为什么80%的码农都做不了架构师?>>> 
Solr是一个基于Lucene的Java搜索引擎服务器。Solr 提供了层面搜索、命中醒目显示并且支持多种输出格式(包括 XML/XSLT 和 JSON 格式)。它易于安装和配置,而且附带了一个基于HTTP 的管理界面。Solr已经在众多大型的网站中使用,较为成熟和稳定。Solr 包装并扩展了Lucene,所以Solr的基本上沿用了Lucene的相关术语。更重要的是,Solr 创建的索引与 Lucene搜索引擎库完全兼容。通过对Solr 进行适当的配置,某些情况下可能需要进行编码,Solr 可以阅读和使用构建到其他 Lucene 应用程序中的索引。此外,很多 Lucene 工具(如Nutch、Luke)也可以使用Solr 创建的索引。
solr默认是不支持中文分词的,这样就需要我们手工配置中文分词器,在这里我们选用IK Analyzer中文分词器。
IK Analyzer下载地址:https://code.google.com/p/ik-analyzer/downloads/list
如图: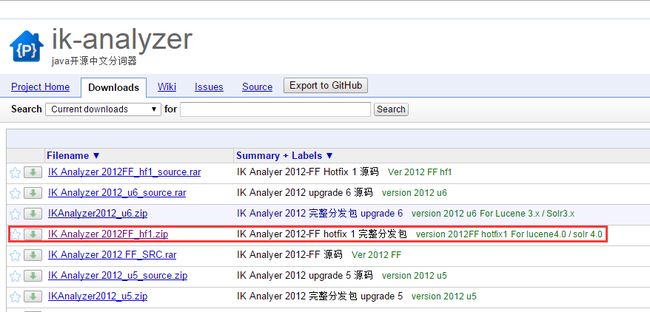
默认大家已经下载并解压了solr,在这里我们使用solr 4.10.4版本
试验环境centos 6.5 ,JDK1.7
整合步骤
1:解压下载的IK Analyzer_2012_FF_hf1.zip压缩包,把IKAnalyzer2012FF_u1.jar拷贝到solr-4.10.4/example/solr-webapp/webapp/WEB-INF/lib目录下
2:在solr-4.10.4/example/solr-webapp/webapp/WEB-INF目录下创建目录classes,然后把IKAnalyzer.cfg.xml和stopword.dic拷贝到新创建的classes目录下即可。
3:修改solr core的schema文件,默认是solr-4.10.4/example/solr/collection1/conf/schema.xml,添加如下配置
4:启动solr,bin/solr start
5:进入solr web界面http://localhost:8983/solr,看到下图操作结果即为配置成功
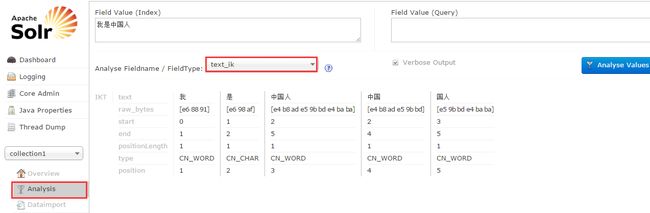
到现在为止,solr就和IK Analyzer中文分词器整合成功了。
但是,如果我想自定义一些词库,让IK分词器可以识别,那么就需要自定义扩展词库了。
操作步骤:
1:修改solr-4.10.4/example/solr-webapp/webapp/WEB-INF/classes目录下的IKAnalyzer.cfg.xml配置文件,添加如下配置
2:新建ext.dic文件,在里面添加如下内容(注意:ext.dic的编码必须是Encode in UTF-8 without BOM,否则自定义的词库不会被识别)
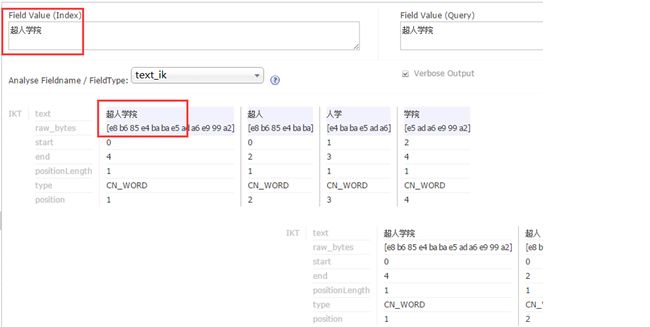
超人学院
3:重启solr
4:在solr web界面进行如下操作,看到图中操作结果即为配置成功。
更多精彩内容请访问:http://bbs.superwu.cn
关注超人学院微信二维码: