ElasticSearch-详解与Java-Maven操作入门案例
ElasticSearch分为Linux和Window版本,基于我们主要学习的是ElasticSearch的Java客户端的使用,所以我们是安装较为简便的Window版本,项目上线后,公司的运维人员会安装Linux版的ES供我们连接使用
文章目录
-
- 1. 什么是ElasticSearch
- 2. ElasticSearch对比Solr
- 3. 安装与启动ElasticSearch
- 4. 安装ES的图形化界面插件
- 5. ElasticSearch相关概念
-
- 5.1 ElasticSearch核心概念
-
- 5.11 接近实时 NRT
- 5.12 集群 cluster
- 5.13 节点 node
- 5.14 索引 index
- 5.15 类型 type
- 5.16 文档 document
- 5.17 分片和复制 shards&replicas
- 5.18 映射 mapping
- 6. ElasticSearch操作入门
-
- 6.1 新建索引
- 6.2 查询所有
- 6.3 字符串查询
- 6.4 词条查询
- 6.5 通配符查询/模糊查询
- 7. IK 分词器和ElasticSearch集成使用
-
- 7.1 IK分词器的安装
- 7.2 IK分词器测试
1. 什么是ElasticSearch
Elaticsearch,简称为es, es是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。es也使用Java开发并使Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单
2. ElasticSearch对比Solr
- Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能;
- Solr 支持更多格式的数据,
而 Elasticsearch 仅支持json文件格式; - Solr 官方提供的功能更多,
而 Elasticsearch 本身更注重于核心功能,高级功能多有第三方插件提供; - Solr 在传统的搜索应用中表现好于 Elasticsearch,
但在处理实时搜索应用时效率明显低于 Elasticsearch
3. 安装与启动ElasticSearch
ElasticSearch的官方地址: ElasticSearch 官网下载地址,根据你自己的需求下载对应版本,本案例使用5.6.8版本

安装ES
Window版的ElasticSearch的安装很简单,类似Window版的Tomcat,解压开即安装完毕,解压后的ElasticSearch的目录结构如下

启动ES服务
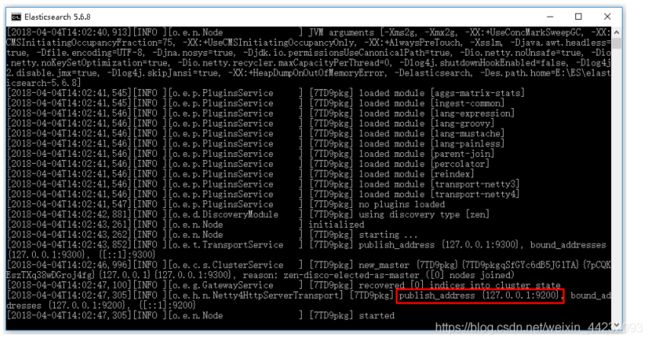
点击ElasticSearch下的bin目录下的elasticsearch.bat启动,控制台显示的日志信息如下
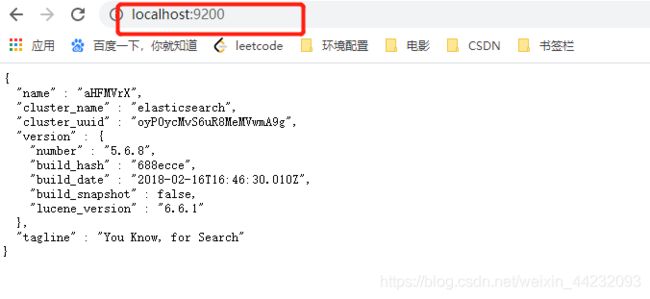
通过浏览器访问ElasticSearch服务器,看到如下返回的json信息,代表服务启动成功
4. 安装ES的图形化界面插件
ElasticSearch不同于Solr自带图形化界面,我们可以通过安装ElasticSearch的head插件,完成图形化界面的效果,完成索引数据的查看。安装插件的方式有两种,在线安装和本地安装。本文档采用本地安装方式进行head插件的安装。elasticsearch-5-*以上版本安装head需要安装node和grunt
- 下载head插件 : https://github.com/mobz/elasticsearch-head
- 将head压缩包解压到任意目录,但是要和elasticsearch的安装目录区别开,保持在同一层目录即可
![]()
- 下载nodejs:https://nodejs.org/en/download/
- 双击nodejs安装程序,一路next即可,可以换安装路径
5. 将grunt安装为全局命令 ,Grunt是基于Node.js的项目构建工具
在cmd控制台使用管理员权限运行,执行如下命令
npm install -g grunt -cli
执行结果如下图

6. 修改elasticsearch配置文件:config / elasticsearch.yml,增加以下两句命令:
# 允许跨域访问设置
http.cors.enabled: true
http.cors.allow-origin: "*"

7. 进入elasticsearch-head-master 目录启动cmd,在命令提示符下输入命令:
# 每次都要执行这个命令才可以启动,你也可以在目录下创建个.bat文件 里面写上这句话
grunt server
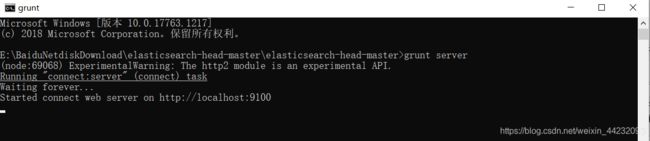
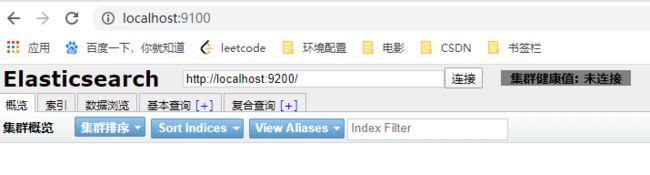
8. 打开浏览器,输入 http://localhost:9100,看到如下页面:
5. ElasticSearch相关概念
概述
Elasticsearch是面向文档(document oriented)的,这意味着它可以存储整个对象或文档(document)。然而它不仅仅是存储,还会索引(index)每个文档的内容使之可以被搜索。在Elasticsearch中,你可以对文档(而非成行成列的数据)进行索引、搜索、排序、过滤。ES比传统关系型数据库,就像如下

5.1 ElasticSearch核心概念
5.11 接近实时 NRT
Elasticsearch是一个接近实时的搜索平台。这意味着,从索引一个文档直到这个文档能够被搜索到有一个轻微的延迟(通常是1秒以内)
5.12 集群 cluster
一个集群就是由一个或多个节点组织在一起,它们共同持有整个的数据,并一起提供索引和搜索功能。一个集群由一个唯一的名字标识,这个名字默认就是“elasticsearch”。这个名字是重要的,因为一个节点只能通过指定某个集群的名字,来加入这个集群
