Pytorch学习——优化器
1.优化器的使用
pytorch的优化器在torch.optim中,使用时,先定义一个优化器,以adam为例:
optimizer = optim.Adam(
model.parameters(),
lr=config.TRAIN.LR,
)
在计算完每一个batch的网络输出后,优化参数时,首先需要将loss关于weight参数梯度置零:
optimizer.zero_grad() ## 梯度清零 preds = model(inputs) ## inference loss = criterion(preds, targets) ## 求解loss loss.backward() ## 反向传播求解梯度 optimizer.step() ## 更新权重参数
这一步是为了让每次更新需要的梯度只和当前batch有关,与之前的无关。
在知乎看到一个关于累加梯度,可以一定程度当成增大batchsize的做法,感觉挺有意思的,参考
https://www.zhihu.com/question/303070254/answer/573504133

2.学习率的调整
yTorch学习率调整策略通过torch.optim.lr_scheduler接口实现。
if isinstance(config.TRAIN.LR_STEP, list):
lr_scheduler = torch.optim.lr_scheduler.MultiStepLR(
optimizer, config.TRAIN.LR_STEP,
config.TRAIN.LR_FACTOR, -1
)
else:
lr_scheduler = torch.optim.lr_scheduler.StepLR(
optimizer, config.TRAIN.LR_STEP,
config.TRAIN.LR_FACTOR, last_epoch - 1
)
上面两个是指定间隔衰减。第一个参数是optimizer,第二个step实际上是训练的epoch,第三个是下降学习率乘以的因子,第四个是第几个epoch数。
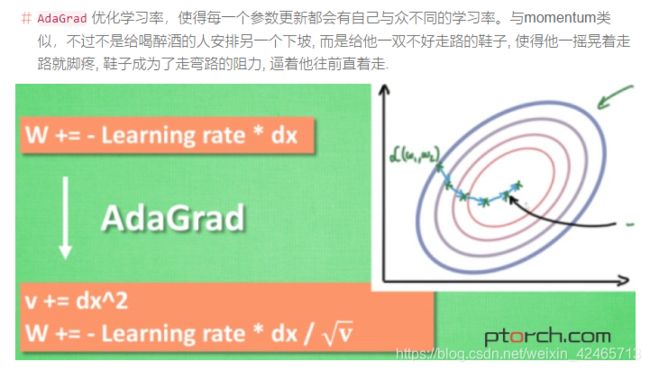
也有指数衰减,衰减公式为: lr=l∗gamma∗∗epoch
torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma, last_epoch=-1)此外还有一些别的衰减,比如余弦退火和自定义等,用的不多就不贴上来了。
3.各种优化器的基本原理
先看一个对这些优化器的评论:
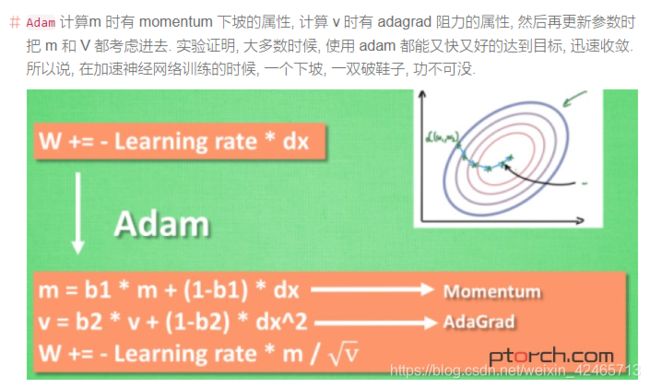
SGD 是最普通的优化器, 也可以说没有加速效果, 而 Momentum 是 SGD 的改良版, 它加入了动量原则. 后面的 RMSprop 又是 Momentum 的升级版. 而 Adam 又是 RMSprop 的升级版. 不过从这个结果中我们看到, Adam 的效果似乎比 RMSprop 要差一点. 所以说并不是越先进的优化器, 结果越佳.
之前跑crnn,我分别用过sgd和adam,比较直观的感受就是使用adam时loss经过几个step很快就下降到比较平稳了,而sgd则是比较均匀缓慢地下降。
这里参考 https://ptorch.com/news/54.html 里面的讲解。
sgd简单来说,就是gd的batch版本,每一次梯度更新,利用的是每个batch的loss,而不是整个数据集的。它存在的问题就是依赖于当前batch,所以更新很曲折,loss下降也会相对较慢。
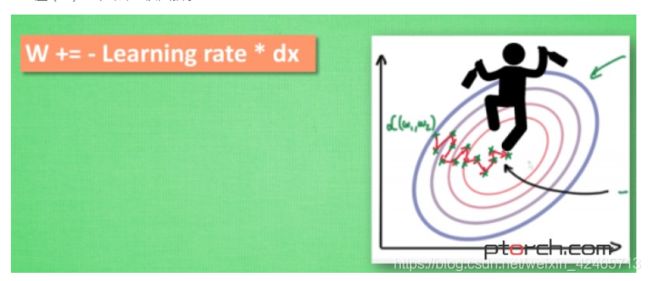
于是会考虑在更新时加一个动量,与之前的那些batch联系起来。