ZooKeeper 集群部署
ZooKeeper 集群部署
部署 ZooKeeper 集群,建议 3 台及以上奇数主机 ( 涉及仲裁问题 )
JAVA、下载、解压、修改属主、组
修改配置文件:
第一步:创建数据目录(每台都要有)
每台服务器先解压软件
mkdir -p /data/zookeeper/{data,logs}
此处我们在 zookeeper 的安装目录中创建一个 data 目录和 logs 目录,分别用于存放数据和日志, 目录和名字可以自己更改,但是后面配置的时候需要和此处创建的目录位置一致
伪集群:
解压到三个不同的目录,重命名:
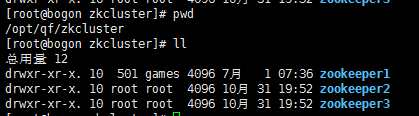
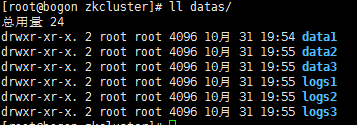
创建不同的数据目录和日志目录:
mkdir -p /opt/qf/zkcluster/datas/data1
mkdir -p /opt/qf/zkcluster/datas/logs1
第二步:创建服务标记
服务标记的作用是用于区分每个 zookeeper 节点的, 在我们上面步骤创建的 data 目录下面创建一个叫 myid 的文件,没有后缀名,在里面添加内容 ,内容为1-255任意数据,但是不同的节点必须唯一
生成节点标识文件
shell > echo “1” > /data/zookeeper/data/myid
shell > echo “2” > /data/zookeeper/data/myid
shell > echo “3” > /data/zookeeper/data/myid
分别在三台服务器上执行,需要跟配置文件中的 server.1\2\3 对应
伪集群:
echo “1”>/opt/qf/zkcluster/datas/data1/myid
echo “2”>/opt/qf/zkcluster/datas/data2/myid
echo “3”>/opt/qf/zkcluster/datas/data3/myid
注意有双引号。

