Tensorflow下利用Deeplabv3+训练自己的数据(超详细完整版)
使用deeplabv3+进行语义分割
环境要求:python3、tensorflow-gpu 1.11.0或者以上,ubuntu/win都可以
0.DeepLabv3+代码下载
0.1 将tensorflow的models下载到本地
git clone https://github.com/tensorflow/models.git0.2 添加环境变量:
windows用户:
右键点击我的电脑==>属性==>高级系统设置 ==>环境变量==>新建==>将slim文件路径添加进来(路径根据自己实际地填写)
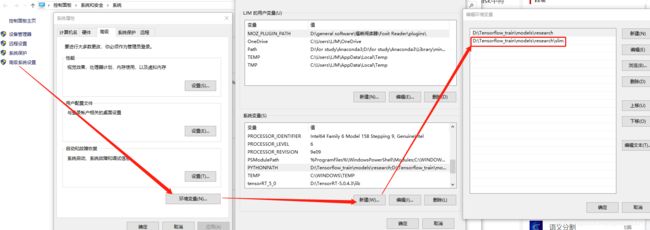
Linux用户:
添加依赖库到PYTHONPATH,在目录/home/user/models/research下:
# From /home/user/models/research/
$ export PYTHONPATH=$PYTHONPATH:`pwd`:`pwd`/slim
$ source ~/.bashrc
1.数据准备:
1.1 数据集做标签(语义分割、实例分割通用): 标注完成获得原始图片对应的json文件
图片(images:jpg)、标签文件(annotations:json)

1.2 json转灰度png: 利用labelme将json文件数据转换成voc格式,方便后续进一步转换成deeplab训练所需的灰度图格式
将labelme项目下载到本地:
git clone https://github.com/wkentaro/labelme.git找到目录/labelme/examples/semantic_segmentation,里面有一个进行转换的完整示例;
对照着示例,将自己的数据(原始图片和对应json标注)放入data_annotated文件夹;
制作自己的labels.txt,而labelme2voc.py文件不需改动。如下:

# It generates:
# - data_dataset_voc/JPEGImages
# - data_dataset_voc/SegmentationClass
# - data_dataset_voc/SegmentationClassVisualization
python labelme2voc.py data_annotated data_dataset_voc --labels labels.txt
会生成data_dataset_voc文件夹,里面包含:

1.3 colormap的PNG标注图转换到灰度图PNG
deeplab使用单通道的标注图,即灰度图,并且类别的像素标记应该是0,1,2,3…n(共计n+1个类别,包含1个背景类和n个目标类),此外,标注图上忽略的像素值标记为255。
注意:不要把 ignore_label 和 background 混淆,ignore_label(作为crop_size时像素大小不够的情况下填充的白色像素点) 没有做标注,不在预测范围内,即不参与计算loss。我们在mask中将 ignore_label 的灰度值标记为 255,而background 标记为 0。
我们上一步获得了voc格式数据,对于voc这种有colormap的标注图,可以利用remove_gt_colormap.py去掉colormap转成灰度图。
使用models/research/deeplab/datasets/remove_gt_colormap.py
# from models/research/deeplab/datasets
python remove_gt_colormap.py \
--original_gt_folder="/path/SegmentationClassPNG" \
--output_dir="/path/SegmentationClassRaw"original_gt_folder:是原始标签图文件夹,这里给定上一步生成的data_dataset_voc文件夹下的SegmentationClassPNG文件夹路径;
output_dir:是要输出的标签图文件夹的位置,设定为和SegmentationClassPNG文件夹同级目录下的SegmentationClassRaw文件夹。
生成的SegmentationClassRaw文件夹里面就是需要的灰度图(mask):

1.4 生成train.txt、valid.txt,不需要分出测试集
- train.txt: 训练集
- valid.txt: 验证集
数据集目录如下:
From /root/data
- images
- mask
- txt_and_tfrecord:放置txt、tfrecord
txt:放置train.txt、val.txt
tfrecord:放置train.tfrecord、val.tfrecord等
这里贴出我自己写的生成代码generate_train&valid_txt.py:90%训练集、10%验证集
import os
import random
root_path = os.getcwd()
images_dir = root_path + '\\data\\images'
images_list = os.listdir(images_dir)
print(images_list)
print('----------------------------------------------')
random.shuffle(images_list) # 打乱图片的分布
print(images_list)
total_num = len(images_list)
print("总数量:",total_num)
train_num = int(total_num*0.9)
print("训练集数量:",train_num)
print("验证集数量:",total_num-train_num)
list_file_1 = open(root_path+'\\data\\txt_and_tfrecord\\txt\\train.txt', 'w')
for item1 in images_list[:train_num]:
image_id = item1.split('.')[0]
list_file_1.write('%s\n' % (image_id))
list_file_1.close()
list_file_2 = open(root_path + '\\data\\txt_and_tfrecord\\txt\\val.txt', 'w')
for item2 in images_list[train_num:]:
image_id = item2.split('.')[0]
list_file_2.write('%s\n' % (image_id))
list_file_2.close()最终获取的文件名如下:

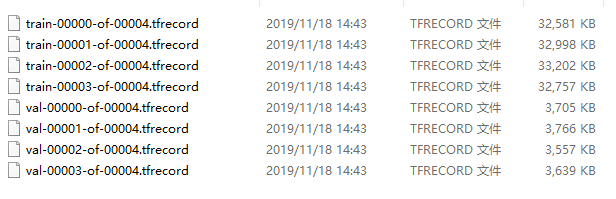
1.5 生成train.tfrecord、val.tfrecord
利用build_voc2012_data.py转换成tfrecord格式: image_format为原始图片的格式。
# from /root/models/research/deeplab/datasets/
python ./build_voc2012_data.py \
--image_folder="./data/images" \
--semantic_segmentation_folder="./data/mask" \
--list_folder="./data/txt_and_tfrecord/txt" \
--image_format="jpg" \
--output_dir="./data/txt_and_tfrecord/tfrecord"
2. 修改训练文件
2.1 修改data_generator.py(deeplab/datasets下)
找到data_generator.py文件,在大概110行的位置,添加自己数据集的描述,假设数据集有a,b, background三个类别,加上ignore_label,一共4类,所以num_classes=4:
_MYDATA_INFORMATION = DatasetDescriptor(
splits_to_sizes={
'train': 1500, # 训练集数量
'val': 300, # 测试集数量
},
num_classes=4,
ignore_label=255,
)
之后注册数据集,在大概112行的位置添加自己的数据集:
_DATASETS_INFORMATION = {
'cityscapes': _CITYSCAPES_INFORMATION,
'pascal_voc_seg': _PASCAL_VOC_SEG_INFORMATION,
'ade20k': _ADE20K_INFORMATION,
'mydata':_MYDATA_INFORMATION, # 添加自己的数据集
}2.2 train_utils.py
在train_utils.py中,先将大概109行的关于exclude_list的设置修改,作用是在使用预训练权重时候,不加载该logit层:
exclude_list = ['global_step','logits']
if not initialize_last_layer:
exclude_list.extend(last_layers)对于数据集本身,如果数据不平衡,即各类别a,b,background在数据集中占比不相同,比如background占比远大于a,b类别,则需要对权重进行分配,假设权重比为1:10:11,则在train_utils.py的大概70行修改权重:
ignore_weight = 0
label0_weight = 1 # 对应background,mask中灰度值0
label1_weight = 10 # 对应a,mask中灰度值1
label2_weight = 11 # 对应b,mask中灰度值2
not_ignore_mask = tf.to_float(tf.equal(scaled_labels, 0)) * label0_weight + \
tf.to_float(tf.equal(scaled_labels, 1)) * label1_weight + \
tf.to_float(tf.equal(scaled_labels, 2)) * label2_weight + \
tf.to_float(tf.equal(scaled_labels, ignore_label)) * ignore_weight
tf.losses.softmax_cross_entropy(
one_hot_labels,
tf.reshape(logits, shape=[-1, num_classes]),
weights=not_ignore_mask,
scope=loss_scope)如果数据不平衡,这里涉及到对各类别像素的统计,贴一个脚本:
# 统计类别像素比例
import cv2
import numpy as np
import glob
pngpath = glob.glob('./datac/mask/*.png')
zmat = np.zeros([30], dtype = np.float32)
for path in pngpath:
mask = cv2.imread(path, cv2.IMREAD_GRAYSCALE)
for pixelvalue in range(30):
a1 = mask == pixelvalue
a1_count = len(mask[a1])
zmat[pixelvalue]+=a1_count/10000
list = []
for a in zmat:
b = zmat[0]/a
list.append(b)
print(list)
3. 模型训练
3.1 训练设置
如果想在DeepLab的基础上fine-tune其他数据集, 可在train.py中修改输入参数。有一些选项:
使用预训练的所有权重,设置initialize_last_layer=True
只使用网络的backbone,设置initialize_last_layer=False和last_layers_contain_logits_only=False
使用所有的预训练权重,除了logits,因为如果是自己的数据集,对应的classes不同(这个我们前面已经设置不加载logits),可设置initialize_last_layer=False和last_layers_contain_logits_only=True

