canal 1.1.4 小记
Canal 1.1.4 小记
一 安装前准备
链接 CSDN canal同步mysql数据到es、oracle、mq、redis和mysql中
链接 博客园 canal的使用记录 (工作方式及链接方式)
Canal github
链接 Canal 的参数
链接 阿里 canal 的理解
链接 Canal数据库同步组件
链接 canal 概述
deployer : 相当于服务端
adapater : canal 插件(rdb 关系型数据库,MySQL、阿里云关系型数据库RDS ; ES 和 HBase )
admin : canal 可视化界面
链接下载路径
 只使用了 deployer 和adapter,下载后解压到指定目录即可
只使用了 deployer 和adapter,下载后解压到指定目录即可
二 使用
1 启动 deploy
deployer server 在启动时会扫描 conf/ 目录下启动对应的 instance 实例(example,example1 )。
#example 解压就存在
cp example example1
cd example1

################################################
## mysql serverId , v1.0.26+ will autoGen
#多个实例与数据库id 不能重复 唯一值 没填没有报错
# canal.instance.mysql.slaveId=0
# enable gtid use true/false
# 是否开启 GTID模式 (全局事务ID 在数据库架构M-S,防止主从binlog位点不一致情况下,找不到位点的问题)
canal.instance.gtidon=false
# position info 配置的数据库路径
canal.instance.master.address=192.168.142.112:3306
canal.instance.master.journal.name=
canal.instance.master.position=
canal.instance.master.timestamp=
canal.instance.master.gtid=
# rds oss binlog 读取阿里云RDS的binlog需要进行配置的
canal.instance.rds.accesskey=
canal.instance.rds.secretkey=
canal.instance.rds.instanceId=
# table meta tsdb info
canal.instance.tsdb.enable=true
#canal.instance.tsdb.url=jdbc:mysql://127.0.0.1:3306/canal_tsdb
#canal.instance.tsdb.dbUsername=canal
#canal.instance.tsdb.dbPassword=canal
#canal.instance.standby.address =
#canal.instance.standby.journal.name =
#canal.instance.standby.position =
#canal.instance.standby.timestamp =
#canal.instance.standby.gtid=
# username/password 数据库的密码,或者单独设置专为canal使用的账号
canal.instance.dbUsername=root
canal.instance.dbPassword=root
canal.instance.connectionCharset = UTF-8
# enable druid Decrypt database password
canal.instance.enableDruid=false
#canal.instance.pwdPublicKey=MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBALK4BUxdDltRRE5/zXpVEVPUgunvscYFtEip3pmLlhrWpacX7y7GCMo2/JM6LeHmiiNdH1FWgGCpUfircSwlWKUCAwEAAQ==
# table regex 过滤正则匹配 mysql 数据解析关注的表,Perl正则表达式.多个正则之间以逗号(,)分隔,转义符需要双斜杠(\\)
#常见例子:
#1. 所有表:.* or .*\\..*
#2. canal schema下所有表: canal\\..*
#3. canal下的以canal打头的表:canal\\.canal.*
#4. canal schema下的一张表:canal.test1
#5. 多个规则组合使用:canal\\..*,mysql.test1,mysql.test2 (逗号分隔)
canal.instance.filter.regex=.*\\..*
# table black regex 白名单
canal.instance.filter.black.regex=
# table field filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.field=test1.t_product:id/subject/keywords,test2.t_company:id/name/contact/ch
# table field black filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.black.field=test1.t_product:subject/product_image,test2.t_company:id/name/contact/ch
# mq config 实例名
canal.mq.topic=example1
# dynamic topic route by schema or table regex
#canal.mq.dynamicTopic=mytest1.user,mytest2\\..*,.*\\..*
#为消息队列时可设置分区
canal.mq.partition=0
# hash partition config
#canal.mq.partitionsNum=3
#canal.mq.partitionHash=test.table:id^name,.*\\..*
#################################################
--为数据库新建 canal 用户
CREATE USER canal IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
-- GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' ;
FLUSH PRIVILEGES;
链接 canal GTID 模式的介绍与使用
vim canal.properties

#################################################
######### destinations #############
#################################################
#canal 实例
canal.destinations = example,example1
# conf root dir conf路径 canal实例路径在conf下
canal.conf.dir = ../conf
# auto scan instance dir add/remove and start/stop instance
#开启扫描 instance 实例及多久扫描一次
canal.auto.scan = true
canal.auto.scan.interval = 5
#canal的spring配置路径??
canal.instance.tsdb.spring.xml = classpath:spring/tsdb/h2-tsdb.xml
#canal.instance.tsdb.spring.xml = classpath:spring/tsdb/mysql-tsdb.xml
canal.instance.global.mode = spring
canal.instance.global.lazy = false
canal.instance.global.manager.address = ${canal.admin.manager}
#canal.instance.global.spring.xml = classpath:spring/memory-instance.xml
canal.instance.global.spring.xml = classpath:spring/file-instance.xml
#canal.instance.global.spring.xml = classpath:spring/default-instance.xml
#启动 deploy
../bin/startup.sh
#启动完成后会自动生成 canal.pid 文件,里面是进程id 可jps查看进程
#在logs/实例名称/example.log 无报错 或者使用GitHub的例子连接 deplpy
#会在 conf/example/ 目录下生成 meta.dat 文件(第一次启用时,不会生成) 记录配置位置等信息。h2.mv.db 文件记录 binlog 信息。在 logs/canal/canal.log 里看到启动成功了哪些实例

1 canal.properties四种模式
#canal.instance.global.spring.xml = classpath:spring/local-instance.xml
#canal.instance.global.spring.xml = classpath:spring/memory-instance.xml
canal.instance.global.spring.xml = classpath:spring/file-instance.xml
#canal.instance.global.spring.xml = classpath:spring/default-instance.xml
local-instance.xml 本地
memory-instance.xml 所有的组件(parser , sink , store)都选择了内存版模式,记录位点的都选择了memory模式,重启后又会回到初始位点进行解析
特点:速度最快,依赖最少(不需要zookeeper)
场景:一般应用在quickstart,或者是出现问题后,进行数据分析的场景,不应该将其应用于生产环境。
个人建议是调试的时候使用该模式,即新增数据的时候,客户端能马上捕获到改日志,但是由于位点一直都是canal启动的时候最新的,不适用与生产环境。
file-instance.xml 所有的组件(parser , sink , store)都选择了基于file持久化模式,注意,不支持HA机制.
特点:支持单机持久化
场景:生产环境,无HA需求,简单可用.
采用该模式的时候,如果关闭了canal,会在destination中生成一个meta.dat,用来记录关键信息。如果想要启动canal之后马上订阅最新的位点,需要把该文件删掉。
{“clientDatas”:[{“clientIdentity”:{“clientId”:1001,“destination”:“example”,“filter”:"…"},“cursor”:{“identity”:{“slaveId”:-1,“sourceAddress”:{“address”:“192.168.6.71”,“port”:3306}},“postion”:{“included”:false,“journalName”:“binlog.008335”,“position”:221691106,“serverId”:88888,“timestamp”:1524294834000}}}],“destination”:“example”}
default-instance.xml 所有的组件(parser , sink , store)都选择了持久化模式,目前持久化的方式主要是写入zookeeper,保证数据集群共享。
特点:支持HA
场景:生产环境,集群化部署.
该模式会记录集群中所有运行的节点,主要用与HA主备模式,节点中的数据如下,可以关闭某一个canal服务来查看running的变化信息。
2 启动 adaptor
使用canal 将mysql的数据同步到 RDS (阿里云类 Mysql 数据库)上。adaptor 支持对RDB(关系型数据库),同步多表数据到RDS上。只要源mysql开启 binlog 同步数据后的数据库不需要开启binlog(通过sql将数据写入)。可以使用配置多个实例,每个实例只监测一张表;或者一个实例同时监测多张表
vim ./conf/application.yml
server:
port: 8081
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
default-property-inclusion: non_null
canal.conf:
mode: tcp # kafka rocketMQ (消息队列)
canalServerHost: 192.168.142.112:11111
# zookeeperHosts: slave1:2181
# mqServers: 127.0.0.1:9092 #or rocketmq
# flatMessage: true
batchSize: 500
syncBatchSize: 1000
retries: 0
timeout:
accessKey:
secretKey:
#配置 源数据库路径
srcDataSources:
defaultDS:
url: jdbc:mysql://192.168.142.112:3306/test_data
username: root
password: root
#配置实例及从库
canalAdapters:
- instance: example # canal instance Name or mq topic name 实例名
groups:
- groupId: test_g2
outerAdapters:
- name: logger
- name: rdb
key: mysql3
properties:
jdbc.driverClassName: com.mysql.jdbc.Driver
jdbc.url: jdbc:mysql://192.168.142.100:3306/test_5
jdbc.username: root
jdbc.password: root
#配置实例及从库
- instance: example1 # canal instance Name or mq topic name 实例名
groups:
- groupId: test_g3
outerAdapters:
- name: logger
- name: rdb
key: mysql4
properties:
jdbc.driverClassName: com.mysql.jdbc.Driver
jdbc.url: jdbc:mysql://192.168.142.100:3306/test_5
jdbc.username: root
jdbc.password: root
两个实例监测两表 需要在 rdb下 新建两个 yml 文件
一个实例监测多表也需要对每一表新建一个yml文件
vim ../conf/rdb/my_user.yml
dataSourceKey: defaultDS
destination: example1 #实例名 groupID与上一个配置文件要对应
groupId: test_g3
outerAdapterKey: mysql4 #重复无影响
concurrent: true #并发?
dbMapping:
#监测的数据库及表
database: test_data
table: student_2
#被传递数据到的 数据库.表
targetTable: test_5.student_2
#主键 源表: 从表
targetPk:
id: id
#列名一致时 直接为true 不一致注释掉
mapAll: true
# targetColumns: #手动输入源表与从表列与列的对应关系 源表: 从表
# id: id
etlCondition: "where c_time>={}"
commitBatch: 3000 # 批量提交的大小
#开启 adaptor
../bin/startup.sh
#启动完成后会自动生成 adapter.pid 文件,里面是进程id 可jps查看进程 如果能正常启动 application.yml文件配置应该没问题,数据不能正常同步则是 test_user.yml 配置文件的问题 正常同步会打印出一条 info 和一条debug 日志
3 补充 canal admin 的使用
1 配置 canal-admin
下载 canal-admin 1.1.14 版本 并解压在指定文件夹
vim /conf/application.yml
server:
#原为 8089 报端口冲突,修改端口为8090
port: 8090
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
spring.datasource:
#canal admin 会在mysql中新建一个数据库,并需要在mysql里执行一个sql脚本
address: 127.0.0.1:3306
database: canal_manager
username: root
password:
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://${spring.datasource.address}/${spring.datasource.database}?useUnicode=true&characterEncoding=UTF-8&useSSL=false
hikari:
maximum-pool-size: 30
minimum-idle: 1
canal:
#admin 的账户和密码
adminUser: admin
adminPasswd: 123456
登录 mysql 执行 /conf/canal_manager.sql (创建数据库,表;可修改)
source /data/canal/admin/conf/canal_manager.sql
2 修改 canal-deployer
vim /test/canal_admin/deployer/conf/canal_local.properties
# register ip;运行canal-server的服务的主机IP,不用配置,自动绑定本机IP
canal.register.ip =
# canal admin config
canal.admin.manager = 192.168.142.112:8089
canal.admin.port = 11110
canal.admin.user = admin
#密码 123456 的 秘钥
canal.admin.passwd = 6BB4837EB74329105EE4568DDA7DC67ED2CA2AD9
# admin auto register
canal.admin.register.auto = true
canal.admin.register.cluster =
启动 canal-deployer (先启动 canal-admin 再启动 canal-deployer )
#启动admin
./startup.sh
#启动deployer
./startup.sh local
3 web 界面配置

1 instance:对应 canal-server 里的 instance ,最小订阅 mysql 的队列 实例
2 sever:对应 canal-server ,一个 server 管理多个 instance 实例
3 集群:对应一组 canal-server,组合在一起面向高可用的 HA 运维
ps.
-
instance因为是最原始的业务订阅诉求,它会和 server/集群 这两个面向资源服务属性的进行关联,比如instance A绑定到server A上或者集群 A上,
-
有了任务和资源的绑定关系后,对应的资源服务就会接收到这个任务配置,在对应的资源上动态加载instance,并提供服务
- 动态加载的过程,有点类似于之前的autoScan机制,只不过基于canal-admin之后可就以变为远程的web操作,而不需要在机器上运维配置文件
-
将server抽象成资源之后,原本canal-server运行所需要的canal.properties/instance.properties配置文件就需要在web ui上进行统一运维,每个server只需要以最基本的启动配置 (比如知道一下canal-admin的manager地址,以及访问配置的账号、密码即可)
在 instance 配置修改配置文件重启instance完成配置
canal admin 界面新建server ip为唯一值

集群管理 => 主配置 (canal.properties ) 集群管理需要 zookeeper 地址
测试 HA (topic:example)
#启动 zk 客户端
zkCli.sh
get /otter/canal/destinations/example/running

canal配合kafka使用
canal高可用的数据重复消费问题,自动切换时消费端数据重复消费,canal高可用的搭建,运用以及问题,以及元数据保存问题,保存zookeeper清除
Canal HA 切换数据重复发送
canal HA, A,B两个instance, A为主, 持续获取binlog, 并将位点记录到zk, 但是这个做不到像mysql主从一样sql_thread应用完后原子更新mysql.slave_relay_log_info表, 于是就会有消费binlog到点11而zk只记录到5的情况, 那么此时A宕机, B实例接管后从zk获取位点信息就是从5开始消费binlog, 就会造成重复binlog.理论上我理解flush位点信息到zk频率由参数canal.zookeeper.flush.period控制, 默认1000ms刷一次
vim canal.properties
#1秒更新一次 1000ms
canal.zookeeper.flush.period = 1000
# canal.destination= 需要标明(不标明可能不会生效)
canal.zookeeper.flush.period = 1000,1秒更新一次
三 测试
使用 canal 同步 同一个集器的 mysql 的一个 databases 向另外十个 databases 同步数据
canal 不能监控一个数据源同时发送至多个(不同的)数据源上
在使用过程中只监控自己需要的表,减少产生的 binlog 有利于效率
deployer 的 instance.properties
canal.instance.filter.regex
mysql 数据解析关注的表,Perl正则表达式.
多个正则之间以逗号(,)分隔,转义符需要双斜杠(\)
常见例子:
- 所有表:.* or .\…
- canal schema下所有表: canal\…*
- canal下的以canal打头的表:canal\.canal.*
- canal schema下的一张表:canal.test1
- 多个规则组合使用:canal\…*,mysql.test1,mysql.test2 (逗号分隔)
**注意:此过滤条件只针对row模式的数据有效(ps. mixed/statement因为不解析sql,所以无法准确提取tableName进行过滤)
2 发送数据时 kill
条件: canal 正常运行; kafka 正常运行; 消费 kafka 程序正常打印出数据; mysql 每隔 1秒 插入数据 共 500 条数据
kill 掉全部的 kafka 进程;
恢复全部的 kafka 数据未出现 遗漏 。
条件: canal 正常运行; kafka 正常运行; 消费 kafka 程序正常打印出数据; mysql 每隔 1秒 插入数据 共 500 条数据
1 kill 掉 一个canal -deployer 主备切换
需要十几秒来完成主备切换。切换完成时,存在重复消费数据
2 恢复原有的canal-deployer 使用哪个deployer
会继续使用当前的deployer
3 全部kill掉 canal deployer进程
恢复进程会存在重复消费数据。(admin负责管理instance配置)
canal源码解析(2)—位点的实现
canal之Binlog的寻找过程
canal 在主备切换和重启会从binlog中重复消费位点?
报错
1 服务端开启,执行代码连接服务端
Exception in thread "main" com.alibaba.otter.canal.protocol.exception.CanalClientException: failed to subscribe with reason: something goes wrong with channel:[id: 0x6acd8daf, /10.253.6.161:65087 => /10.161.75.84:11111], exception=com.alibaba.otter.canal.server.exception.CanalServerException: destination:example1 should start first
代码(客户端) 连接不上服务端。1 查看 deployer 日志 是否有报错(进程是否存在) 2 代码中的 destination 不一致。尝试修改没修改成功,改回原来的example 运行正常
2 canal报错
[canal KILL DUMP 275 failure:](http://www.baidu.com/s?wd=canal KILL DUMP 275 failure:) 在某次重启了canal后报的错。原因是找不到binlog节点了 ,删除对应实例的conf下的dat文件 重新启动就可以了
3 重新启动 deployer 报错
2020-01-13 10:48:59.546 [destination = example , address = /10.161.12.72:8061 , EventParser] ERROR c.a.o.c.p.inbound.mysql.rds.RdsBinlogEventParserProxy - dump address /10.161.12.72:8061 has an error, retrying
. caused by
java.io.IOException: Received error packet: errno = 1236, sqlstate = HY000 errmsg = Could not find first log file name in binary log index file
at com.alibaba.otter.canal.parse.inbound.mysql.dbsync.DirectLogFetcher.fetch(DirectLogFetcher.java:102) ~[canal.parse-1.1.4.jar:na]
at com.alibaba.otter.canal.parse.inbound.mysql.MysqlConnection.dump(MysqlConnection.java:235) ~[canal.parse-1.1.4.jar:na]
at com.alibaba.otter.canal.parse.inbound.AbstractEventParser$3.run(AbstractEventParser.java:265) ~[canal.parse-1.1.4.jar:na]
at java.lang.Thread.run(Thread.java:745) [na:1.8.0_121]
2020-01-13 10:48:59.546 [destination = example , address = /10.161.12.72:8061 , EventParser] ERROR com.alibaba.otter.canal.common.alarm.LogAlarmHandler - destination:example[java.io.IOException: Received error
packet: errno = 1236, sqlstate = HY000 errmsg = Could not find first log file name in binary log index file
at com.alibaba.otter.canal.parse.inbound.mysql.dbsync.DirectLogFetcher.fetch(DirectLogFetcher.java:102)
at com.alibaba.otter.canal.parse.inbound.mysql.MysqlConnection.dump(MysqlConnection.java:235)
at com.alibaba.otter.canal.parse.inbound.AbstractEventParser$3.run(AbstractEventParser.java:265)
at java.lang.Thread.run(Thread.java:745)
记录的位置与 数据库的 位置不一致 找不到位置产生的错误。修改 meta.dat 文件里位置等信息。
-- 查看 mysql binlog 位置 --
show master status;
1 vim canal.properties
canal.destinations = test1
2 重置位点
在 使用 canal admin + zookeeper 时 由 zookeeper 负责管理位点

# zookeeper 客户端
zkCli.sh
#查看 zookeeper position信息 deatinationName:topicname
get /otter/canal/destinations/deatinationName/1001/cursor
