(八)ElasticSearch的数据存储原理
(八)ElasticSearch的数据存储原理
elasticsearch的索引操作以及mapping配置
文章目录
- (八)ElasticSearch的数据存储原理
- 1:ElasticSearch的数据写入原理
-
- 1.1:步骤分析
- 1.2:索引数据的具体保存方式
-
- 1.2.1 :Field Data
- 1.2.2:Term Index
- 1.2.3:Per-Document Values
- 2:Elasticsearch中数据是如何存储的
-
- 2.1:lucene数据存储
-
- 1.1:lucene基本概念
- 1.2:lucene文件内容
-
- 1.2.1:lucene文件内容详解
- 1.3:lucene字典
- 1.4:lucene存储数据结构
1:ElasticSearch的数据写入原理

1.1:步骤分析
1:写入请求,分发节点。
2:数据写入同时写入内存和translog各一份,tanslog为保证数据不丢失,每 5 秒,或每次请求操作结束前,会强制刷新 translog 日志到磁盘上
3:确定数据给那个分片,refresh 刷新内存中数据到分片的segment,默认1秒刷新一次,为了提高吞吐量可以增大60s。参数refresh_interval
4:segment刷新到磁盘中完成持久化,保存成功清除translog,新版本es的 translog 不会在 segment 落盘就删,而是会保留,默认是512MB,保留12小时。每个分片。所以分片多的话 ,要考虑 translog 会带来的额外存储开销
5:segment过多会进行合并merge为大的segment,消耗大量的磁盘io和网络io
1.2:索引数据的具体保存方式
elasticsearch底层是lucene存储架构
elasticsearch的数据保存在lucene文件中,es的elasticsearch.yml配置文件中配置数据保存路径。
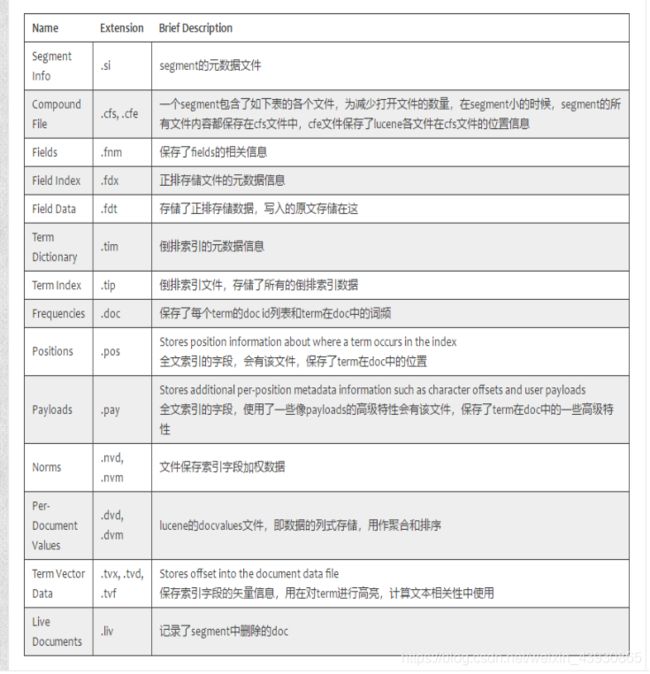
lucene包的文件是由很多segment文件组成的,segments_xxx文件记录了lucene包下面的segment文件数量。每个segment会主要包含如下的文件。
Name Extension Brief Description
Segment Info .si segment的元数据文件
Compound File .cfs, .cfe 一个segment包含了如下表的各个文件,为减少打开文件的数量,在segment小的时候,segment的所有文件内容都保存在cfs文件中,cfe文件保存了lucene各文件在cfs文件的位置信息
Fields .fnm 保存了所有fields的类型等信息
Field Index .fdx 指向字段值的指针。正排存储文件的元数据信息
Field Data .fdt 存储了正排存储数据,写入的原文存储在这
Term Dictionary .tim 倒排索引的元数据信息
Term Index .tip 倒排索引文件,也就是单词词典,缓存在内存中,存储了所有单词的倒排索引数据
Frequencies .doc 保存了每个term的doc id列表和term在doc中的词频
Per-Document Values .dvd, .dvm lucene的docvalues文件,即数据的列式存储,用作聚合和排序
Live ocuments .liv 记录了segment中删除的doc
照上面的lucene表进行如下的关联。
存储原文_source的文件.fdt .fdm .fdx;
存储倒排索引的文件.tim .tip .doc;
用于聚合排序的列存文件.dvd .dvm;
全文检索文件.pos .pay .nvd .nvm等。
加载到内存中的文件有.fdx .tip .dvm,其中.tip占用内存最大,而.fdt . tim .dvd文件占用磁盘最大
1.2.1 :Field Data
我们写入数据的原始数据保存文件,mapping中无法配置。
1.2.2:Term Index
倒排索引文件,也就是mapping中fields的index属性定义决定改字段是否会建立索引,不需要搜索分析是,关闭此属性,减少存储压力。
1.2.3:Per-Document Values
mapping中fields的docvalues 属性,决定是否保存。
2:Elasticsearch中数据是如何存储的

shard是Elasticsearch数据存储的最小单位,index的存储容量为所有shard的存储容量之和。Elasticsearch集群的存储容量则为所有index存储容量之和。
一个shard就对应了一个lucene的library。对于一个shard,Elasticsearch增加了translog的功能,类似于HBase WAL,是数据写入过程中的中间数据,其余的数据都在lucene库中管理的。