最终设置:
initialize_last_layer=Falselast_layers_contain_logits_only=True
3.2 修改训练代码只保存唯一模型
训练代码334行,修改三处:红色部分
saver = tf.train.Saver(max_to_keep=1)
hooks = [stop_hook, tf.train.CheckpointSaverHook(checkpoint_dir=train_logdir, save_steps=200, saver=saver)]
profile_dir = None
if profile_dir is not None:
tf.gfile.MakeDirs(profile_dir)
with tf.contrib.tfprof.ProfileContext(
enabled=profile_dir is not None, profile_dir=profile_dir):
with tf.train.MonitoredTrainingSession(
master='',
is_chief=True,
config=session_config,
scaffold=scaffold,
checkpoint_dir=train_logdir,
# summary_dir=train_logdir,
log_step_count_steps=log_steps,
save_summaries_steps=600, # 600
save_checkpoint_secs=None,
hooks=hooks) as sess: # 增加hooks回调参数保存唯一模型
while not sess.should_stop():
sess.run([train_tensor])3.3 训练指令
# from /root/models/research/
python deeplab/train.py \
--logtostderr \
--num_clones=1 \
--training_number_of_steps=50000 \
--train_split="train" \
--model_variant="xception_65" \
--atrous_rates=6 \
--atrous_rates=12 \
--atrous_rates=18 \
--output_stride=16 \
--decoder_output_stride=4 \
--train_crop_size=513 \
--train_crop_size=513 \
--train_batch_size=6 \
--dataset="mydata" \
--fine_tune_batch_norm=False \
--tf_initial_checkpoint='./deeplab/backbone/xception_65/model.ckpt' \
--train_logdir='./deeplab/models/mydata' \
--dataset_dir='./deeplab/data/txt_and_tfrecord/tfrecord'其中:num_clones:用1个gpu进行训练所以设置成1,默认为1。
train_crop_size:裁剪图片大小,先高后宽(height+1, width+1)
对于参数的说明:
不得小于 [321, 321]
(crop_size - 1)/4 = 整数
将crop_size设置为[256, 256],结果不会好,因为其有ASPP(atrous spatial pyramid pooling)模块;
如果图片过小,到feature map时没有扩张卷积的范围大了,所以要求一个最小值train_batch_size:batch尺寸,如要训练BN层,batch_size值最好大于12,如果显存不够,可调整crop_size大小,但不得小于[321, 321]。
fine_tune_batch_norm:当batch_size大于12时,设置为True。
tf_initial_checkpoint:修改成自己的预训练权重路径,我这边使用的是xception_71_imagenet,在网站 https://github.com/tensorflow/models/blob/master/research/deeplab/g3doc/model_zoo.md 可根据自己的需求获取对应的预训练权重。
train_logdir:训练产生的文件存放路径。
训练时部分输出:
...
INFO:tensorflow:global step 98250: loss = 1.9128 (0.731 sec/step)
INFO:tensorflow:global step 98260: loss = 3.2374 (0.740 sec/step)
INFO:tensorflow:global step 98270: loss = 1.3137 (0.736 sec/step)
INFO:tensorflow:global step 98280: loss = 3.3541 (0.732 sec/step)
INFO:tensorflow:global step 98290: loss = 1.1512 (0.740 sec/step)
INFO:tensorflow:global step 98300: loss = 1.8416 (0.735 sec/step)
INFO:tensorflow:global step 98310: loss = 1.5447 (0.753 sec/step)
...4.模型验证:计算验证集的miou
4.1 修改eval.py代码
eval.py159行增加二行代码:
print_miou = tf.Print(miou, [miou], 'miou is:') #创建tf.Print()的op
tf.summary.scalar('print_miou', print_miou) #把这个op加到summary里,后面在tf.contrib.training.evaluate_repeatedly中会自动调用4.2 拿到miou变量值
eval.py最后增加五行代码:
event_file = os.path.join(eval_logdir, os.listdir(eval_logdir)[0])
for e in tf.train.summary_iterator(event_file):
for v in e.summary.value:
if v.tag == 'miou_1.0': # 选取要读取数据的节点 v.tag == 'miou_1.0' or v.tag == 'print_miou_'
miou_value = round(v.simple_value, 4) # 保留小数点后4位4.3 验证指令:
python deeplab/eval.py \
--logtostderr \
--eval_split="val" \
--model_variant="xception_65" \
--atrous_rates=6 \
--atrous_rates=12 \
--atrous_rates=18 \
--output_stride=16 \
--decoder_output_stride=4 \
--eval_crop_size=513 \
--eval_crop_size=513 \
--dataset="mydata" \
--checkpoint_dir='./deeplab/models/mydata/' \
--eval_logdir='./deeplab/models/mydata/eval/' \
--dataset_dir='./deeplab/data/txt_and_tfrecord/tfrecord'其中:eval_split:设置为测试集val。
eval_crop_size:同样设置为val图片大小513*513,先高后宽(height+1, width+1)
部分输出:
INFO:tensorflow:Starting evaluation at 2049-06-27-00:54:14
INFO:tensorflow:Evaluation [27/271]
INFO:tensorflow:Evaluation [54/271]
INFO:tensorflow:Evaluation [81/271]
INFO:tensorflow:Evaluation [108/271]
INFO:tensorflow:Evaluation [135/271]
INFO:tensorflow:Evaluation [162/271]
INFO:tensorflow:Evaluation [189/271]
INFO:tensorflow:Evaluation [216/271]
INFO:tensorflow:Evaluation [243/271]
INFO:tensorflow:Evaluation [270/271]
INFO:tensorflow:Evaluation [271/271]
INFO:tensorflow:Finished evaluation at 2019-06-27-00:54:36
miou_1.0[0.998610853]如果之后显示INFO:tensorflow:Waiting for new checkpoint
设置:max_number_of_evaluations = 1 就可以解决运行一次之后还没关闭程序的问题
5.模型可视化
可视化指令:
python deeplab/vis.py \
--logtostderr \
--vis_split="val" \
--model_variant="xception_65" \
--atrous_rates=6 \
--atrous_rates=12 \
--atrous_rates=18 \
--output_stride=16 \
--decoder_output_stride=4 \
--vis_crop_size=513 \
--vis_crop_size=513 \
--dataset="mydata" \
--colormap_type="pascal" \
--checkpoint_dir='./deeplab/mdoels/mydata/' \
--vis_logdir='./deeplab/models/mydata/vis/' \
--dataset_dir='./deeplab/data/txt_and_tfrecord/tfrecord/'其中:
vis_split:设置为测试集val。
vis_crop_size:设置成val数据集里面图片的大小,比如我的是512*512,那就设置先高后宽(height+1, width+1):513*513
dataset:设置为我们在data_generator.py文件设置的数据集名称。
dataset_dir:设置为创建的tfrecord路径。
colormap_type:可视化标注的颜色。
可视化部分输出:
INFO:tensorflow:Restoring parameters from /root/models/research/deeplab/exp/mydata_train/train/model.ckpt-100000
INFO:tensorflow:Visualizing batch 1 / 271
INFO:tensorflow:Visualizing batch 2 / 271
INFO:tensorflow:Visualizing batch 3 / 271
INFO:tensorflow:Visualizing batch 4 / 271
...可视化结果:

6. 导出模型,生成frozen_inference_graph.pb以便接下来inference
python deeplab/export_model.py \
--logtostderr \
--checkpoint_path="./deeplab/mdoels/mydata/model.ckpt-48214" \
--export_path="./deeplab/models/mydata/frozen_inference_graph.pb" \
--model_variant="xception_65" \
--atrous_rates=6 \
--atrous_rates=12 \
--atrous_rates=18 \
--output_stride=16 \
--decoder_output_stride=4 \
--num_classes=4 \
--crop_size=513 \
--crop_size=513 \
--inference_scales=1.0尝试输入不同分辨率的图像,分割效果差距很大。
export_model 的时候crop_size 的参数选择:根据自己的测试,此时的crop_size :[513,513]
如果比513大,预测出来的效果会很稀疏,不好。如果比513小,直接报错。
一些可能的困难
数据集不平衡
之前已经说过这个问题,如果各类别的像素区域差别大,需要设置权重进行平衡。
输入数据尺寸统一(可选)
我的原始数据大小不一,由于在训练时设置crop_size不能小于321321,所以我将原始图片和mask进行尺寸统一为512,512。
贴一段统一尺寸的脚本:
# mask的size统一
import cv2
import glob
maskpath = glob.glob('./mask/*.png')
for path in maskpath:
name = path[31:]
crop_size = (512, 512)
img = cv2.imread(path, cv2.IMREAD_GRAYSCALE)
img_new = cv2.resize(img, crop_size, interpolation = cv2.INTER_LINEAR)
cv2.imwrite('./maskc/'+name, img_new, [int(cv2.IMWRITE_PNG_COMPRESSION), 0])注意,对于灰度图的mask,我使用的插值方式是cv2.INTER_LINEAR,因为只有这个方式能够保证在缩放的时候不引入其他的像素值(比如这个类别的像素值是3,在缩放的时候边缘不会出现2,1)。
官方FAQ
deeplab官方FAQ:https://github.com/tensorflow/models/blob/master/research/deeplab/g3doc/faq.md
可能会找到想要的问题答案。
[References]:
https://blog.csdn.net/malvas/article/details/88896283
https://blog.csdn.net/malvas/article/details/90776327
https://blog.csdn.net/u011974639/article/details/80948990
https://blog.csdn.net/weixin_41713230/article/details/8193776
https://www.jianshu.com/p/dcca31142b99
https://www.aiuai.cn/aifarm276.html