实在智能RPA学院|“猜心思”的Hard模式:问答系统在智能法律场景的实践与优化

导读:问答系统是自然语言处理领域一个很经典的问题,它用于回答人们以自然语言形式提出的问题,有着广泛的应用。例如其应用场景有:智能语音交互、在线客服、知识获取、情感类聊天等。常见的分类有:生成型、检索型问答系统;单轮问答、多轮问答系统;面向开放领域、特定领域的问答系统;完成任务型、纯聊天型的问答系统。
本文介绍的主要是我们在检索型、面向特定领域的问答系统,在落地过程中的尝试与思考。我们首先会简要的回顾一下检索型问答系统的框架、学习过程、常见模型。
业界做法
问答系统的核心:构建知识库,识别用户意图,匹配知识库
咨询问答的业界做法:
1. 从以往的数据中,通过数据挖掘方式(聚类、关键词),得业务中的高频问题
2. 从将高频的问题提炼出标准问题
3. 业务专家给标准问题配上标准答案
4. 上线后持续挖掘用户问题,将新的问题加入到知识库中。

01
框架:
问题—>
问题分析后得到查询(query)—>
搜索引擎召回—>
模型排序后选出答案
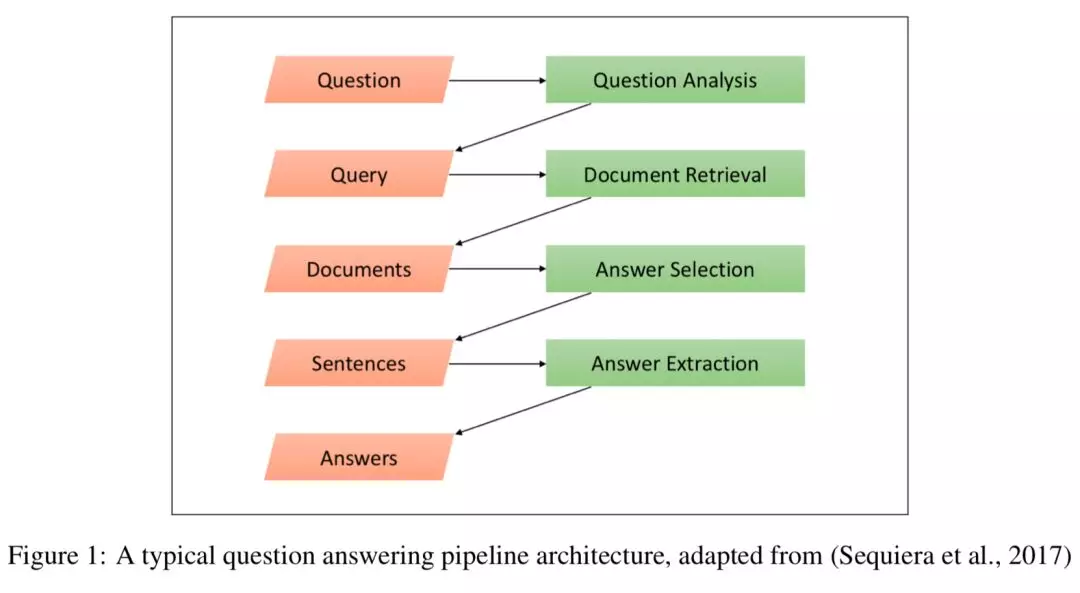