第三步:修改配置文件
将 conf 目录下的 zoo_sample.cf 重命名为 zoo.cfg(zookeeper 默认加载的文件名)
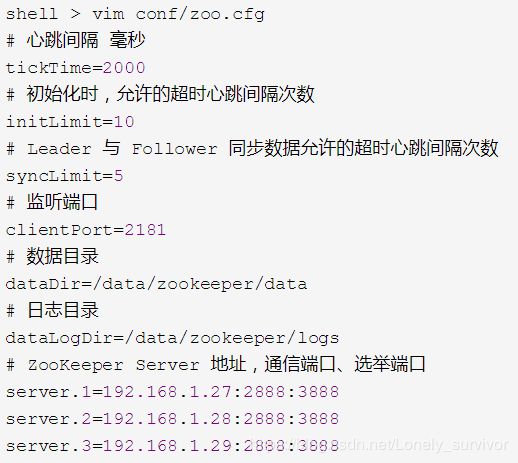
这里的server.1,server.2,server.3对应第二步的标示1,2,3
伪集群:
分别修改端口,通信端口,选举端口。
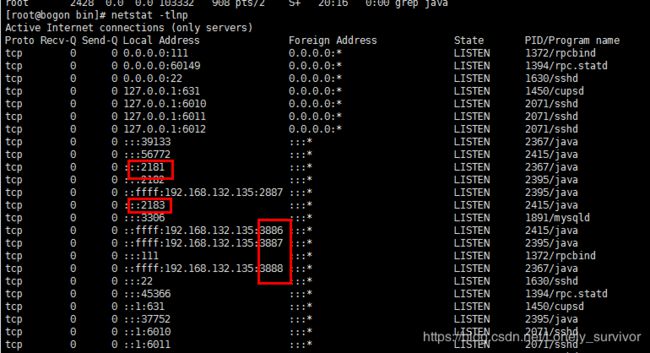
clientPort=2181[2182,2183]
dataDir=/opt/qf/zkcluster/datas/data1[data2,data3]
dataLogDir=/opt/qf/zkcluster/datas/logs1[logs2,logs3]
#集群的配置
server.1=192.168.132.135:2888:3888
server.2=192.168.132.135:2887:3887
server.3=192.168.132.135:2886:3886
三台依次做修改。
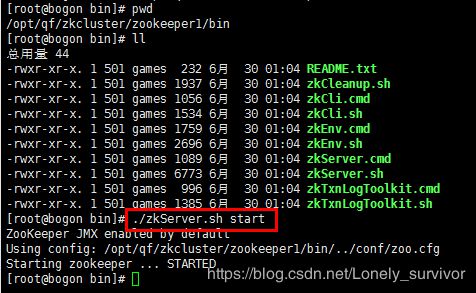
第四步:启动 ZooKeeper
通过 bin 目录中执行 ./zkServer.sh start 启动每个节点,可以通过 ./zkServer.sh status 来查看状态
/usr/local/zookeeper-3.4.10/bin/zkServer.sh start
全部成功启动
/usr/local/zookeeper-3.4.10/bin/zkServer.sh status
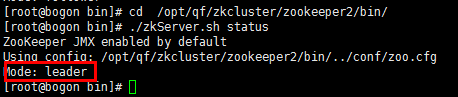
查看状态,datanode03.hadoop 为 leader ,其余两台为 follower
验证选举
sh bin/zkServer.sh stop
关闭 datanode03.hadoop 服务器上的 ZooKeeper,原 leader
再次查看状态,datanode02.hadoop 升级为 leader,datanode01.hadoop 仍为 follower
三台 ZooKeeper Server 组成的集群,当两台故障时,整个集群失败 ( 剩余的一台无法继续提供服务 )
伪集群:
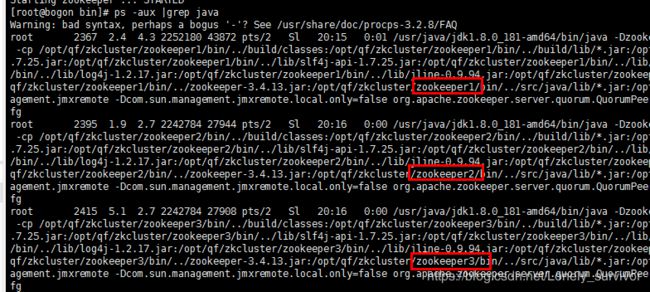
进入不同的目录启动
进程:
端口:
查看状态:./zkServer.sh status


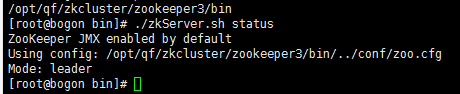
考验下自动选举能力:
杀死leader:kill -9 2489
自动选举: 第三台变为leader
再次启动之前的老主机:等待一会
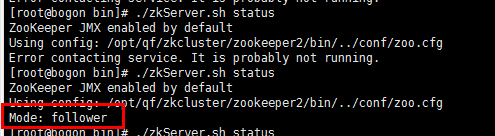
老主机变为follower.
客户端连接
sh bin/zkCli.sh -server 192.168.1.27:2181,192.168.1.28:2181,192.168.1.29:2181
#客户端连接集群,只写一个地址时,当这台 Server 宕机,则客户端连接失败
#同时写多个地址( 全写 )时,除集群失败外,不影响客户端连接
#写多个地址时,以 , 分割,, 两边不能有空格
客户端只连接 1.27,显示只有一个默认的 znode

