2019独角兽企业重金招聘Python工程师标准>>> 
avro是apache下hadoop的子项目,拥有序列化、反序列化、RPC功能。序列化的效率比jdk更高,与Google的protobuffer相当,比facebook开源Thrift(后由apache管理了)更优秀。
因为avro采用schema,如果是序列化大量类型相同的对象,那么只需要保存一份类的结构信息+数据,大大减少网络通信或者数据存储量
例子:
新建一个maven工程
pom.xml
4.0.0
com.jv
avro
0.0.1-SNAPSHOT
jar
avro
http://maven.apache.org
UTF-8
2.3.2
1.7.5
junit
junit
4.10
test
org.slf4j
slf4j-simple
1.6.4
compile
org.apache.avro
avro
1.7.5
org.apache.avro
avro-ipc
1.7.5
org.apache.maven.plugins
maven-compiler-plugin
${compiler-plugin.version}
org.apache.avro
avro-maven-plugin
1.7.5
schemas
generate-sources
schema
protocol
idl-protocol
${project.basedir}/src/main/avro/
${project.basedir}/src/main/java/
因为maven可能不认识
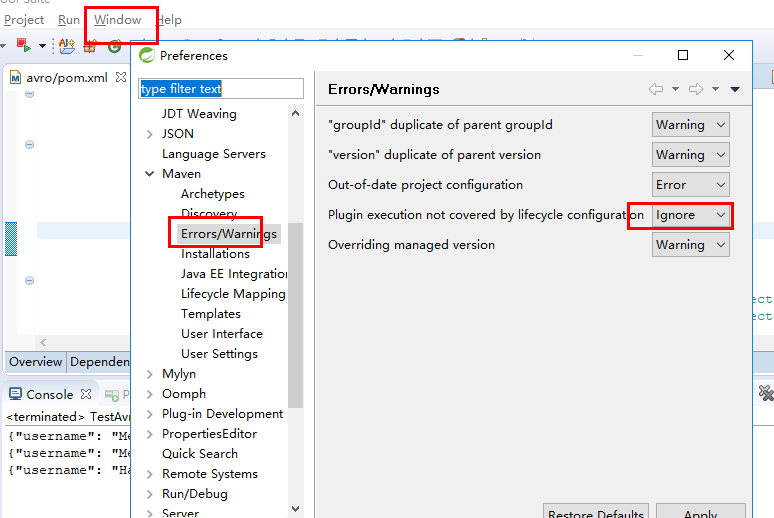

这段配置的是代码生成插件,需要给工程创建一个src/main/avro 源文件目录
具体步骤为:
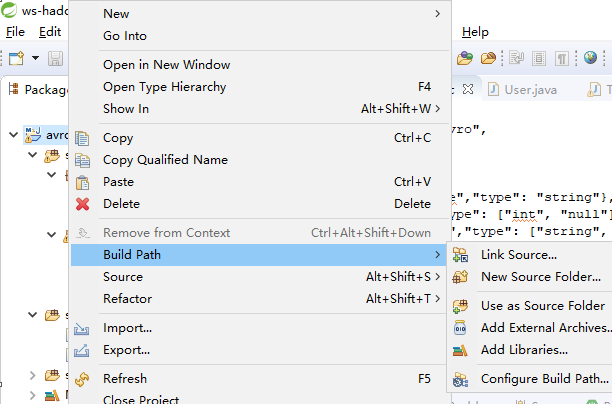
编写模式文件user.avsc:
{
"namespace": "com.jv.avro",
"type": "record",
"name": "User",
"fields": [
{"name": "username","type": "string"},
{"name": "age","type": ["int", "null"]},
{"name": "address","type": ["string", "null"]}
]
}namespace:命名空间,在使用插件生成代码的时候,User类的包名就是它
type:有 records, enums, arrays, maps, unions , fixed 取值,records是相当于普通的class
name:类名,类的全名有namespace+name构成
doc:注释
aliases:取的别名,其他地方使用可以使用别名来引用
fields:属性
name:属性名
type:属性类型,可以是用["int","null"]或者["int",1]执行默认值
default:也可以使用该字段指定默认值
doc:注释
根据模式定义生成代码
按照图中圈出来的步骤操作
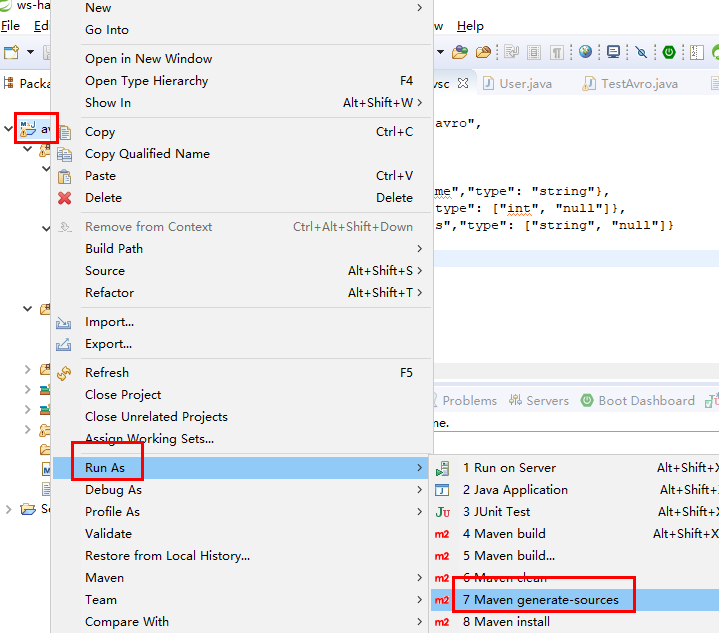
观察console中是否输出SUCCESS,是则说明成功了
测试代码
package com.jv.test;
import java.io.File;
import java.io.IOException;
import org.apache.avro.file.DataFileReader;
import org.apache.avro.file.DataFileWriter;
import org.apache.avro.io.DatumReader;
import org.apache.avro.io.DatumWriter;
import org.apache.avro.specific.SpecificDatumReader;
import org.apache.avro.specific.SpecificDatumWriter;
import com.jv.avro.User;
public class TestAvro {
public static void main(String[] args) throws IOException {
//实例化代码方式1
User user1 = new User();
user1.setUsername(new String("Messi"));
user1.setAddress("Barcelona");
user1.setAge(30);
//实例化代码方式3
User user2 = new User(new String("Messi"),30,"巴塞罗那");
//实例化代码方式3
User user3 = new User().newBuilder().setUsername("Havi").setAge(34).setAddress("卡塔尔").build();
//序列化对象并保存到文件中
DatumWriter userDatumWriter = new SpecificDatumWriter(User.class);
DataFileWriter dataFileWriter = new DataFileWriter(userDatumWriter);
dataFileWriter.create(user1.getSchema(), new File("users.avro"));
dataFileWriter.append(user1);
dataFileWriter.append(user2);
dataFileWriter.append(user3);
dataFileWriter.close();
//从文件中反序列化对象输出
DatumReader userDatumReader = new SpecificDatumReader(User.class);
DataFileReader dataFileReader = new DataFileReader(new File("users.avro"), userDatumReader);
User user = null;
while (dataFileReader.hasNext()) {
user = dataFileReader.next(user);
System.out.println(user);
}
}
}
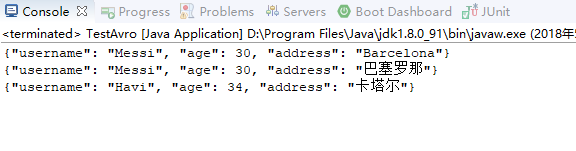
运行后的输出结果