5.13 节点 node
一个节点是集群中的一个服务器,作为集群的一部分,它存储数据,参与集群的索引和搜索功能。和集群类似,一个节点也是由一个名字来标识的,默认情况下,这个名字是一个随机的漫威漫画角色的名字,这个名字会在启动的时候赋予节点。这个名字对于管理工作来说挺重要的,因为在这个管理过程中,你会去确定网络中的哪些服务器对应于Elasticsearch集群中的哪些节点
一个节点可以通过配置集群名称的方式来加入一个指定的集群。默认情况下,每个节点都会被安排加入到一个叫做“elasticsearch”的集群中,这意味着,如果你在你的网络中启动了若干个节点,并假定它们能够相互发现彼此,它们将会自动地形成并加入到一个叫做 elasticsearch 的集群中
在一个集群里,只要你想,可以拥有任意多个节点。而且,如果当前你的网络中没有运行任何Elasticsearch节点,这时启动一个节点,会默认创建并加入一个叫做“elasticsearch”的集群
5.14 索引 index
一个索引就是一个拥有几分相似特征的文档的集合。比如说,你可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引。一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对对应于这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。在一个集群中,可以定义任意多的索引
5.15 类型 type
在一个索引中,你可以定义一种或多种类型。一个类型是你的索引的一个逻辑上的分类/分区,其语义完全由你来定。通常,会为具有一组共同字段的文档定义一个类型。比如说,我们假设你运营一个博客平台并且将你所有的数据存储到一个索引中。在这个索引中,你可以为用户数据定义一个类型,为博客数据定义另一个类型,当然,也可以为评论数据定义另一个类型。
5.16 文档 document
一个文档是一个可被索引的基础信息单元,比如,你可以拥有某一个客户的文档,某一个产品的一个文档,当然,也可以拥有某个订单的一个文档。文档以JSON(Javascript Object Notation)格式来表示,而JSON是一个到处存在的互联网数据交互格式。在一个index/type里面,你可以存储任意多的文档。注意,尽管一个文档,物理上存在于一个索引之中,文档必须被索引/赋予一个索引的type
5.17 分片和复制 shards&replicas
一个索引可以存储超出单个结点硬件限制的大量数据。比如,一个具有10亿文档的索引占据1TB的磁盘空间,而任一节点都没有这样大的磁盘空间;或者单个节点处理搜索请求,响应太慢。为了解决这个问题,Elasticsearch提供了将索引划分成多份的能力,这些份就叫做分片。当你创建一个索引的时候,你可以指定你想要的分片的数量。每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上。分片很重要,主要有两方面的原因: 1)允许你水平分割/扩展你的内容量。 2)允许你在分片(潜在地,位于多个节点上)之上进行分布式的、并行的操作,进而提高性能/吞吐量。
复制
在一个网络/云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了,这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的,Elasticsearch允许你创建分片的一份或多份拷贝,这些拷贝叫做复制分片,或者直接叫复制
复制之所以重要,有两个主要原因: 在分片/节点失败的情况下,提供了高可用性。因为这个原因,注意到复制分片从不与原/主要(original/primary)分片置于同一节点上是非常重要的。扩展你的搜索量/吞吐量,因为搜索可以在所有的复制上并行运行。总之,每个索引可以被分成多个分片。一个索引也可以被复制0次(意思是没有复制)或多次。一旦复制了,每个索引就有了主分片(作为复制源的原来的分片)和复制分片(主分片的拷贝)之别。分片和复制的数量可以在索引创建的时候指定。在索引创建之后,你可以在任何时候动态地改变复制的数量,但是你事后不能改变分片的数量
默认情况下,Elasticsearch中的每个索引被分片5个主分片和1个复制,这意味着,如果你的集群中至少有两个节点,你的索引将会有5个主分片和另外5个复制分片(1个完全拷贝),这样的话每个索引总共就有10个分片。
5.18 映射 mapping
mapping是处理数据的方式和规则方面做一些限制,如某个字段的数据类型、默认值、分析器、是否被索引等等,这些都是映射里面可以设置的,其它就是处理es里面数据的一些使用规则设置也叫做映射,按着最优规则处理数据对性能提高很大,因此才需要建立映射,并且需要思考如何建立映射才能对性能更好?和建立表结构表关系数据库三范式类似。
6. ElasticSearch操作入门
创建Maven工程 pom.xml导入坐标依赖,除了第一个外,剩下都是日志依赖,可以不用
<dependencies>
<dependency>
<groupId>org.elasticsearch.clientgroupId>
<artifactId>transportartifactId>
<version>5.6.8version>
dependency>
<dependency>
<groupId>org.apache.logging.log4jgroupId>
<artifactId>log4j-to-slf4jartifactId>
<version>2.9.1version>
dependency>
<dependency>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-apiartifactId>
<version>1.7.24version>
dependency>
<dependency>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-simpleartifactId>
<version>1.7.21version>
dependency>
<dependency>
<groupId>log4jgroupId>
<artifactId>log4jartifactId>
<version>1.2.12version>
dependency>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.10version>
dependency>
dependencies>
6.1 新建索引
package com.jwc.test;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.InetSocketTransportAddress;
import org.elasticsearch.common.xcontent.XContentBuilder;
import org.elasticsearch.common.xcontent.XContentFactory;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.rest.RestStatus;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.transport.client.PreBuiltTransportClient;
import org.junit.Test;
import javax.sound.midi.Soundbank;
import java.net.InetAddress;
/**
* @ Description
* @ auther 宁宁小可爱
* @ create 2020-07-30 10:07
*/
public class TestES {
/*
* 使用默认方式创建文档
* */
@Test
public void testCreateDoc()throws Exception{
// 创建客户端访问对象 EMPTY表示使用默认设置
TransportClient transportClient = new PreBuiltTransportClient(Settings.EMPTY)
// 使用对象方式设置客户端地址 和 端口号
.addTransportAddress(
new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9300));
// 创建文档内容 json {id:1,title:"这个是title",content:"这是个content"}
XContentBuilder xContentBuilder = XContentFactory.jsonBuilder()
.startObject()
.field("id",1)
.field("title","这是个title")
.field("content","这是个content")
.endObject();
// 客户端发送文档到服务器,必须调用get 才能够获取到Response对象 ,不调用get不执行,如果不指定ID 那么是随机字符串`
IndexResponse indexResponse = transportClient.prepareIndex("blog", "article", "1").setSource(xContentBuilder).get();
RestStatus status = indexResponse.status();
System.out.println(status);
// 关闭客户端资源
transportClient.close();
}
}
6.2 查询所有
package com.jwc.test;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.InetSocketTransportAddress;
import org.elasticsearch.common.xcontent.XContentBuilder;
import org.elasticsearch.common.xcontent.XContentFactory;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.rest.RestStatus;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.transport.client.PreBuiltTransportClient;
import org.junit.Test;
import javax.sound.midi.Soundbank;
import java.net.InetAddress;
/**
* @ Description
* @ auther 宁宁小可爱
* @ create 2020-07-30 10:07
*/
public class TestES {
/*
* 查询所有
* */
@Test
public void queryAll()throws Exception{
// 创建客户端对象
TransportClient transportClient = new PreBuiltTransportClient(Settings.EMPTY).addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9300));
// 创建查询,查询的索引是 blog type是 article
SearchResponse response = transportClient.prepareSearch("blog").setTypes("article")
// 使用查询抽象接口查询所有 .get 表示执行
.setQuery(QueryBuilders.matchAllQuery()).get();
// 获取查询结果
SearchHits hits = response.getHits();
// 获取总条数