#修改 position 信息
set /otter/canal/destinations/deatinationName/1001/cursor {
"@type":"com.alibaba.otter.canal.protocol.position.LogPosition","identity":{
"slaveId":-1,"sourceAddress":{
"address":"xx.xx.xx.xx","port":xxxx}},"postion":{
"included":false,"journalName":"mysql-bin.000906","position":141201179,"serverId":1,"timestamp":1571019574000}}
mysql+zookper+canal环境下修改position的方法
4 启动adapter报错

端口被占用,修改端口即可
5 对表的监控
-- truncate 监控表 不会引起从表的数据变化 --
TRUNCATE yun_test.canal_test;
-- delete,update 监控表 会引起从表对应数据的丢失
delete from yun_test.canal_test where id=1;
update yun_test.canal_test set a1=3,a2=3 where id=1;
-- 先truncate 表再插入一个主键相同其他列不同的数据,不会引起从表数据发生变化
6 启动 admin ui界面 报 重置连接错误
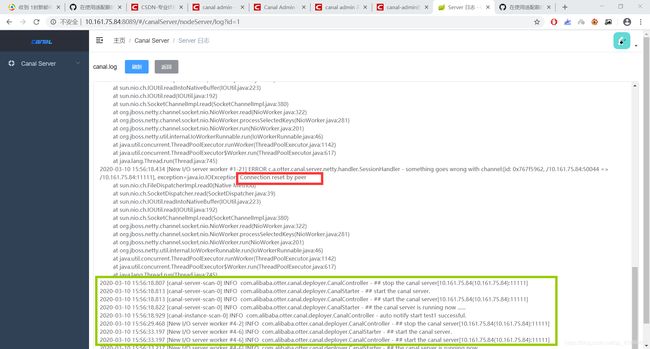
2020-03-10 15:56:18.434 [New I/O server worker #1-21] ERROR c.a.otter.canal.server.netty.handler.SessionHandler - something goes wrong with channel:[id: 0x767f5962, /10.161.75.84:50044 => /10.161.75.84:11111], exception=java.io.IOException: Connection reset by peer
在配置中 注释
7 canal-admin 启动 deployer 日志报错
异常字段不能为 modified_time not is null
#结果应该为 OFF
show variables like 'explicit_defaults_for_timestamp';

vim /etc/my.cnf
explicit_defaults_for_timestamp = false
小记
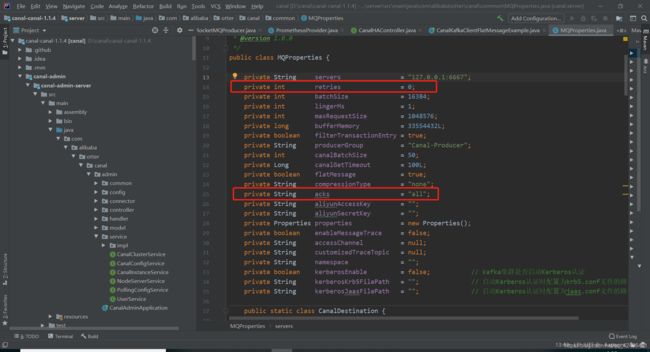
acks = all
首先这个acks参数,是在KafkaProducer,也就是生产者客户端里设置的也就是说,你往kafka写数据的时候,就可以来设置这个acks参数。
这个参数实际上有三种常见的值可以设置,分别是:0、1 和 all。
第一种选择是把acks参数设置为0
我的KafkaProducer在客户端,只要把消息发送出去,不管那条数据有没有在哪怕Partition Leader上落到磁盘,我就不管他了,直接就认为这个消息发送成功了。
如果你采用这种设置的话,那么你必须注意的一点是,可能你发送出去的消息还在半路。结果呢,Partition Leader所在Broker就直接挂了,然后结果你的客户端还认为消息发送成功了,此时就会导致这条消息就丢失了。
第二种选择是设置 acks = 1
只要Partition Leader接收到消息而且写入本地磁盘了,就认为成功了,不管他其他的Follower有没有同步过去这条消息了。
这种设置其实是kafka默认的设置,大家请注意,划重点!这是默认的设置
也就是说,默认情况下,你要是不管acks这个参数,只要Partition Leader写成功就算成功。
但是这里有一个问题,万一Partition Leader刚刚接收到消息,Follower还没来得及同步过去,结果Leader所在的broker宕机了,此时也会导致这条消息丢失,因为人家客户端已经认为发送成功了。
最后一种情况,就是设置acks=all
Partition Leader接收到消息之后,还必须要求ISR列表里跟Leader保持同步的那些Follower都要把消息同步过去,才能认为这条消息是写入成功了。
如果说Partition Leader刚接收到了消息,但是结果Follower没有收到消息,此时Leader宕机了,那么客户端会感知到这个消息没发送成功,他会重试再次发送消息过去。
此时可能Partition 2的Follower变成Leader了,此时ISR列表里只有最新的这个Follower转变成的Leader了,那么只要这个新的Leader接收消息就算成功了。
acks=all 就可以代表数据一定不会丢失了吗?
当然不是,如果你的Partition只有一个副本,也就是一个Leader,任何Follower都没有,你认为acks=all有用吗?
当然没用了,因为ISR里就一个Leader,他接收完消息后宕机,也会导致数据丢失。
所以说,这个acks=all,必须跟ISR列表里至少有2个以上的副本配合使用,起码是有一个Leader和一个Follower才可以。
这样才能保证说写一条数据过去,一定是2个以上的副本都收到了才算是成功,此时任何一个副本宕机,不会导致数据丢失。