可以得知,第二种评价指标更符合要求一点;
三、算法效果
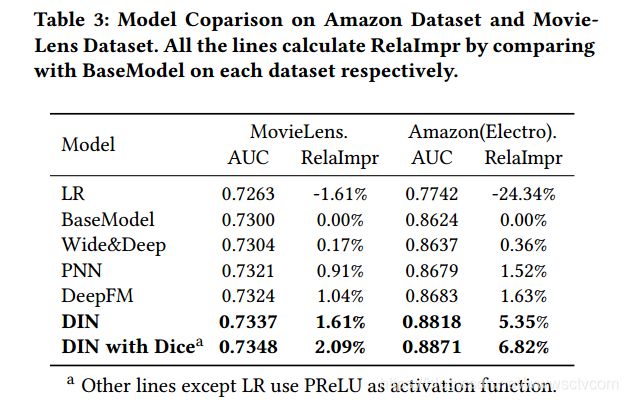
论文比较了在不同数据集上模型的表现,模型的测试结果如下图所示;

四、代码实现
代码实现部分,只实现了dice函数和注意力机制的部分;
(1)Dice函数实现部分,代码严格按照论文中公式实现;
import tensorflow as tf
from tensorflow.python.keras import backend as K
from tensorflow.python.keras.initializers import Zeros
from tensorflow.python.keras.layers import Layer, BatchNormalization
class Dice(Layer):
def __init__(self, axis=-1, epsilon=1e-9, **kwargs):
self.axis = axis
self.epsilon = epsilon
super(Dice, self).__init__(**kwargs)
def build(self, inputs_shape, **kwargs):
self.bn = BatchNormalization(self.axis, self.epsilon)
self.alphas = self.add_weight(name='dice_bias', shape=(inputs_shape[-1], ), initializer=Zeros(), dtype=tf.float32)
super(Dice, self).build(inputs_shape)
def call(self, inputs, **kwargs):
bn_inputs = self.bn(inputs)
p = tf.sigmoid(bn_inputs)
return self.alphas * (1 - p) * inputs + p * inputs(2)如下是din中attention部分
import tensorflow as tf
from tensorflow.python.keras import backend as K
class din_att(Layer):
def __init__(self, **kwargs):
super(din_att, self).__init__(**kwargs)
def call(self, inputs, **kwargs):
query, keys, keys_len= inputs#(batch, 1, embed_size), (batch, T, embed_size), (batch)中的值其实是T;
keys_len = keys.get_shape()[1]
querys = K.repeat_elements(query, keys_len, axis=1)
#din中原始代码的实现方法;
atten_input = tf.concat([querys, keys, querys - keys, querys * keys], axis=-1)#(batch, T, 4 * embed_size)
#经过三层全连接层;
dnn1 = tf.layers.dense(atten_input, 80, activation=tf.nn.sigmoid, name='dnn1')
dnn2 = tf.layers.dense(dnn1, 40, activation=tf.nn.sigmoid, name='dnn2')
dnn3 = tf.layers.dense(dnn2, 1, activation=None, name='dnn3')#(batch, T, 1)
outputs = tf.transpose(dnn3, (0, 2, 1))#(batch, 1, T)
#mask
keys_mask = tf.sequence_mask(keys_len, tf.shape(keys)[1])#(batch, T), bool;
keys_mask = tf.expand_dims(keys_mask, axis=1)#(batch, 1, T)
padding = tf.ones_like(outputs) * (-2 ** 32 + 1)#(batch, 1, T)
outputs = tf.where(keys_mask, outputs, padding)#the position of padding is set as a small num;
#scale
outputs = outputs / (tf.shape(keys)[-1] ** 0.5)
outputs = tf.nn.softmax(outputs)#(batch, 1, T)
#weighted sum_pooling
outputs = tf.matmul(outputs, keys) #(batch, 1, embedding)
return outputs