System.out.println(hits.getTotalHits());
// 获取查询内容
for (SearchHit hit : hits) {
System.out.println(hit.getSourceAsString());
}
// 关闭资源
transportClient.close();
}
}
6.3 字符串查询
package com.jwc.test;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.InetSocketTransportAddress;
import org.elasticsearch.common.xcontent.XContentBuilder;
import org.elasticsearch.common.xcontent.XContentFactory;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.rest.RestStatus;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.transport.client.PreBuiltTransportClient;
import org.junit.Test;
import javax.sound.midi.Soundbank;
import java.net.InetAddress;
/**
* @ Description
* @ auther 宁宁小可爱
* @ create 2020-07-30 10:07
*/
public class TestES {
/*
* 按照字符串查询
* */
@Test
public void queruString()throws Exception{
// 创建客户端对象
TransportClient transportClient = new PreBuiltTransportClient(Settings.EMPTY).addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9300));
// 创建查询,查询的索引是 blog type是 article
SearchResponse response = transportClient.prepareSearch("blog").setTypes("article")
// 使用查询抽象接口进行字符串查询 .get 表示执行
.setQuery(QueryBuilders.queryStringQuery("这是")).get();
// 获取查询结果
SearchHits hits = response.getHits();
// 获取总条数
System.out.println(hits.getTotalHits());
// 获取查询内容
for (SearchHit hit : hits) {
System.out.println(hit.getSourceAsString());
}
// 关闭资源
transportClient.close();
}
}
6.4 词条查询
package com.jwc.test;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.InetSocketTransportAddress;
import org.elasticsearch.common.xcontent.XContentBuilder;
import org.elasticsearch.common.xcontent.XContentFactory;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.rest.RestStatus;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.transport.client.PreBuiltTransportClient;
import org.junit.Test;
import javax.sound.midi.Soundbank;
import java.net.InetAddress;
/**
* @ Description
* @ auther 宁宁小可爱
* @ create 2020-07-30 10:07
*/
public class TestES {
/*
* 按照词条查询
* */
@Test
public void queryTerm()throws Exception{
// 创建客户端对象
TransportClient transportClient = new PreBuiltTransportClient(Settings.EMPTY).addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9300));
// 创建查询,查询的索引是 blog type是 article
SearchResponse response = transportClient.prepareSearch("blog").setTypes("article")
// 使用查询抽象接口进行词条查询 .get 表示执行
.setQuery(QueryBuilders.termQuery("title","这是")).get();
// 获取查询结果
SearchHits hits = response.getHits();
// 获取总条数
System.out.println(hits.getTotalHits());
// 获取查询内容
for (SearchHit hit : hits) {
System.out.println(hit.getSourceAsString());
}
// 关闭资源
transportClient.close();
}
}
6.5 通配符查询/模糊查询
package com.jwc.test;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.InetSocketTransportAddress;
import org.elasticsearch.common.xcontent.XContentBuilder;
import org.elasticsearch.common.xcontent.XContentFactory;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.rest.RestStatus;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.transport.client.PreBuiltTransportClient;
import org.junit.Test;
import javax.sound.midi.Soundbank;
import java.net.InetAddress;
/**
* @ Description
* @ auther 宁宁小可爱
* @ create 2020-07-30 10:07
*/
public class TestES {
/*
* 通配符查询
* */
@Test
public void queryWildCard()throws Exception{
// 创建客户端对象
TransportClient transportClient = new PreBuiltTransportClient(Settings.EMPTY).addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9300));
// 创建查询,查询的索引是 blog type是 article
SearchResponse response = transportClient.prepareSearch("blog").setTypes("article")
// 使用查询抽象接口进行通配符查询 .get 表示执行
.setQuery(QueryBuilders.wildcardQuery("title","*这是")).get();
// 获取查询结果
SearchHits hits = response.getHits();
// 获取总条数
System.out.println(hits.getTotalHits());
// 获取查询内容
for (SearchHit hit : hits) {
System.out.println(hit.getSourceAsString());
}
// 关闭资源
transportClient.close();
}
}
7. IK 分词器和ElasticSearch集成使用
在上面我们进行查询的时候会发现,我们查询 这是这个词的时候根本搜索不到数据,那是为什么呢,是因为ElasticSearch的默认分词器导致的,当我们创建索引时,没有特定的进行映射的创建,所以会使用默认的分词器进行分词,即每个字单独分成一个词
例如 : 我是程序员
分词后的效果是: 我, 是, 程, 序, 员
而我们需要的分词效果是:我、是、程序、程序员、员
那么如何解决这个问题呢 ,就需要使用我们的IK分词器来进行分词,IK分词器被称为中国人的分词器,那么如何集成呢
7.1 IK分词器的安装
- 下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
- 解压,将解压后的elasticsearch文件夹拷贝到elasticsearch-5.6.8\plugins下,并重命名文件夹为ik

- 重新启动ElasticSearch,即可加载IK分词器
7.2 IK分词器测试
IK提供了两个分词算法ik_smart 和 ik_max_word,其中 ik_smart 为最少切分,ik_max_word为最细粒度划分
最小切分:在浏览器地址栏输入地址
http://127.0.0.1:9200/_analyze?analyzer=ik_smart&pretty=true&text=我是程序员
{
"tokens" : [
{
"token" : "我", "start_offset" : 0, "end_offset" : 1, "type" : "CN_CHAR", "position" : 0 },
{
"token" : "是", "start_offset" : 1, "end_offset" : 2, "type" : "CN_CHAR", "position" : 1 },
{
"token" : "程序员", "start_offset" : 2,"end_offset" : 5, "type" : "CN_WORD", "position" : 2 }
] }
最细切分:在浏览器地址栏输入地址
http://127.0.0.1:9200/_analyze?analyzer=ik_max_word&pretty=true&text=我是程序员
{
"tokens" : [
{
"token" : "我", "start_offset" : 0, "end_offset" : 1, "type" : "CN_CHAR", "position" : 0 },
{
"token" : "是", "start_offset" : 1, "end_offset" : 2, "type" : "CN_CHAR", "position" : 1 },
{
"token" : "程序员", "start_offset" : 2, "end_offset" : 5, "type" : "CN_WORD", "position" : 2 },
{
"token" : "程序", "start_offset" : 2, "end_offset" : 4, "type" : "CN_WORD", "position" : 3 },
{
"token" : "员", "start_offset" : 4, "end_offset" : 5, "type" : "CN_CHAR", "position" : 4 }
] }