伪集群:
./zkCli.sh -server 192.168.132.135:2183
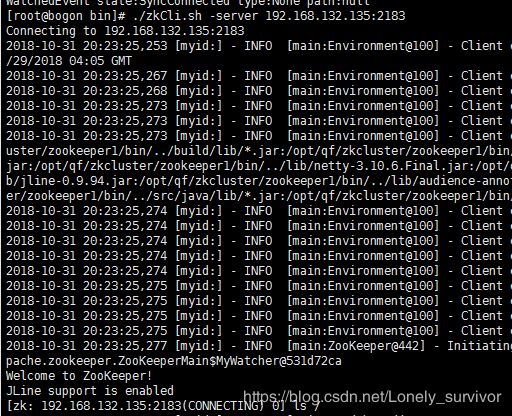
ZooKeeper 集群测试
新客户端连接 1.28,
创建一个 znode
create /zk ‘mydata’

刚才连接的 1.27,可以显示、获取这个新建的 znode, 给这个 znode 重新设置一个值

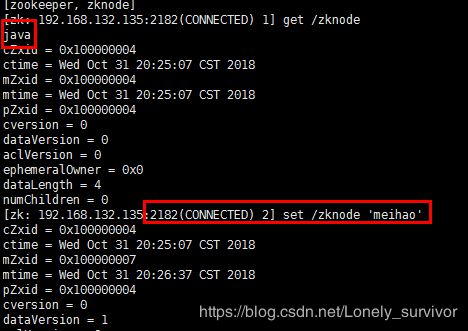
在zookeeper集群中,所有的节点都可以读写数据。
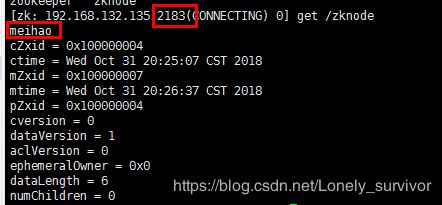
连接 1.28 的客户端,也获取到了更新后的值

删除创建的 znode

如果有多个目录,先删除叶子节点,逐步到最后。
注意:从机也可以删除节点

各节点都没有了:
递归删除:
rmr,可以删除多级目录。
ZooKeeper 集群可以任意读写的!(也就是主从节点都可以)
(一) Zookeeper基础知识、体系结构、数据模型
1zookeeper是一个类似hdfs的树形文件结构, zookeeper可以用来保证数据在(zk)集
群之间的数据的事务性一致
2zookeeper有watch事件,是一次性触发的,当watch监视的数据发生变化时,通
知设置了该watch的client,即watcher
3 zookeeper有三个角色: Leader, Follower, Observer(观察者,也是一个特殊的Follower)
4 zookeeper应用场景:
统一命名服务(Name Service)
配置管理(Configuration Management)
集群管理(Group Membership)
共享锁(Locks)
队列管理
(二) zoo.cfg详解:
tickTime: 基本事件单元,以毫秒为单位。这个时间是作为 Zookeeper服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每隔 tickTime时间就会发送一个心跳。
dataDir: 存储内存中数据库快照的位置,顾名思义就是 Zookeeper
保存数据的目录,默认情况下, Zookeeper将写数据的日志文件也保存在这个目录里。
clientPort: 这个端口就是客户端连接 Zookeeper 服务器的端口, Zookeeper
会监听这个端口,接受客户端的访问请求。
initLimit: 这个配置项是用来配置 Zookeeper接受客户端初始化连接时最长能忍受多少个心跳时间间隔数,当已经超过 10 个心跳的时间(也就是 tickTime)长度后Zookeeper 服务器还没有收到客户端的返回信息,那么表明这个客户端连接失败。总的时间长度就是10*2000=20 秒。
syncLimit: 这个配置项标识 Leader 与 Follower之间发送消息,请求和应答时间长度,最长不能超过多少个 tickTime的时间长度,总的时间长度就是 5*2000=10 秒
#集群配置
server.1=192.168.132.135:2888:3888
server.A = B:C:D
A表示这个是第几号服务器(也就是我们写的myid)
B 是这个服务器的 ip 地址;
C 表示的是这个服务器与集群中的 Leader服务器交换信息的端口;【通信端口】
D 表示的是万一集群中的 Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader【选举端口】