2.1:lucene数据存储
1.1:lucene基本概念
segment : lucene内部的数据是由一个个segment组成的,写入lucene的数据并不直接落盘,而是先写在内存中,经过了refresh间隔,lucene才将该时间段写入的全部数据refresh成一个segment,segment多了之后会进行merge成更大的segment。lucene查询时会遍历每个segment完成。由于lucene* 写入的数据是在内存中完成,所以写入效率非常高。但是也存在丢失数据的风险,所以Elasticsearch基于此现象实现了translog,只有在segment数据落盘后,Elasticsearch才会删除对应的translog。
doc : doc表示lucene中的一条记录
field :field表示记录中的字段概念,一个doc由若干个field组成。
term :term是lucene中索引的最小单位,某个field对应的内容如果是全文检索类型,会将内容进行分词,分词的结果就是由term组成的。如果是不分词的字段,那么该字段的内容就是一个term。
倒排索引(inverted index): lucene索引的通用叫法,即实现了term到doc list的映射。
正排数据:搜索引擎的通用叫法,即原始数据,可以理解为一个doc list。
docvalues :Elasticsearch中的列式存储的名称,Elasticsearch除了存储原始存储、倒排索引,还存储了一份docvalues,用作分析和排序。
1.2:lucene文件内容
lucene包的文件是由很多segment文件组成的,segments_xxx文件记录了lucene包下面的segment文件数量。每个segment会包含如下的文件。
1.2.1:lucene文件内容详解
1:fields信息文件
文件后缀:.fnm
该文件存储了fields的基本信息。
fields信息中包括field的数量,field的类型,以及IndexOpetions,包括是否存储、是否索引,是否分词,是否需要列存等等。
2:倒排索引文件
索引后缀:.tip,.tim
倒排索引也包含索引文件和数据文件,.tip为索引文件,.tim为数据文件,索引文件包含了每个字段的索引元信息,数据文件有具体的索引内容。
3:正排数据存储文件
文件后缀:.fdx, .fdt
索引文件为.fdx,索引文件记录了快速定位文档数据的索引信息。数据文件为.fdt,数据文件记录了所有文档id的具体内容,数据存储文件功能为根据自动的文档id,得到文档的内容,搜索引擎的术语习惯称之为正排数据,即doc_id -> content,es的_source数据就存在这
4:列存文件(docvalues)
文件后缀:.dvm, .dvd
索引文件为.dvm,数据文件为.dvd。
lucene实现的docvalues有如下类型:
1、NONE 不开启docvalue时的状态
2、NUMERIC 单个数值类型的docvalue主要包括(int,long,float,double)
3、BINARY 二进制类型值对应不同的codes最大值可能超过32766字节,
4、SORTED 有序增量字节存储,仅仅存储不同部分的值和偏移量指针,值必须小于等于32766字节
5、SORTED_NUMERIC 存储数值类型的有序数组列表
6、SORTED_SET 可以存储多值域的docvalue值,但返回时,仅仅只能返回多值域的第一个docvalue
7、对应not_anaylized的string字段,使用的是SORTED_SET类型,number的类型是SORTED_NUMERIC类型
其中SORTED_SET 的 SORTED_SINGLE_VALUED类型包括了两类数据 : binary + numeric, binary是按ord排序的term的列表,numeric是doc到ord的映射。
1.3:lucene字典
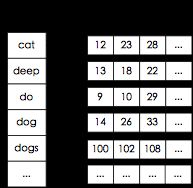
使用lucene进行查询不可避免都会使用到其提供的字典功能,即根据给定的term找到该term所对应的倒排文档id列表等信息。实际上lucene索引文件后缀名为tim和tip的文件实现的就是lucene的字典功能。
term字典是一个已经按字母顺序排序好的数组,数组每一项存放着term和对应的倒排文档id列表。每次载入索引的时候只要将term数组载入内存,通过二分查找即可
1.4:lucene存储数据结构
引用文档
lucene从4开始大量使用的数据结构是FST(Finite State Transducer)。
FST有两个优点:
1空间占用小。通过对词典中单词前缀和后缀的重复利用,压缩了存储空间
2查询速度快。
参考文献1: