一次JVM GC排查过程及解决方案
背景介绍:
dispatcher-queue-consumer主要负责订阅rocketmq的topic,消费消息进行业务逻辑处理。目前一共有14个消费组,其中轨迹类消费组(3组,其他11类消费组tps量级较低)tps峰值高达10000,均值5000,单机 tps约为5000/8.
prod环境堆内存为2G,垃圾回收算法组合使用Parallel Scavenge+Parallel Old.
统计时段: 所有数据统计均以15-18点为准
优化前fgc 1次/24小时,ygc 6-7次/1分钟, ygc平均耗时在50ms+(1min内累计ygc耗时)

jvm ygc次数统计(分钟为单位,下同)

jvm gc耗时(1min ygc累计耗时,下同)
业内评价gc是否需要优化的标准一般为: ygc耗时<50ms,fgc耗时<1s,fgc频次尽可能低,ygc频次则视qps等情况而定。不少系统ygc 10次/min,仍然可以满足线上应用良好运转。由此可见系统的指标基本正常,但让人诧异的是fgc 1次/24小时,有些频繁。因为这个系统主要是处理消息的,单条消息处理速度在10-ms级别,处理消息时会生产大量的临时对象,但大部分应该是短命的,不应该进入老年代。
对象何时进入老年代:
1.对象年纪超过MaxTenuringThreshold值,在ygc时直接进行老年代
2.Survivor区中相同年龄的对象大小的总和大于Survivor空间的一半,年龄>=该年龄的对象直接进入到老年代
3.ygc时,survivor空间过小,放不下的对象直接进入老年代
4.大对象直接进入老年代
探索之路一:
查看gc.log时,意外发现
from space 2560K, 86% used [0x00000000ffb00000,0x00000000ffd2c010,0x00000000ffd80000)
from space 2560K, 86% used [0x00000000ffb00000,0x00000000ffd2c010,0x00000000ffd80000)
from space 2560K, 100% used [0x00000000ffd80000,0x0000000100000000,0x0000000100000000)
from space 2560K, 100% used [0x00000000ffd80000,0x0000000100000000,0x0000000100000000)
from space 3072K, 97% used [0x00000000ffa00000,0x00000000ffcf0000,0x00000000ffd00000)
from space 3072K, 97% used [0x00000000ffa00000,0x00000000ffcf0000,0x00000000ffd00000)
from space 3072K, 99% used [0x00000000ffd00000,0x00000000ffffc070,0x0000000100000000)
from space 3072K, 99% used [0x00000000ffd00000,0x00000000ffffc070,0x0000000100000000)
from space 3584K, 90% used [0x00000000ff900000,0x00000000ffc28080,0x00000000ffc80000)
from space 3584K, 90% used [0x00000000ff900000,0x00000000ffc28080,0x00000000ffc80000)
survivor空间的使用率居高不下,很可能会导致年龄未达到MaxTenuringThreshold,提前进入老年代,加速fgc的发生。再仔细一看,from空间的大小在不断发生变化,而且明显小于2G*1/3*1/10(60M+).查阅资料发现JDK 1.8 默认使用 UseParallelGC 垃圾回收器,该垃圾回收器默认启动了 AdaptiveSizePolicy。即根据内存使用情况,动态调整SurvivorRatio的值。使用-XX:-UseAdaptiveSizePolicy果断关闭自适应策略,灰度机器ABTest.
经过验证发现:ygc均值5-6,fgc大约1-2天发生一次。有效果,但并没有达到预期的期望。
探索之路二:
疑问:JVM空间到底存在哪些对象?
jmap -histo:live pid查看fgc回收后的对象。
num #instances #bytes class name
----------------------------------------------
1: 102877 16214328 [C
2: 6519 8839176 [B
3: 99655 2391720 java.lang.String
4: 11952 2319296 [I
5: 16110 1784112 java.lang.Class
6: 55539 1777248 java.util.concurrent.ConcurrentHashMap$Node
7: 19388 1373384 [Ljava.lang.Object;
8: 37998 1215936 java.util.HashMap$Node
9: 11592 1020096 java.lang.reflect.Method
10: 6671 716680 [Ljava.util.HashMap$Node;
11: 44169 706704 java.lang.Object
..............................忽略
Total 737368 51852232回收后,内存对象总共50多m,这也从侧面验证了系统本身更多是短命的对象。
jmap -histo pid查看fgc回收前的对象
num #instances #bytes class name
----------------------------------------------
1: 457523 536219024 [I
2: 4471780 358357760 [Lio.netty.util.Recycler$DefaultHandle;
3: 427992 234967096 [B
4: 2176886 174083488 [C
5: 4471139 143076448 io.netty.util.Recycler$WeakOrderQueue$Link
6: 1472824 35347776 java.lang.String
7: 448948 21634520 [Ljava.lang.Object;
8: 335138 16086624 java.util.HashMap
9: 223272 14289408 com.mysql.jdbc.ConnectionPropertiesImpl$BooleanConnectionProperty
10: 75856 13957504 com.fasterxml.jackson.core.json.UTF8StreamJsonParser
11: 324862 10395584 java.util.Hashtable$Entry
12: 298872 9563904 java.util.HashMap$Node
13: 47697 7435904 [Ljava.util.HashMap$Node;
14: 145339 5767552 [Ljava.lang.String;
15: 75862 5462064 com.fasterxml.jackson.databind.deser.DefaultDeserializationContext$Impl
16: 81512 5216768 com.mysql.jdbc.ConnectionPropertiesImpl$StringConnectionProperty
17: 75862 4855168 com.fasterxml.jackson.core.sym.ByteQuadsCanonicalizer
18: 77215 4324040 com.fasterxml.jackson.core.io.IOContext
19: 75856 4247936 com.fasterxml.jackson.core.util.TextBuffer
................................................忽略
94: 641 30768 io.netty.util.Recycler$Stack
1841: 4 96 io.netty.util.Recycler$2
5701: 1 16 io.netty.util.Recycler$1
5702: 1 16 io.netty.util.Recycler$3
................................................忽略
Total 13563873 1421279568通过内存布局,我们意外发现io.netty.util.Recycler$WeakOrderQueue$Link对象多达447W,占据内存500多M. io.netty.util.Recycler这个类对象是干什么的? 项目中使用了rocketmq-client jar包,底层使用netty进行通讯。Recycler是netty中定义的对象池。Recycler使用ThreadLocal技术为每个线程维护一个Stack栈,当使用对象时优先从本地stack时pop对象,无则从其他的线程栈中获取对象,再无则创建对象。使用完成后回收对象,如果是本地线程栈里获取或生成的对象回到本地stack中,从其他线程stack中获取的,回到其他线程栈中。
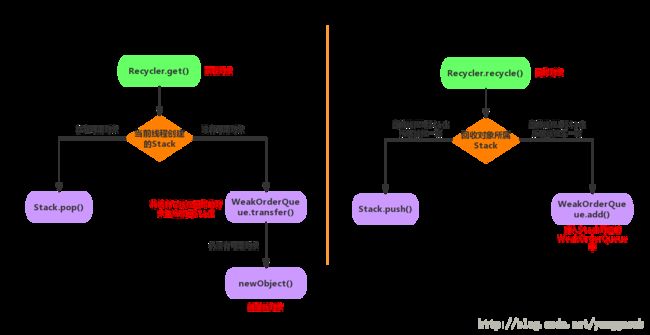
我们底层使用的netty-all-4.0.36.Final.jar包,追踪源码我们发现这个对象池并不会主动释放对象,但是为避免OOM,使用了大量weak reference,这样在每次gc时回收这些对象。
94: 641 30768 io.netty.util.Recycler$Stack
1841: 4 96 io.netty.util.Recycler$2
5701: 1 16 io.netty.util.Recycler$1
5702: 1 16 io.netty.util.Recycler$3我们发现系统中一共使用了6个回收器,累计使用Recycler的线程数达到641个,如下面代码每一个线程使用Recycler时都维护一个WeakHashMap,通过WeakOrderQueue里面维护着使用该回收器的其他线程的信息,WeakOrderQueue又通过链表的方式维护其他的结点。
private static final FastThreadLocal, WeakOrderQueue>> DELAYED_RECYCLED =
new FastThreadLocal, WeakOrderQueue>>() {
@Override
protected Map, WeakOrderQueue> initialValue() {
return new WeakHashMap, WeakOrderQueue>();
}
}; 到这里问题基本定位在Recycler的使用+底层使用了大量的线程,导致了gc频繁。Recycler部分对象使用了Weak Reference在ygc时直接回收,其他对象到达年龄后进入老年代。在apache的官方网站上,我们找到了类似的问题及解决方案https://issues.apache.org/jira/browse/CASSANDRA-14748,netty 4.1.14后对Recycler进行了优化,及时清理,避免对象占据大量堆内存,但线上实践后,效果提升仍然有限。
探索之路三:
static {
// In the future, we might have different maxCapacity for different object types.
// e.g. io.netty.recycler.maxCapacity.writeTask
// io.netty.recycler.maxCapacity.outboundBuffer
int maxCapacity = SystemPropertyUtil.getInt("io.netty.recycler.maxCapacity.default",
DEFAULT_INITIAL_MAX_CAPACITY);
if (maxCapacity < 0) {
maxCapacity = DEFAULT_INITIAL_MAX_CAPACITY;
}
DEFAULT_MAX_CAPACITY = maxCapacity;
if (logger.isDebugEnabled()) {
if (DEFAULT_MAX_CAPACITY == 0) {
logger.debug("-Dio.netty.recycler.maxCapacity.default: disabled");
} else {
logger.debug("-Dio.netty.recycler.maxCapacity.default: {}", DEFAULT_MAX_CAPACITY);
}
}
INITIAL_CAPACITY = Math.min(DEFAULT_MAX_CAPACITY, 256);
}
@SuppressWarnings("unchecked")
public final T get() {
if (maxCapacity == 0) {
return newObject(NOOP_HANDLE);
}
Stack stack = threadLocal.get();
DefaultHandle handle = stack.pop();
if (handle == null) {
handle = stack.newHandle();
handle.value = newObject(handle);
}
return (T) handle.value;
} 直接弃用Recycler,设置-Dio.netty.recycler.maxCapacity.default=0,同时微调
–XX:NewRatio=1 (增加年轻代大小,减少ygc次数,减缓age增加,尽量避免进入老年代)
-XX:SurvivorRatio=18 (survivor区利用率低,增加eden区大小)
-XX:MaxTenuringThreshold=15 (强制对象进入老年代最大年纪)
优化后效果:
gc次数降到3-4次/1分钟

ygc平时耗时40-ms

fgc频次 1次/54小时
----------------------------------------------------------------------------------------------------------------------------------------------------------
最后通过整体效果图对比一下优化效果:
10.69.18.174 A 优化前参数
10.30.3.190 B 优化后参数
FGC整体效果对比
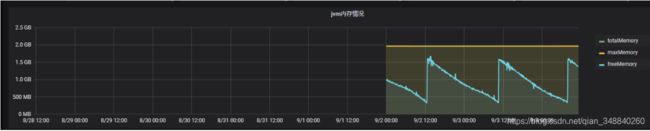
A -10.69.18.174 (1次/24小时)

B -10.30.3.190 (1次/54小时)
YGC频次效果对比(单位:5min)
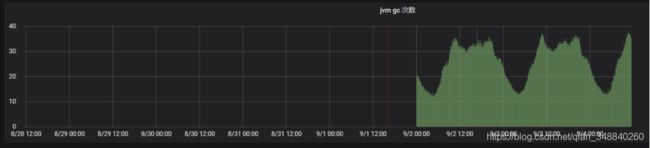
A -10.69.18.174
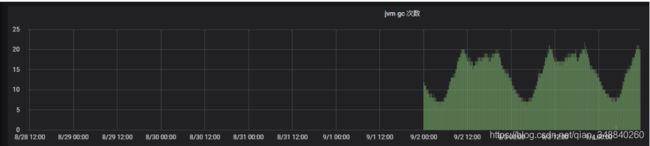
B -10.30.3.190
GC耗时(单位:5min)
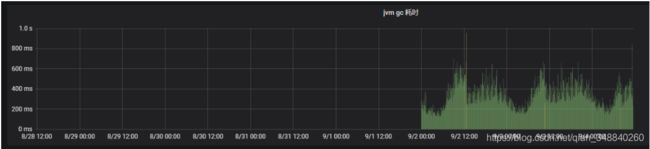
A -10.69.18.174
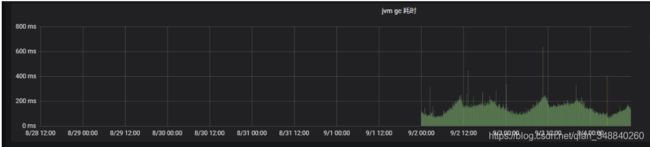
B -10.30.3.190