一、学习方式
给定一个问题和一系列候选项,任务的目标是,找到能回答问题的正确的答案。
(1) 转化为二分类学习问题(pointwise)
输入:
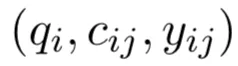
输入是一个(问题,候选问题,标签)
一个问题,对应正确的答案,标签为1;对应其他的答案,标签为0

训练:
学习到一个函数,当给定一个问题和一个候选答案时,能正确的预测出答案。
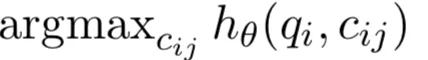
预测:
给定一个问题和一系列候选答案,找到概率最高的答案,并将这个答案做为结果返回。
(2)转行为成对学习问题(pairwise即结合正例与负例)
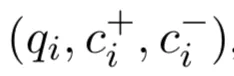
输入是一个(问题,正确的答案,错误的答案)
训练(hinge loss):

训练过程是,要确保模型预测问题与正确答案的概率要大于问题与错误答案的概率,并且需要超过一个的阀值(m)。即h(q,c+)-h(q,c_)>m。
这里的概率,可以用相似性度量。如典型的余弦相似性。计算方式如下, A和B是两个向量,一个代表问题的向量,另一个代表答案的向量。
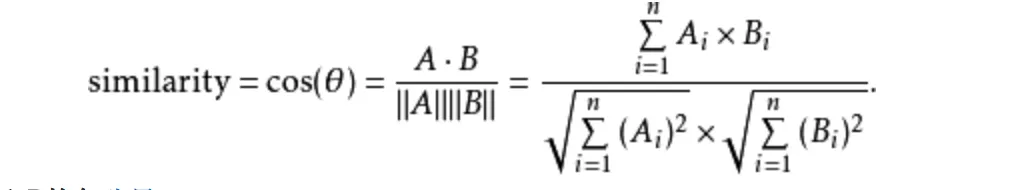
02
二、模型:双塔型架构、双塔型架构+注意力机制的架构、比较与汇总架构 [2]
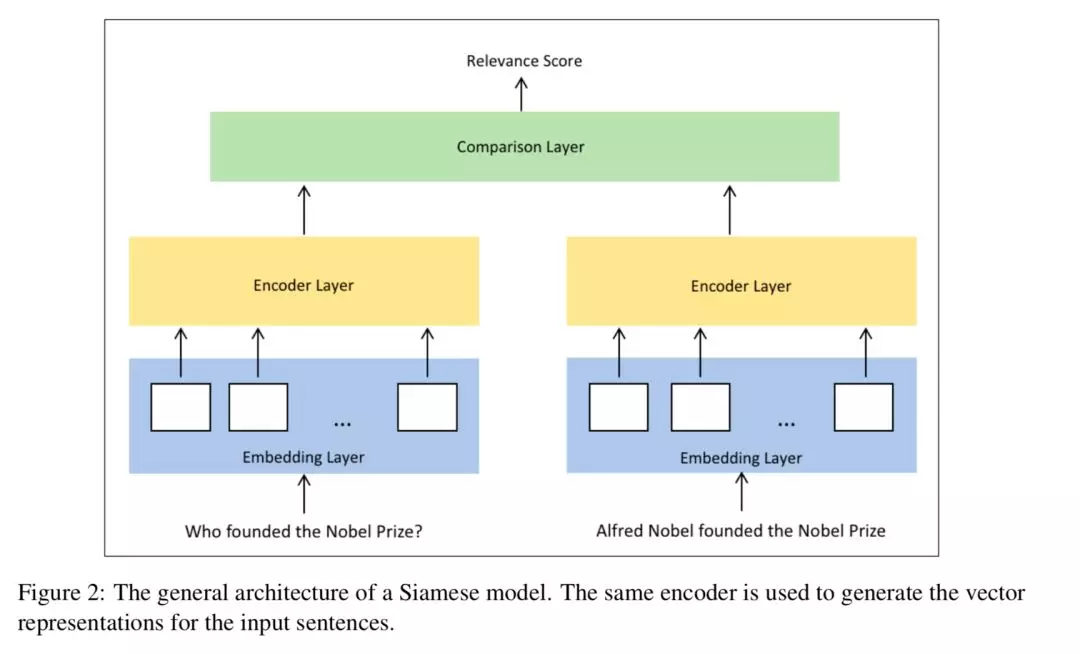
1、双塔型架构即Siamese Architecture。
问题和答案都采用相同的结构做表示,然后通过一个网络层将两者结合在一起,并计算一个相关系数,见下图。
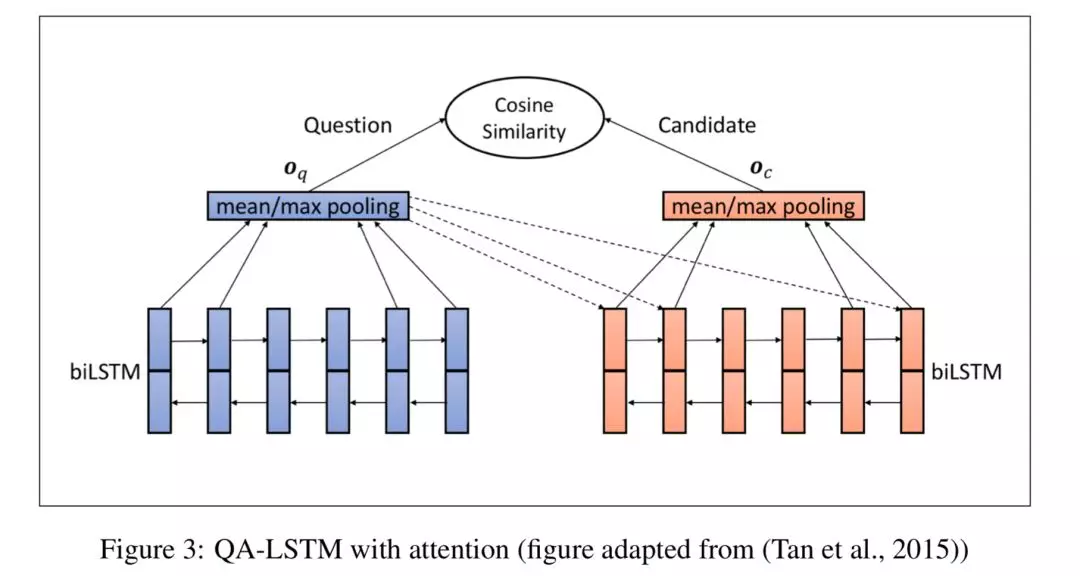
2、结合了注意力机制的双塔性架构即Attentive Architecture
问题和答案采取类似的结构做句子表示。但答案和问题表示有一定的交互,见右图[1],即在得到候选答案的表示过程中结合了问题的信息。在候选答案的表示过程中,注意力机制给予与问题相关的词语更多的权重。
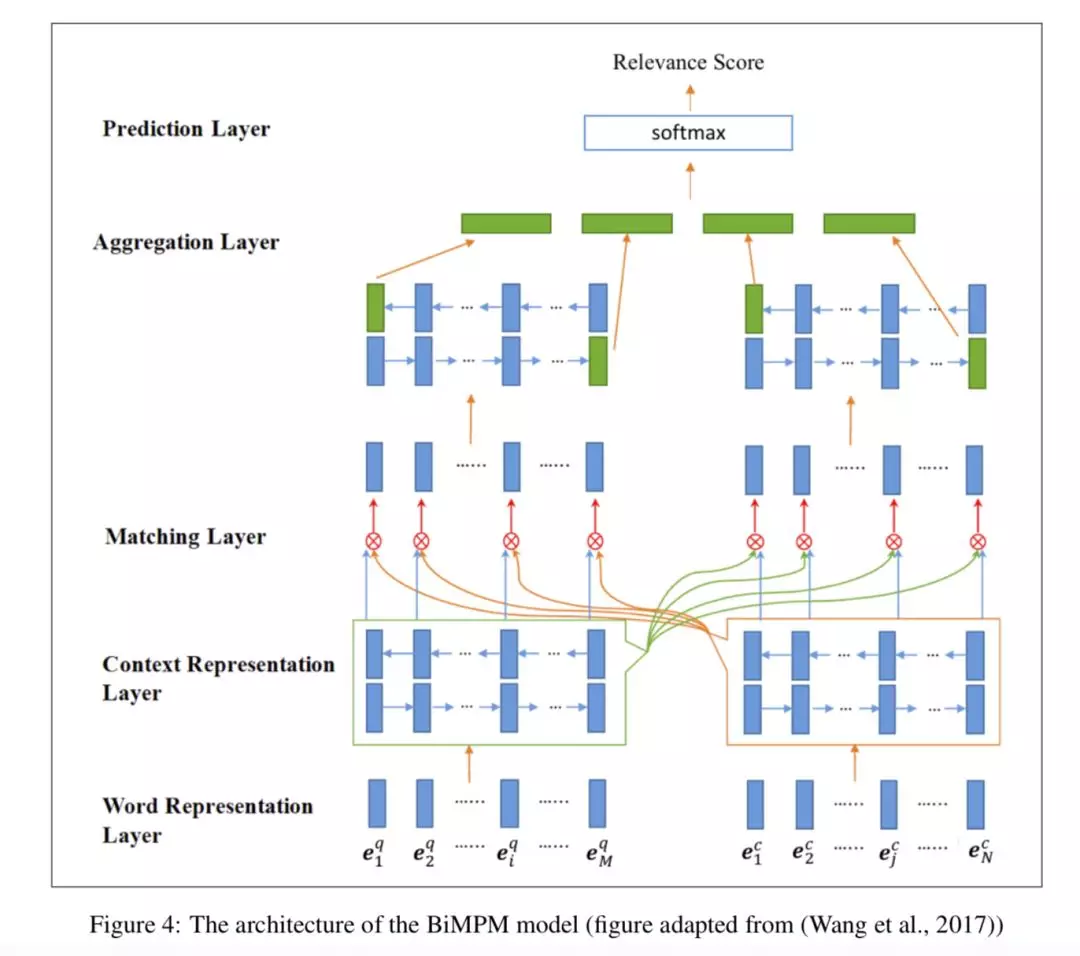
3、比较汇总的架构即Compare-Aggregate Architecture.
在这种框架中[5],不仅答案的表示结合了问题的信息,在形成问题的表示过程中也结合了答案的信息(compare阶段); 后续的层,还将比较阶段获得的信息,进一步的汇总(aggregate),然后再去做相关性打分。
03
三、评价指标
MAP(Mean Average Precision):单个主题的平均准确率是每篇相关文档检索出后的准确率平均值。
主集合的平均准确率(MAP)是每个主题平均准确率的平均值。
MAP 是反映系统在全部相关文档上性能的单值指标。
系统检索出来的相关文档越靠前(rank 越高),MAP就可能越高。如果系统没有返回相关文档,则准确率默认为0。
例子:假设有两个主题,主题1有4个相关网页,主题2有5个相关网页,计算MAP值。
系统对于主题1检索出4个相关网页,其rank分别为1, 2, 4, 7;
对于主题2检索出3个相关网页,其rank分别为1,3,5。
对于主题1,平均准确率为(1/1+2/2+3/4+4/7)/4=0.83。对于主题2,平均准确率为(1/1+2/3+3/5+0+0)/5=0.45。则MAP=(0.83+0.45)/2=0.64。
我们做的工作:
任务描述、落地过程、模型、优化过程、后续改进方向
任务描述:
这是一个问答任务,但每一个问题对应多个答案,平均有3个答案,事先不知道哪个答案更好。
给定一个问题,有多个候选问题,每个候选问题有多个答案,我们要选出一个最好的答案。
我们的任务场景与[2]中Community Question Answering(cQA)任务一致。SemEval-2016 cQA challenge,里面有是3个子任务,Sub- task A (Question-Comment Similarity即问题与答案的相关度), Subtask B (Question-Question Similarity即问题与后续问题的相关度) ,Subtask C (Question-External Comment Similarity即改本篇文章描述的任务) 。具体见参考资料和论文。
01
一、落地过程
任务类型与源数据获取、数据筛选、问答模型与优化、质检
1、获取数据:获取大量的公开的专业问答数据;规模在千万级。数据字段包括:问题、答案、问题类型即纠纷类型。
2、数据筛选:将一些有问题的数据并过滤掉。有问题的数据包括但不限于:过短过长的回复、太过笼统的回复、带有广告内容等。
3、问答模型与优化:这是主要的工作部分。提供了baseline模型,并在baseline模型基础上做优化。在下一部分即【问题模型的主要部分】重点展开。
4、质检:对答案质量的评估与badcase的分析。
有法律背景的同学在测试集上模型预测效果的分析,并报告相关性的指标以及错误的主要类型,以便明确效果并确定改进方向。
对模型预测打上相应的标签,分成三类(-1,0,1)。1:答案正确的回答了用户的问题;0:答案回答对了用户问的方向,但还不适应用户的特定场景;-1:回复的与问题没有什么明显的关联性。
我们报告的相关性,是0和1的这两部分占所有测试样本的比例。
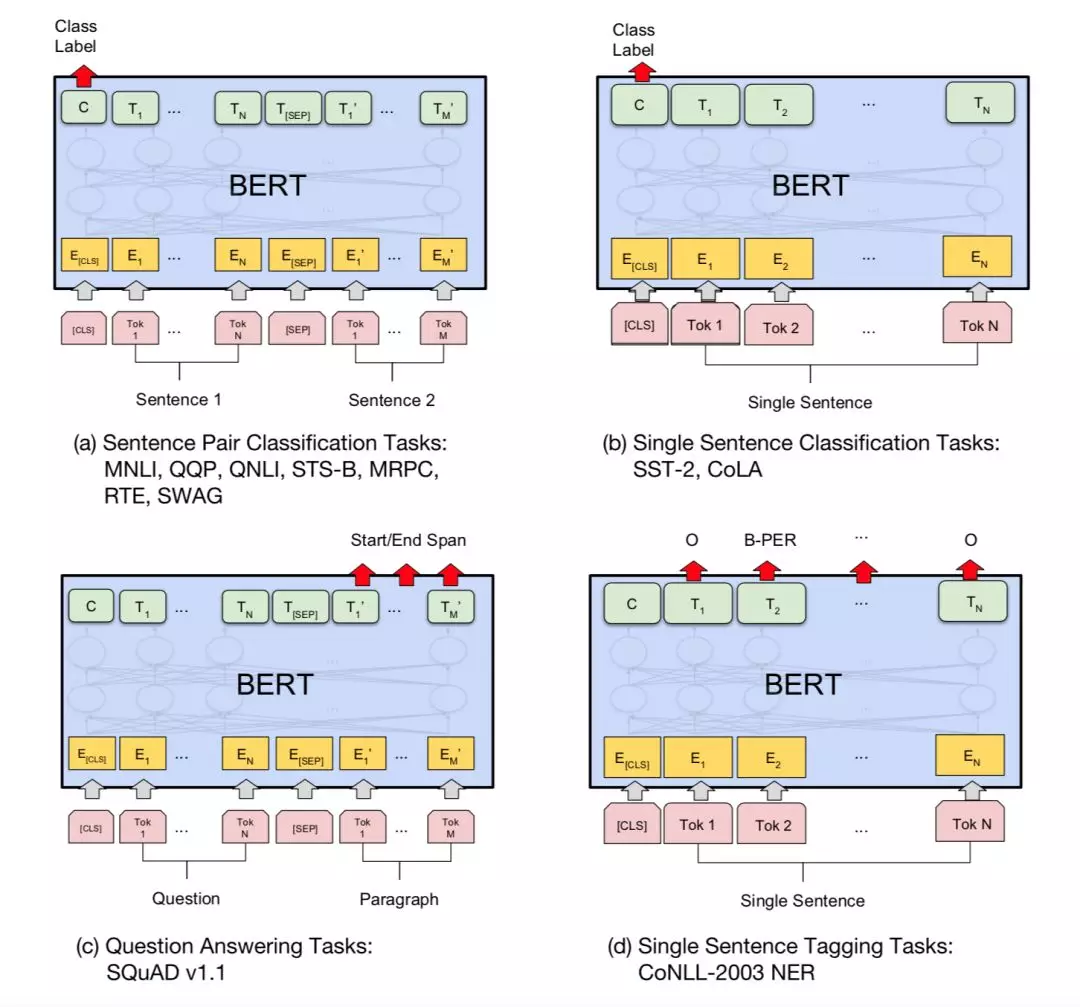
02
二、问答模型的主要部分:
召回、问题与问题相似性模型(q2q)、问题与答案相关性模型(q2a)
1.召回模块:句子改写、搜索
(1) 句子改写。用户的问题可能包含了很多信息,比较杂乱,导致不容易抓到重点。我们结合了三部分的信息:a.关键词; b.用户的问询点即代表用户问询的内容; c.词性和词汇表过滤后的句子信息,使得保留原始的主体信息。词汇表结合了词语的频率和tf-idf的分数。
(2) 搜索得到候选项(如20-50个)
2. 候选答案过滤
低质量答案的在线过滤。经过了召回后,候选答案任然有一定的概率出现不适合显示的答案。这时候就以在线的形式结合一定的规则将这些答案从候选答案中排除。
3. 两阶段排序
(1)问题与问题相似性模型(q2q)
训练阶段:构建监督学习任务1
通过输入问题(q)预测类型(t)来训练模型,监督学习的方式,从而使模型具有较好句子表示能力。
使用了筛选出了300万左右数据。
预测阶段:计算问题与候选问题的句子余弦相似性,值在0-1.0之间。候选问题与原有问题相似度越高排名越靠前。
(2)问题与答案相关性模型(q2a)
训练阶段:构建监督学习任务2
通过训练问题(q)与答案(a)的相关性模型,获得问题与答案相关性的预测能力,进而得到答案与问题相关性的概率。使用了筛选出了500万左右数据。候选答案与问题相关性越高,排名越靠前。
(3)加权排序:结合问题与问题相似性模型(q2q)、问题与答案相关性模型(q2a),并按照一定权重将两者结合起来。
在实际中问题与问题相似性模型占的权重较大一些。但因为我们的问题同时对应多个答案,平均有3个答案,多的有10个答案。即使找到个最相关的问题,我们还需要找到最好的答案。通过问题与答案相关性模型,系统能自动的筛选出与问题更有关联性的答案,并且一定程度上降低低质量或信息量少的答案被选中的概率。
03
(1) baseline模型(v0.1): 原句搜索+tfidf & word2vec: 48%
我们的baseline模型是,原句分词后es搜索召回,在问答语料上利用word2vec训练得到词向量,结合tf-idf的权重,得到句子的表示;并使用余弦相似性,对问题类型与候选问题做相似度排序。
(2) baseline改进版(v0.2):原句搜索+tfidf & word2vec+q2a_similarity: 55%
在baseline的基础上,我们额外结合了问题与答案的相关性模型(q2a_similarity)排序,以便从一个问题的多个答案中找出具有较高质量的答案。
(3) baseline改进版(v0.2): 原句搜索+tfidf & word2vec+问题与答案相关性模型(调整权重): 57%
在badcase分析中,虽然问题与答案的相关性模型(q2q_similiarity)对提升有帮助,但我们发现问题与问题的相似度,对于找出最佳答案的影响更大。
(4) 句子改写+q2q_bert+q2a_bert: 73%
在badcase的分析中,我们进一步发现,用户的问题有很大的比例描述的比较繁杂,或者说描述了很多的信息但对回答特别有帮助的信息却只在某一部分。我们的召回或排序模型,在很多信息中很容易迷失重点和方向。所以,我们进入了句子改写。改写后输入召回模块的信息有:关键词、用户的问询点、过滤后的句子主体信息;
另外我们的第一阶段排序使用的tf-idf结合word2vec的模型,给出的相似度倾向于非常高,没有很好的区分性。所以我们使用了监督学习的方式,结合正例和负例来训练模型,再做相似度打分。
