Redis所支持的五种基本数据结构的实现原理简述
文章目录
-
-
- 1. 概念
- 2 String
- 3 list
- 4. hash
- 5.set
- 6. sorted-set
-
1. 概念
Redis中保存数据的key-value的value内存的通用结构为:
typedef struct redisobject{
unsigned type:4; // 结构化类型
unsigned encoding:4; // 结构化类型的具体实现方式
unsigned lru:REDIS_LRU_BITS; // 对于长久不访问对象的清理
void *ptr; // 应用计数用于对象向的GC
} robj;
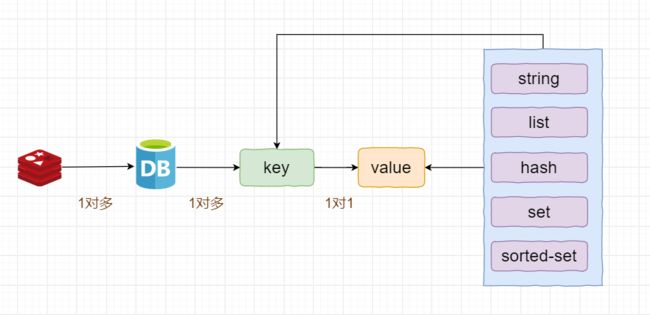
Redis中常用的存储数据的数据结构有5种:
- key-string:一个key对应一个值,一般用于存储一个值
- key-hash:一个key对应一个Map,一般用于存储一个对象数据
- key-list:一个key对应一个列表,一般可用于实现栈或队列结构
- key-set:一个key对应一个无序集合,一般可用于交集、差集和并集的操作
- key-zset:一个key赌赢一个有序集合,一般可用于排行榜、积分存储等操作
另外,还有几种其他的数据结构:
- HyperLogLog:计算近似值
- GEO:地理位置
- BIT:存储一个字符串,本质上存储的是一个byte[]
各种数据结构的示意图如下所示:
2 String
Redis中string除了可以存放字面意义上的字符串外,还可以用于存放整数和浮点数,三种类型之间的转换由Redis负责。内存的存储结构中,int用于存储整型数据,sds(simple dynamic string)用于存储字节/字符串和浮点型数据。
其中sds的结构定义如下:
typedef struct sdshdr{
unsigned int len; // 当前已存储数据的大小
unsigned int free; // 空闲空间,便于扩容
char buf[]; // 存储string内容
};
例如,"hello"在buf[]中的存储形式为:
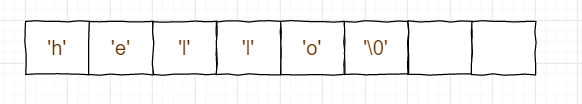
其中\0的结束符遵从了C语言的规范。当buf[]仍有空间时,append操作直接添加到现有的string内容的后面,而且free的部分不会因string长度的变化而改变。但是当现有的buf[]无法存储string内容时,就需要进行扩容操作,触发的条件如下:
- 字符串初始化时,
buf[]的大小为len + 1。当对string的操作完成后预期的长度小于1MB时,扩容的大小等于string预期长度加1,即buf[]长度加倍 - 对于长度大于1MB的string,
buf[]总是留出1MB的free空间,即buf[]以新string长度的2倍进行扩容,但最大留出1MB空间
3 list
list用于存储string序列,内部使用linkedlist或ziplist存储。当list中元素的个数和单元个数的长度较小时,Redis使用ziplist存储来减少内存空间的使用,否则使用linkedlist存储。
linkedlist的实现方式就是双向链表,list中定义了头尾指针和链表的长度,链表中的每个节点都包含前驱指针和后继指针。
typedef struct list{
listNode *head;
listNode *tail;
unsigned long len;
// ...
}
typedef struct listNode{
struct listNode *prev;
struct listNode *next;
void *value;
}
ziplist存储于连续的内存中,结构如下:
<zlbytes><zltial><zllen><entry><entry>...<zlend>
其中:
zlbytes:ziplist的总长度zltail:指向最末元素,即最末元素距离ziplist头的偏移量zllen:ziplist中元素的个数entry:用于存储元素的内容zlend:恒为0xFF,用于不同ziplist之间的定界符
entry中包含相邻的前一个entry的长度和自描述的entry内容,内容中包含benentry的内容类型、长度和内容本身。
4. hash
hash内部使用hashtable和ziplist存储内容,对于数据量较小的hash使用ziplist,否则使用hashtable。其中hashtable的实现自底向上分为三层,分别为:
- dictEntry:管理一个key-value对,同时保留同一个桶中相邻元素的指针,以此维护哈希桶的内部链
- dictht:维护哈希表所有的桶链
- dict:当dictht需要扩容或是缩容时,用于管理dictht的迁移
其中dictht结构定义如下:
typedef struct dictht{
dicEntry ** table; // 维护哈希桶,指向桶中的第一个dictEntry
unsigned long size; // 桶的个数
unsigned long sizemask; // 恒等于size - 1,用于快速得到哈希值的模
unsigned long used; // 已用的桶的个数
};
结构存储示意图如下所示:

当有一个新key到达时,首先通过哈希算法计算得到它对应的哈希值h,然后对size字段取模得到它对应的桶。进入对应的桶遍历全部的entry,判断是否存在相同的key。如果没有,则将其插入到桶头,并且更新dictht的used数量;如果有,则覆盖更新。
这里hashtable的实现方式和Jdk 1.7 中的HashMap的实现是类似的。
当桶中的entry很多时,遍历全部的entry寻找key的效率将变得很低,需要增加痛的数量来减少一个桶中entry的数量。hash这里同样使用了负载因子来决定是否需要扩容,负载因子等于已有元素和哈希桶的比值,具体扩容规则如下:
- 小于1时一定不扩容
- 大于5时一定扩容
- 1和5之间时,如果Redis没有进行basave/bdrewrite操作时,则会扩容
当负载因子到达0.1时,Redis将对hash进行缩容,减少空闲桶的数量。扩容操作后新的桶的数量为现有桶的2n倍,缩容后桶的数量为现有桶的0.5n。另外,扩容和缩容都是通过新建hash表来实现的,扩容和缩容的过程中新旧两张表都是可以访问的,hashtable中的dict用于管理旧表到新表数据的迁移过程。如果迁移的过程中发生访问请求,首先回去访问旧表,如果发现对应的key所有的桶已经发生了迁移,则重新访问新表,否则继续在旧表操作。

hashj依赖于ziplist中,entry的个数总是2的整数倍,其中奇数个entry存放key,key所对应的entry的下一个相邻的entry存放key对应的value。
5.set
set用于存储不重复的数据,但是数据之间是无序的,set内部依赖于hashtable和intset实现。其中,当set中只有整型数据时,内部使用intset实现;否则,使用hashtable实现,而且它只利用了hashtable的key来保证数据的不重复,value永远为null。
hashtable和上面hash中hashtable的实现方式没有太大的差别,下面着重看一下intset的实现。intset核心就是一个字节数组,其中从小到大有序的存放着set的数据,结构定义如下:
typedef struct intset{
uint32_t encoding; // 元素的编码方式,即一个元素占用多少个contents数组
uint32_t lenght; // set中元素的个数
int8_t contents[]; // 存储元素内容
};
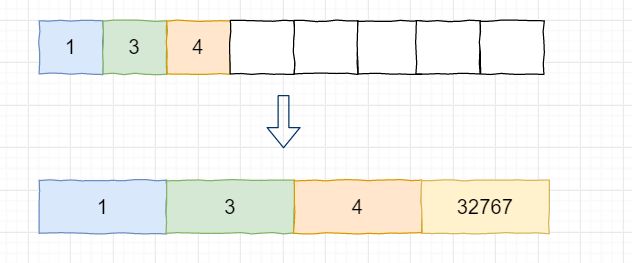
由于intset使用数组的方式实现,因此,key的查询过程可以使用二分查找。另外,intset为了进一步提升查找的效率,规定存储在contents数组中的元素应该是定长的,即占用相同数量的格子。int8_t对应的大小范围是[-128, 127],如果set中元素的值都在这个范围内,那么使用一个content为存储就够了。如果某时插入的元素大小超过了127,那么需要使用最大需要的字节数进行存储。此时,intset中已有元素的大小也会升级到相同的字节数。
例如,起始intset中的1、3、4只使用一个content位,当插入32767时,它需要2个字节才能存放。那么除了使用两个字节存放32767外,已有的1、3、4也需要升级为使用2个content存放。
6. sorted-set
soert-set是一个类似于hash有序的key-value对,其中key为键,它在sorted-set中不重复;value是一个称为score的浮点数,sorted-set内部就是按照score的大小进行排序的。
sorted-set的value内部使用ziplist或是hashtable+skiplist实现。ziplist和hash中使用类似,不同之处在于ziplist中的entry之间按照value进行递增排序。当有新元素插入时,ziplist都需要移动排在新元素之后的元素。它适用于元素个数不多,且元素的内容变化不大的场景。
跳表(skiplist)的结构定义如下:
typedef struct skiplist{
struct zskiplistNode * header, *tail;
unsigned long length;
int level;
} zskiplist;
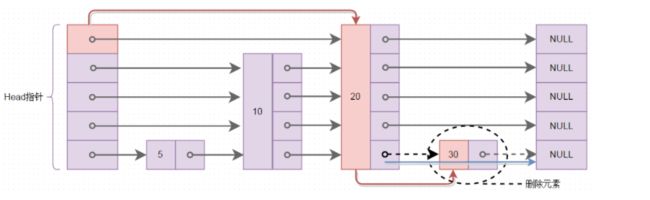
结构图如下所示:

如上图所示,此时skiplist中存储了5、10、20、30四个元素。假设想要查key=30的元素,首先从Head指针数组里最顶层的指针所指的20进行比较,发现30比20要大,则查找就是从20开始往后查找。从查找的过程中可以看出,skiplist跳过了5和10,直接和顶层的20进行比较,避免了向普通链表一样从头往后依次查找。
向skiplist中插入新元素时,由于元素所在的层级的随机性,此时的时间复杂度为O(logn)。例如,在上图所表示的skiplist中插入28,插入的过程示意图如下所示:

skiplist中元素的删除过程为:首先查找要删除的元素,找到后进行指针的移动,进行删除操作。如下所示:
sorted-set在使用skiplist的实现中,Redis为每一个层级的对象都增加span字段,用于表示该层级指向的forward节点和当前节点的距离。结构定义如下所示: