零拷贝,多路复用器理论及在Nginx中的应用
零拷贝与多路复用器
- 零拷贝(Zero Copy)
-
- 零拷贝概念
- 传统拷贝方式
- 零拷贝方式
- Gather Copy DMA 零拷贝方式
- mmap 零拷贝
- 多路复用器 select|poll|epoll
-
- 多进程/多线程连接处理模型
- 多路复用连接处理模型
-
- Select
- Poll
- Epoll
-
- LT模式
- ET模式
- Nginx的并发处理机制
零拷贝(Zero Copy)
零拷贝概念
零拷贝指的是,从一个存储区域到另一个存储区域的 copy 任务没有 CPU 参与。零拷贝通常用于网络文件传输,以减少 CPU 消耗和内存带宽占用,减少用户空间与 CPU 内核空间的拷贝过程,减少用户上下文与 CPU 内核上下文间的切换,提高系统效率。
用户空间指的是用户可操作的内存缓存区域,CPU 内核空间是指仅 CPU 可以操作的寄存器缓存及内存缓存区域。
用户上下文指的是用户状态环境,CPU 内核上下文指的是 CPU 内核状态环境。
零拷贝需要 DMA 控制器的协助。DMA,Direct Memory Access,直接内存存取,是 CPU的组成部分,其可以在 CPU 内核(算术逻辑运算器 ALU 等)不参与运算的情况下将数据从一个地址空间拷贝到另一个地址空间。
传统拷贝方式
首先通过应用程序的 read()方法将文件从硬盘读取出来,然后再调用 send()方法将文件发送出去。

该拷贝方式共进行了 4 次用户空间与内核空间的上下文切换,以及 4 次数据拷贝,其中两次拷贝存在 CPU 参与。
我们发现一个很明显的问题:应用程序的作用仅仅就是一个数据传输的中介,最后将kernel buffer 中的数据传递到了 socket buffer。显然这是没有必要的。所以就引入了零拷贝。
零拷贝方式
Linux 系统(CentOS6 及其以上版本)对于零拷贝是通过 sendfile 系统调用实现的。

该拷贝方式共进行了 2 次用户空间与内核空间的上下文切换,以及 3 次数据拷贝,但整个拷贝过程均没有 CPU 的参与,这就是零拷贝。
我们发现这里还存在一个问题:kernel buffer 到 socket buffer 的拷贝需要吗?kernelbuffer 与 socket buffer 有什么区别呢?DMA 控制器所控制的拷贝过程有一个要求,数据在源头的存放地址空间必须是连续的。kernel buffer 中的数据无法保证其连续性,所以需要将数据再拷贝到 socket buffer,socket buffer 可以保证了数据的连续性。
这个拷贝过程能否避免呢?可以,只要主机的 DMA 支持 Gather Copy 功能,就可以避免由 kernel buffer 到 socket buffer 的拷贝。
Gather Copy DMA 零拷贝方式
由于该拷贝方式是由 DMA 完成,与系统无关,所以只要保证系统支持 sendfile 系统调用功能即可。
该方式中没有数据拷贝到 socket buffer。取而代之的是只是将 kernel buffer 中的数据描述信息写到了 socket buffer 中。数据描述信息包含了两方面的信息:kernel buffer 中数据的地址及偏移量。

该拷贝方式共进行了 2 次用户空间与内核空间的上下文切换,以及 2 次数据拷贝,并且整个拷贝过程均没有 CPU 的参与。
该拷贝方式的系统效率是高了,但与传统相比,也存在有不足。传统拷贝中 user buffer中存有数据,因此应用程序能够对数据进行修改等操作;零拷贝中的 user buffer 中没有了数据,所以应用程序无法对数据进行操作了。Linux 的 mmap 零拷贝解决了这个问题。
mmap 零拷贝
mmap 零拷贝是对零拷贝的改进。当然,若当前主机的 DMA 支持 Gather Copy,mmap
同样可以实现 Gather Copy DMA 的零拷贝。
该方式与零拷贝的唯一区别是,应用程序与内核共享了 Kernel buffer。由于是共享,所以应用程序也就可以操作该 buffer 了。当然,应用程序对于 Kernel buffer 的操作,就会引发用户空间与内核空间的相互切换。

该拷贝方式共进行了 4 次用户空间与内核空间的上下文切换,以及 2 次数据拷贝,并且
整个拷贝过程均没有 CPU 的参与。虽然较之前面的零拷贝增加了两次上下文切换,但应用
程序可以对数据进行修改了。
多路复用器 select|poll|epoll
多进程/多线程连接处理模型
了解多路复用器我们先要了解多进程/多线程连接处理模型

在该模型下,一个用户连接请求会由一个内核进程处理,而一个内核进程会创建一个应用程序进程,即 app 进程来处理该连接请求。应用程序进程在调用 IO 时,采用的是 BIO 通讯方式,即应用程序进程在未获取到 IO 响应之前是处于阻塞态的。
该模型的优点是,内核进程不存在对app进程的竞争,一个内核进程对应一个app进程。 但,也正因为如此,所以其弊端也就显而易见了。需要创建过多的 app 进程,而该创建过程十分的消耗系统资源。且一个系统的进程数量是有上限的,所以该模型不能处理高并发的情况。
多路复用连接处理模型

在该模型下,只有一个 app 进程来处理内核进程事务,且 app 进程一次只能处理一个内核进程事务。故这种模型对于内核进程来说,存在对 app 进程的竞争。
在前面的“多进程/多线程连接处理模型”中我们说过,app 进程只要被创建了就会执行内核进程事务。那么在该模型下,应用程序进程应该执行哪个内核进程事务呢?谁的准备
就绪了,app 进程就执行哪个。但 app 进程怎么知道哪个内核进程就绪了呢?需要通过“多
路复用器”来获取各个内核进程的状态信息。那么多路复用器又是怎么获取到内核进程的状
态信息的呢?不同的多路复用器,其算法不同。常见的有三种:select、poll 与 epoll。
app 进程在进行 IO 时,其采用的是 NIO 通讯方式,即该 app 进程不会阻塞。当一个 IO结果返回时,app 进程会暂停当前事务,将 IO 结果返回给对应的内核进程。然后再继续执行暂停的线程。
该模型的优点很明显,无需再创建很多的应用程序进程去处理内核进程事务了,仅需一
个即可。
Select
select 多路复用器是采用轮询的方式,一直在轮询所有的相关内核进程,查看它们的进程状态。若已经就绪,则马上将该内核进程放入到就绪队列。否则,继续查看下一个内核进程状态。在处理内核进程事务之前,app 进程首先会从内核空间中将用户连接请求相关数据复制到用户空间。
该多路复用器的缺陷有以下几点:
- 对所有内核进程采用轮询方式效率会很低。因为对于大多数情况下,内核进程都不属于就绪状态,只有少部分才会是就绪态。所以这种轮询结果大多数都是无意义的。
- 由于就绪队列底层由数组实现,所以其所能处理的内核进程数量是有限制的,即其能够处理的最大并发连接数量是有限制的。
- 从内核空间到用户空间的复制,系统开销大。
Poll
poll 多路复用器的工作原理与 select 几乎相同,不同的是,由于其就绪队列由链表实现,所以,其对于要处理的内核进程数量理论上是没有限制的,即其能够处理的最大并发连接数量是没有限制的(当然,要受限于当前系统中进程可以打开的最大文件描述符数 ulimit)。
Epoll
epoll 多路复用是对 select 与 poll 的增强与改进。其不再采用轮询方式了,而是采用回调方式实现对内核进程状态的获取:一旦内核进程就绪,其就会回调 epoll 多路复用器,进入到多路复用器的就绪队列(由链表实现)。所以 epoll 多路复用模型也称为 epoll 事件驱动模型。
另外,应用程序所使用的数据,也不再从内核空间复制到用户空间了,而是使用 mmap零拷贝机制,大大降低了系统开销。
当内核进程就绪信息通知了 epoll 多路复用器后,多路复用器就会马上对其进行处理,将其马上存放到就绪队列吗?不是的。根据处理方式的不同,可以分为两种处理模式:LT模式与 ET 模式。
LT模式
LT,Level Triggered,水平触发模式。即只要内核进程的就绪通知由于某种原因暂时没有被 epoll 处理,则该内核进程就会定时将其就绪信息通知 epoll。直到 epoll 将其写入到就绪队列,或由于某种原因该内核进程又不再就绪而不再通知。其支持两种通讯方式:BIO与NIO。
ET模式
ET,Edge Triggered,边缘触发模式。其仅支持 NIO 的通讯方式。当内核进程的就绪信息仅会通知一次 epoll,无论 epoll 是否处理该通知。明显该方式的效率要高于 LT 模式,但其有可能会出现就绪通知被忽视的情况,即连接请求丢失的情况。
Nginx的并发处理机制
一般情况下并发处理机制有三种:多进程、多线程,与异步机制。Nginx 对于并发的处理同时采用了三种机制。当然,其异步机制使用的是异步非阻塞方式。
我们知道 Nginx 的进程分为两类:master 进程与 worker 进程。每个 master 进程可以生成多个 worker 进程,所以其是多进程的。其中master进程负责worker进程的生命周期,接受外部命令,解析perl脚本等。Worker进程负责接收和处理用户请求。
每个 worker 进程可以同时处理多个用户请求,每个用户请求会由一个线程来处理,所以其是多线程的。
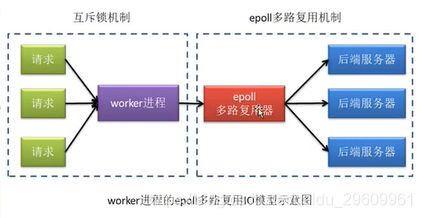
那么,如何解释其“异步非阻塞”并发处理机制呢?
worker 进程采用的就是 epoll 多路复用机制来对后端服务器进行处理的。当后端服务器返回结果后,后端服务器就会回调 epoll 多路复用器,由多路复用器对相应的 worker 进程进行通知。此时,worker 进程就会挂起当前正在处理的事务,拿 IO 返回结果去响应客户端请求。响应完毕后,会再继续执行挂起的事务。这个过程就是“异步非阻塞”的。