这两个工作,显著的提升了问答系统的效果(相关性指标提升了16%)。
(5) 句子改写+q2q_bert+q2a_bert+结合意图识别
在智能法律的其他任务中,我们结合了意图识别的结果,对应一个用户的问题,我们会去识别它的纠纷类型和诉求。如果得到一定的置信度,我们会把这类信息结合进我们的模型,发现预测的结果一般都落在了这类纠纷类型和诉求相关的结果中,效果也有比较好的提升。那么我们也计划在问答系统中结合进意图识别的结果,后续会做质检分析并报告相关性指标。
04
四、后续改进方向
(1) 先过滤再排序。先过滤出较高质量数据,再结合问题与候选问题的相似度模型来排序
在我们的方案中,是使用了全量的数据。这样虽然有很多的数据,但有一定比例的数据本身质量不是太好,导致预测出的答案有事也有不太好。那么我们是否可以先过滤出质量高的数据,在给模型做相关打分呢?过滤的依据,可以是问答和答案的相关性,如使用一部分数据做训练得到模型,在另一部分未训练过的数据上做相关性打分。
(2)识别意图,支持含多个意图的问询的回答
这里的识别意图,是在结合运营梳理的高频纠纷类型和诉求下的热门问题,将一些问题打上标签。那么当预测到多个标签的时候,我们也会结合相应的回答,给出多个子的结果,并汇总在一起。
(3)结合生成型问答模型
到我们为止,我们介绍的都是检索型问答系统中做的工作。检索型的方式,比较务实、可靠,但并不能回答没有见过的问题;生成型问题,结合大量的训练数据和先进的序列到序列的模型,在一些特定的情况下,可以给出一些智能的回答。我们也将做这方面的尝试,并部分结合进来。
(4)结合上下文
刚才和大家介绍的主要是一问一答的系统即单轮模型。要想更加智能,需要结合对话的上下文来回答用户问题。结合一些场景的需要,我们也可以做一些尝试。这里的重点是要将用户之前说的话,特别是用户最近说的话结合进来,并且考虑回复的信息量。感兴趣的读者可以参考[6]。
05
感谢
虽然还有很多工作要做、系统也还很不完善,但也要先感谢数据团队提供的大量数据并配合数据清洗服务,这样我们才有了比较好的大量的原材料。
特别感谢运营团队的质检、分析并提供反馈,有了他们的工作,我们才能比较客观的评估系统的实际表现、模型优化的效果以及获得改进模型的灵感。
参考资料:(如需查阅参考资料,请复制一下链接到浏览器进行访问)
[1]. LSTM-based deep learning models for non-factoid answer selection
[2]. A Review on Deep Learning Techniques Applied to Answer Selection
[3].BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
[4]. APPLYING DEEP LEARNING TO ANSWER SELECTION: A STUDY AND AN OPEN TASK
[5].Bilateral Multi-Perspective Matching for Natural Language Sentences
[5]. 蚂蚁金服张家兴:金融智能—蚂蚁金服的人工智能实践
[6].搜索引擎中的Query改写Keyword技术研究
[7]. 2018-JDDC大赛季军(feel free)解决方案