为什么80%的码农都做不了架构师?>>> 
当前IKAnalyzer从发布最后一个版本后就一直没有再更新,使用过程中,经常遇到需要扩展词库以及动态更新字典表的问题,此处给出一种解决办法(注意:本方法中的IKAnalyzer代码我已经将源码移植到了自己的工程中,目录结构也进行了修改):
1、将扩展字典表做成可动态生成:
1)、在IKAnalyzer.cfg.xml中添加扩展字典路径
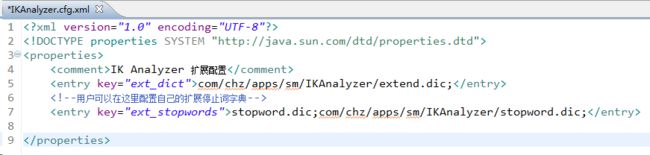
2)、在分词的时候,先采取动态生成上面两个字典表的方式进行更新,例如事先将字典词库放在数据表中,需要分词之前先更新字典。当然此方法只支持第一次调用的时候动态加载词库,如果服务没有重启之前,数据库中添加的词是不会进行重新加载的。下面是动态生成字典表的实现类:
package com.chz.apps.sm.IKAnalyzer; import java.io.ByteArrayInputStream; import java.io.IOException; import java.io.InputStream; import java.io.InputStreamReader; import java.io.Reader; import java.util.ArrayList; import java.util.List; import com.chz.apps.sm.model.IkanalyzerExtendModel; import com.chz.base.util.FileUtil; import com.chz.plugin.IKAnalyzer.core.IKSegmenter; import com.chz.plugin.IKAnalyzer.core.Lexeme; /** * @Description 分词工具类 * @author gongstring<[email protected]> * @createTime 2016年11月28日 下午2:46:06 */ public class IKAnalyzerTool { /** * 是否已经初始化过词库,如果没有,则会自动先调用词库 */ private static boolean init_words = false; /** * 扩展关键字 */ private static ListextendWords = new ArrayList (); /** * 停用关键字 */ private static List stopWords = new ArrayList (); /** * @Description 初始化词库以及停用词 * @author gongstring<[email protected]> * @createTime 2016年11月28日 下午2:29:59 */ public static void initWords(){ //从关键字表中查询扩展关键字,并生成到指定文件中 IKAnalyzerTool.extendWords = new ArrayList (); List extendWords = IkanalyzerExtendModel.dao.findByProperty("status", 1); String fileDirPath = IKAnalyzerTool.class.getResource("/com/chz/apps/sm/IKAnalyzer/").getPath(); String filePath = fileDirPath+"extend.dic"; FileUtil.removeFile(filePath);//先删除文件,此处重新生成 for (int i = 0; i < extendWords.size(); i++) { String txt = extendWords.get(i).getStr("extend_word"); FileUtil.appendToFile(filePath, txt,true); IKAnalyzerTool.extendWords.add(txt); } //从关键字表中查询停用关键字,并生成到指定文件中 IKAnalyzerTool.stopWords = new ArrayList (); List stopWords = IkanalyzerExtendModel.dao.findByProperty("status", 0); String stopFilePath = fileDirPath+"stopword.dic"; FileUtil.removeFile(stopFilePath);//先删除文件,此处重新生成 for (int i = 0; i < stopWords.size(); i++) { String txt = stopWords.get(i).getStr("extend_word"); FileUtil.appendToFile(stopFilePath, txt,true); IKAnalyzerTool.stopWords.add(txt); } init_words = true; } /** * @Description 分词操作 * @author gongstring<[email protected]> * @createTime 2016年11月28日 下午3:30:10 * @param str * @param justExist 是否只显示已经在词库中维护了的关键词 * @return */ public static List IKAnalysis(String str,boolean justExist) { List tmp = IKAnalysis(str); List result = new ArrayList (); if(justExist){ for (int i = 0; i < tmp.size(); i++) { if(IKAnalyzerTool.extendWords.contains(tmp.get(i))){ result.add(tmp.get(i)); } } }else{ result = tmp; } return result; } /** * @Description 根据字符串自动拆分成关键字集合 * @author gongstring<[email protected]> * @createTime 2016年11月28日 下午2:55:24 * @param str * @return */ public static List IKAnalysis(String str) { if(!init_words){ initWords(); } List result = new ArrayList (); try { // InputStream in = new FileInputStream(str);// byte[] bt = str.getBytes();// str InputStream ip = new ByteArrayInputStream(bt); Reader read = new InputStreamReader(ip); IKSegmenter iks = new IKSegmenter(read, true); Lexeme t; while ((t = iks.next()) != null) { result.add(t.getLexemeText()); } } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } return result; } }
2、修改源码,实现动态更新字典表。通过查看源码IKAnalyzer.dic.Dictionary.java文件得出,字典对象是采取单例模式,也就是第一次加载后,后续不在重新加载,这样即使字典表内容变化,缓存中的字典库是不会变更的,所以需要修改源码,可以手动更新静态对象的内容,此处我采取添加clear方法,在需要更新时候调用,将instance对象设置为null,下次调用字典的时候,程序就会自动加载了
/** * @Description 清空字典缓存,用于动态更新字典表 * @author gongstring<[email protected]> * @createTime 2016年11月29日 上午9:56:15 */ public static void clear(){ singleton = null; }

源码修改完后,可以选择编译重新打包,或者将jar包中的class文件删除,java类在工程中按照源目录存放。
3、手动调用,我这里是做的一个页面,点击更新字典库时,调用更新代码:
/** * @Description 刷新关键词缓存 * @author gongstring<[email protected]> * @createTime 2016年11月29日 上午9:33:49 */ public void refreshCache(){ IKAnalyzerTool.initWords();//重新加载词汇 Dictionary.clear();//将字典表缓存清空 this.renderSuccessJson(EnvConfig.APP_PATH+"/sm/ikanalyzerExtend"); }
4、可能存在的性能问题:由于词库一般会比较大,所以每次大批量更新可能会出现性能损耗。。。
注:本文转载自gongstring.com,转载目的在于传递更多信息,并不代表本网赞同其观点和对其真实性负责。如有侵权行为,请联系我们,我们会及时删除。