阿里一面面经(半凉)
目录
1.项目
2 指针和引用的区别
3 静态库和动态库的区别
4 gdb调试命令知道哪些
5 stl库容器map和set的底层实现
6 一道法题,求一个集合的所有子集
首先我先说一下整个面试的过程。整个面试过程中首先是对个人的一些项目聊的比较多一些。希望自己、也希望大家在复习的时候把自己做过的项目再进行熟悉一些。
1.项目
关于项目主要问了下面几个方面的问题:
- 项目简介
- 项目中遇到的困难,怎么解决的。
- 项目中对自己提升最大的技术。
主要就是这三个方面,另外不得不说,经历过这么多面试,阿里面试官的气场是比较强大的,一看就是技术比较diao 的大牛。
另外还有下面几个问题。
2 指针和引用的区别
这个问题当初自己只想出来两点,没有回答全。
指针和引用的区别主要有以下几点。
- 访问引用是直接访问,访问指针是间接访问。
- 引用是变量的别名,本身并不单独分配自己的内存空间,而指针拥有自己的内存空间。
- 引用一经初始化,不能再引用其他变量,而指针可以。
- 尽可能的使用引用,不得已时使用指针。
3 静态库和动态库的区别
静态库与共享库的区别和特点如下:
1)包含静态库的程序的体积小,包含共享库的程序的体积大。
2)包含静态库的程序执行快,包含共享库的程序执行慢。
3)静态库编译链接之后将会包含到程序中,程序中会存储一份静态库的副本,共享库编译链接之后只做标记,没有包含方法实现,运行程序会进行动态加载。
4 gdb调试命令知道哪些
关于gdb的基本调试命令,多进程调试命令,以及多线程调试命令,我整理了一篇博文,大家可以参阅,链接如下。
Linux-gdb调试||多线程调试||多进程调试||详解
5 stl库容器map和set的底层实现
首先应该都知道这些知识:
map和set底层是红黑树实现的,unordered_map和unordered_set底层是hash表实现的,那么在实际中选择的时候如何选择?
map和set:
由于底层是红黑树实现的,因此:
优点是,元素的有序性,并且在lgn时间复杂度下可以实现。
缺点是,空间占用率高,因为红黑树中每个结点都是需要额外空间去保存指向孩子结点的指针。
因此,对元素要求有序的可以使用map和set。
unordered_map和unordered_set:
由于底层是hash表实现的,因此:
优点是,查找速度超快
缺点是,建立hash表比较耗时。
因此在对于查找次数多的应用场景下,可以选择unordered_map和unordered_set。
6 一道法题,求一个集合的所有子集
最后呢,面试官 让我做这样一道算法题,求一个集合的所有子集,我想的办法如下图所示。
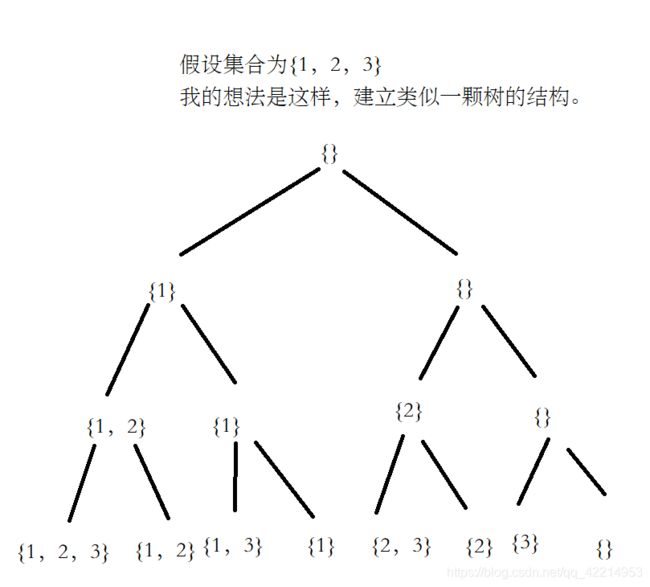
主要的想法是,第二层考虑1,左孩子的化就加入1,右孩子不加1。第三层考虑2,第四层考虑3,那么最后一层结点就是所有的子集,代码实现如下。
/*
//解释:
假设集合有1,2,3,
初始:result为{}
考虑1:result为{1},{}
考虑2:result为{1,2},{1},{2},{}
考虑3:result为{1,2,3},{1,2},{1,3},{1},{2,3},{2},{3},{}
*/
vector> subSet(set s)
{
//模拟一个空集合
set empty;
//存储结果
vector> result;
result.push_back(empty);
//顺序对集合中的每个元素进行考虑
for(auto e:s)
{
//构建树的下一层,左边添加,右边不添加。
vector> temp;
for(auto s:result)
{
//无e
temp.push_back(s);
//有e
s.insert(e);
temp.push_back(s);
}
result = temp;
}
return result;
} 面试的时候就问了上述的这些问题,最后面试官隐含的意思是,如果我能把最后一道算法题按照我的思路做出来就算过关,也不知道我做成这样能不能入他的法眼。反正自我感觉不是很好,一些基础的问题没有完全回答上来。希望我这篇博文对正在找工作的人能有所帮助。