SRILM是一个建立和使用统计语言模型的开源工具包,从1995年开始由SRI 口语技术与研究实验室(SRI Speech Technology and Research Laboratory)开发,现在仍然不断推出新版本,被广泛应用于语音识别、机器翻译等领域。这个工具包包含一组C++类库、一组进行语言模型训练和应用的可执行程序等。利用它可以非常方便地训练和应用语言模型。给定一组连续的词,调用SRILM提供的接口,可以得到这组词出现的概率。
http://www.jianshu.com/p/5b19605792ab
ngram-count -text text.txt -vocab wordlist.txt -order 3 -write count.txt
这里的-text表示读入文件,-vocab表示使用字典,只有在字典中的词才会被统计个数,-order表示使用三元模型,默认即为3,-write为生成的n-gram计数文件,如果还想查看其它命令,可以使用ngram-count -help查看ngram-count -read count.txt -order 3 -lm test.lm -interpolate -kndiscount
这里的-read表示读入n-gram计数文件,-lm表示生成语言模型,-interpolate -kndiscount是平滑方法,具体介绍可以查看 Ngram折扣平滑算法ngram -ppl new.txt -order 3 -lm test.lm > out.ppl
这里的-ppl是指要计算的测试集,-lm加载之前训练好的语言模型,同时将输入放到out.ppl文件中****************************************************************************************************************************************************************************************************************************************************************************************************************************************
SRILM是著名的约翰霍普金斯夏季研讨会(Johns Hopkins Summer Workshop)的产物,诞生于1995年,由SRI实验室的Andreas Stolcke负责开发维护。
关于SRILM的安装,我已经在前面关于moses平台搭建的文章(参见:《Moses相关介绍》和《Ubuntu8.10下moses测试平台搭建全记录》)中介绍过了,这里就不再重复。准确的说,SRILM并不是因机器翻译而诞生的,它主要是为语音识别所开发的,全称为Stanford Research Institute Language Modeling Toolkit。事实上统计机器翻译与语音识别关系千丝万缕,我会在以后的文章中介绍。
SRILM用来构建和应用统计语言模型,主要用于语音识别,统计标注和切分,以及机器翻译,可运行在UNIX及Windows平台上。它主要包含以下几个部分:
• 一组实现的语言模型、支持这些模型的数据结构和各种有用的函数的C++类库;
• 一组建立在这些类库基础上的用于执行标准任务的可执行程序,如训练语言模型,在数据集上对这些语言模型进行测试,对文本进行标注或切分等任务。
• 一组使相关任务变得容易的各种脚本。
SRILM的主要目标是支持语言模型的估计和评测。估计是从训练数据(训练集)中得到一个模型,包括最大似然估计及相应的平滑算法;而评测则是从测试集中计算其困惑度(MIT自然语言处理概率语言模型有相关介绍)。其最基础和最核心的模块是n-gram模块,这也是最早实现的模块,包括两个工具:ngram-count和ngram,相应的被用来估计语言模型和计算语言模型的困惑度。一个标准的语言模型(三元语言模型(trigram),使用Good-Truing打折法和katz回退进行平衡)可以用如下的命令构建:
ngram-count -text TRAINDATA -lm LM
其中LM是输出的语言模型文件,可以用如下的命令进行评测:
ngram -lm LM -ppl TESTDATA -debug 2
其中具体的参数可参看官方网站的帮助文档,如果你已经在linux下编译好了,可以直接使用man调用帮助文档。事实上,统计机器翻译框架主要用的就是n-gram这个模块来训练语言模型。下面我们以欧洲语料库的英语语料为例,解析这个工具的作用。语料库下载地址见:欧洲议会平行语料库。本例子使用的是wmt08里面用于英语语言模型训练的europarl-v3b.en,用于机器翻译的预处理过程tokenize和lowercase此处省略,其规模为1412546句:
1、从语料库中生成n-gram计数文件:
ngram-count -text europarl-v3b.en -order 3 -write europarl.en.count
其中参数-text指向输入文件,此处为europarl-v3b.en;-order指向生成几元的n-gram,即n,此处为3元;-write指向输出文件,此处为europarl.en.count,输出内容为:
...
sweeteners 66
sweeteners should 1
sweeteners should be 1
...
分为两列,第一列为n元词,第二列为相应的频率。如一元词sweeteners在语料库中的频率统计为66次;二元词sweeteners shoul在语料库中的频率统计为1次;三元sweeteners should be在语料库中的频率统计为1次。
2、从上一步生成的计数文件中训练语言模型:
ngram-count -read europarl.en.count -order 3 -lm europarl.en.lm -interpolate -kndiscount
其中参数-read指向输入文件,此处为 europarl.en.count;-order与上同;-lm指向训练好的语言模型输出文件,此处为europarl.en.lm;最后两个参数为所采用的平滑方法,-interpolate为插值平滑,-kndiscount为 modified Kneser-Ney 打折法,这两个是联合使用的。需要补充的是,一般我们训练语言模型时,这两步是合二为一的,这里主要是为了介绍清楚n-gram语言模型训练的步骤细节。
语言模型europarl.en.lm的文件格式如下,为 ARPA文件格式。为了说明方便,文件中的括号是我加上的注释:
\data\
ngram 1=262627 (注:一元词有262627个 )
ngram 2=3708250 (注:二元词有 3708250个)
ngram 3=2707112 (注:三元词有 2707112个)
\1-grams:(注:以下为一元词的基本情况)
-4.891179(注:log(概率),以10为底) ! -1.361815
-6.482389 !) -0.1282758
-6.482389 !’ -0.1282758
-5.254417 "(注:一元词) -0.1470514
-6.482389 "' -0.1282758(注:log(回退权重),以10为底)
...
\2-grams:
-0.02140159 !
-2.266701 ! –
-0.5719482 !)
-0.5719482 !’
-2.023553 " 'Biomass'
-2.023553 " 'vertical'
...
\3-grams:
-0.01154674 the !
-0.01154674 urgent !
-0.01154674 us' !
-1.075004 the ".EU" Top
-0.827616 the ".EU" domain
-0.9724987 the ".EU" top-level ...
3、利用上一步生成的语言模型计算测试集的困惑度:
ngram -ppl devtest2006.en -order 3 -lm europarl.en.lm > europarl.en.lm.ppl
其中测试集采用wmt08用于机器翻译的测试集devtest2006.en,2000句;参数-ppl为对测试集句子进行评分(logP(T),其中P(T)为所有句子的概率乘积)和计算测试集困惑度的参数;europarl.en.lm.ppl为输出结果文件;其他参数同上。输出文件结果如下:
file devtest2006.en: 2000 sentences, 52388 words, 249 OOVs
0 zeroprobs, logprob= -105980 ppl= 90.6875 ppl1= 107.805
第一行文件devtest2006.en的基本信息:2000句,52888个单词,249个未登录词;
第二行为评分的基本情况:无0概率;logP(T)=-105980,ppl==90.6875, ppl1= 107.805,均为困惑度。其公式稍有不同,如下:
ppl=10^{-{logP(T)}/{Sen+Word}}; ppl1=10^{-{logP(T)}/Word}
其中Sen和Word分别代表句子和单词数。
附:SRILM主页推荐的书目和文献。
入门——了解语言模型尤其是n-gram模型的参考书目章节:
• 《自然语言处理综论》第一版第6章,第二版第4章(Speech and Language Processing by Dan Jurafsky and Jim Martin (chapter 6 in the 1st edition, chapter 4 in the 2nd edition) )
• 《统计自然语言处理基础》第6章。(Foundations of Statistical Natural Language Processing by Chris Manning and Hinrich Schütze (chapter 6))
深入学习相关文献:
• A. Stolcke, SRILM - An Extensible Language Modeling Toolkit, in Proc. Intl. Conf. Spoken Language Processing, Denver, Colorado, September 2002. Gives an overview of SRILM design and functionality.
• D. Jurafsky, Language Modeling, Lecture 11 of his course on "Speech Recognition and Synthesis" at Stanford. Excellent introduction to the basic concepts in LM.
• J. Goodman, The State of The Art in Language Modeling, presented at the 6th Conference of the Association for Machine Translation in the Americas (AMTA), Tiburon, CA, October, 2002.
Tutorial presentation and overview of current LM techniques (with emphasis on machine translation).
• K. Kirchhoff, J. Bilmes, and K. Duh, Factored Language Models Tutorial, Tech. Report UWEETR-2007-0003, Dept. of EE, U. Washington, June 2007. This report serves as both a tutorial and reference manual on FLMs.
• S. F. Chen and J. Goodman, An Empirical Study of Smoothing Techniques for Language Modeling, Tech. Report TR-10-98, Computer Science Group, Harvard U., Cambridge, MA, August 1998 (original postscript document). Excellent overview and comparative study of smoothing methods. Served as a reference for many of the methods implemented in SRILM.
注:原创文章,转载请注明出处“我爱自然语言处理”:www.52nlp.cn
****************************************************************************************************************************************************************************************************************************************************************************************************************************************
转自:
一、小数据
假设有去除特殊符号的训练文本trainfile.txt,以及测试文本testfile.txt,那么训练一个语言模型以及对其进行评测的步骤如下:
1:词频统计
ngram-count -text trainfile.txt -order 3 -write trainfile.count
其中-order 3为3-gram,trainfile.count为统计词频的文本
2:模型训练
ngram-count -read trainfile.count -order 3 -lm trainfile.lm -interpolate -kndiscount
其中trainfile.lm为生成的语言模型,-interpolate和-kndiscount为插值与折回参数
3:测试(困惑度计算)
ngram -ppl testfile.txt -order 3 -lm trainfile.lm -debug 2 > file.ppl
其中testfile.txt为测试文本,-debug 2为对每一行进行困惑度计算,类似还有-debug 0 , -debug 1, -debug 3等,最后 将困惑度的结果输出到file.ppl。
二、大数据(BigLM)
对于大文本的语言模型训练不能使用上面的方法,主要思想是将文本切分,分别计算,然后合并。步骤如下:
1:切分数据
split -l 10000 trainfile.txt filedir/
即每10000行数据为一个新文本存到filedir目录下。
2:对每个文本统计词频
make-bath-counts filepath.txt 1 cat ./counts -order 3
其中filepath.txt为切分文件的全路径,可以用命令实现:ls $(echo $PWD)/* > filepath.txt,将统计的词频结果存放在counts目录下
3:合并counts文本并压缩
merge-batch-counts ./counts
不解释
4:训练语言模型
make-big-lm -read ../counts/*.ngrams.gz -lm ../split.lm -order 3
用法同ngram-counts
5: 测评(计算困惑度)
ngram -ppl filepath.txt -order 3 -lm split.lm -debug 2 > file.ppl
****************************************************************************************************************************************************************************************************************************************************************************************************************************************
转自:http://www.leexiang.com/building-a-large-lm-with-srilm
原理上,语言模型模型越大,机器翻译质量越好,但是当语言模型的训练集非常大时,例如GB级别的时候,受限于时间和机器的内存等因素,传统的ngram-count训练方式无法满足实际需要,因此srilm的FAQ中提到了训练语言模型的方法,基本思想就是将大文件拆分成多个小文件,然后再将多个小文件的count合并,完成最终的语言模型训练。
其基本方法:
1. 把大文件分割成小文件,放在一个目录下,然后生成一个文件名列表文件,如filelist ,一般使用按行分割的形式,split -l 100 test.txt out
使用split将一个大文件分成最多26*26(使用字母后缀,这是默认的行为)或者是100(使用数字后缀,需要-d参数)个文件,可以将文件按行拆分(使用-l num参数)或者是按大小拆分(使用-b size参数),还可以给出文件的前缀(或者使用默认的x)。在进行拆分的时候将文件会将每num行放到一个文件中,文件按字母序产生,对于语言模型的使用来说,一般使用按行分割的形式 split -l 100 big_file split_file
2. 使用 make-batch-counts分别统计各个分割文件中的词频,make-batch-counts filelist 5 cat counts -order 5,其中filelist为需要统计的小文件名列表,5表示每5个小文件用于一次ngram-count训练,cat lmcount 表示输出到counts,后续则是提交给ngram-count的参数
3. 使用merge-batch-counts将所有的小count文件合并成一个大的count文件,merge-batch-counts [ -l N ] counts [ filename-list ],将counts目录下的所有文件合并成一个文件,如果有些文件不用参与合并,可以在最后添加一个filename-list,只有在filename-list里面出现的文件才会被用于合并;-l N参数之处,一次同时合并N个文件
4. 使用make-big-lm生成语言模型,参数类似于ngram-count
更详细的方法可以参考 http://joshua-decoder.org/4.0/large-lms.html
****************************************************************************************************************************************************************************************************************************************************************************************************************************************
斯坦福大学自然语言处理第四课“语言模型(Language Modeling)”
一、课程介绍
斯坦福大学于2012年3月在Coursera启动了在线自然语言处理课程,由NLP领域大牛Dan Jurafsky 和 Chirs Manning教授授课:
https://class.coursera.org/nlp/
以下是本课程的学习笔记,以课程PPT/PDF为主,其他参考资料为辅,融入个人拓展、注解,抛砖引玉,欢迎大家在“我爱公开课”上一起探讨学习。
课件汇总下载地址:斯坦福大学自然语言处理公开课课件汇总
二、语言模型(Language Model)
1)N-gram介绍
在实际应用中,我们经常需要解决这样一类问题:如何计算一个句子的概率?如:
- 机器翻译:P(high winds tonite) > P(large winds tonite)
- 拼写纠错:P(about fifteen minutes from) > P(about fifteen minuets from)
- 语音识别:P(I saw a van) >> P(eyes awe of an)
- 音字转换:P(你现在干什么|nixianzaiganshenme) > P(你西安在干什么|nixianzaiganshenme)
- 自动文摘、问答系统、... ...
以上问题的形式化表示如下:
p(S)=p(w1,w2,w3,w4,w5,…,wn)
=p(w1)p(w2|w1)p(w3|w1,w2)...p(wn|w1,w2,...,wn-1)//链规则
p(S)被称为语言模型,即用来计算一个句子概率的模型。
那么,如何计算p(wi|w1,w2,...,wi-1)呢?最简单、直接的方法是直接计数做除法,如下:
p(wi|w1,w2,...,wi-1) = p(w1,w2,...,wi-1,wi) / p(w1,w2,...,wi-1)
但是,这里面临两个重要的问题:数据稀疏严重;参数空间过大,无法实用。
基于马尔科夫假设(Markov Assumption):下一个词的出现仅依赖于它前面的一个或几个词。
- 假设下一个词的出现依赖它前面的一个词,则有:
p(S)=p(w1)p(w2|w1)p(w3|w1,w2)...p(wn|w1,w2,...,wn-1)
=p(w1)p(w2|w1)p(w3|w2)...p(wn|wn-1) // bigram
- 假设下一个词的出现依赖它前面的两个词,则有:
p(S)=p(w1)p(w2|w1)p(w3|w1,w2)...p(wn|w1,w2,...,wn-1)
=p(w1)p(w2|w1)p(w3|w1,w2)...p(wn|wn-1,wn-2) // trigram
那么,我们在面临实际问题时,如何选择依赖词的个数,即n。
- 更大的n:对下一个词出现的约束信息更多,具有更大的辨别力;
- 更小的n:在训练语料库中出现的次数更多,具有更可靠的统计信息,具有更高的可靠性。
理论上,n越大越好,经验上,trigram用的最多,尽管如此,原则上,能用bigram解决,绝不使用trigram。
2)构造语言模型
通常,通过计算最大似然估计(Maximum Likelihood Estimate)构造语言模型,这是对训练数据的最佳估计,公式如下:
p(w1|wi-1) = count(wi1-, wi) / count(wi-1)
如给定句子集“ I am Sam
Sam I am
I do not like green eggs and ham ”
部分bigram语言模型如下所示:

c(wi)如下:

c(wi-1,wi)如下:

则bigram为:

那么,句子“ I want english food ”的概率为:
p( I want english food )=p(I|)
× P(want|I)
× P(english|want)
× P(food|english)
× P(|food)
= .000031
为了避免数据溢出、提高性能,通常会使用取log后使用加法运算替代乘法运算。
log(p1*p2*p3*p4) = log(p1) + log(p2) + log(p3) + log(p4)
推荐开源语言模型工具:
- SRILM(http://www.speech.sri.com/projects/srilm/)
- IRSTLM(http://hlt.fbk.eu/en/irstlm)
- MITLM(http://code.google.com/p/mitlm/)
- BerkeleyLM(http://code.google.com/p/berkeleylm/)
推荐开源n-gram数据集:
- Google Web1T5-gram(http://googleresearch.blogspot.com/2006/08/all-our-n-gram-are-belong-to-you.html)
Total number of tokens: 1,306,807,412,486
Total number of sentences: 150,727,365,731
Total number of unigrams: 95,998,281
Total number of bigrams: 646,439,858
Total number of trigrams: 1,312,972,925
Total number of fourgrams: 1,396,154,236
Total number of fivegrams: 1,149,361,413
Total number of n-grams: 4,600,926,713
- Google Book N-grams(http://books.google.com/ngrams/)
- Chinese Web 5-gram(http://www.ldc.upenn.edu/Catalog/catalogEntry.jsp?catalogId=LDC2010T06)
3)语言模型评价
语言模型构造完成后,如何确定好坏呢? 目前主要有两种评价方法:
- 实用方法:通过查看该模型在实际应用(如拼写检查、机器翻译)中的表现来评价,优点是直观、实用,缺点是缺乏针对性、不够客观;
- 理论方法:迷惑度/困惑度/混乱度(preplexity),其基本思想是给测试集赋予较高概率值的语言模型较好,公式如下:

由公式可知,迷惑度越小,句子概率越大,语言模型越好。使用《华尔街日报》训练数据规模为38million words构造n-gram语言模型,测试集规模为1.5million words,迷惑度如下表所示:

4)数据稀疏与平滑技术
大规模数据统计方法与有限的训练语料之间必然产生数据稀疏问题,导致零概率问题,符合经典的zip'f定律。如IBM, Brown:366M英语语料训练trigram,在测试语料中,有14.7%的trigram和2.2%的bigram在训练语料中未出现。
数据稀疏问题定义:“The problem of data sparseness, also known as the zero-frequency problem arises when analyses contain configurations that never occurred in the training corpus. Then it is not possible to estimate probabilities from observed frequencies, and some other estimation scheme that can generalize (that configurations) from the training data has to be used. —— Dagan”。
人们为理论模型实用化而进行了众多尝试与努力,诞生了一系列经典的平滑技术,它们的基本思想是“降低已出现n-gram条件概率分布,以使未出现的n-gram条件概率分布非零”,且经数据平滑后一定保证概率和为1,详细如下:
- Add-one(Laplace) Smoothing
加一平滑法,又称拉普拉斯定律,其保证每个n-gram在训练语料中至少出现1次,以bigram为例,公式如下:

其中,V是所有bigram的个数。
承接上一节给的例子,经Add-one Smoothing后,c(wi-1, wi)如下所示:

则bigram为:

在V >> c(wi-1)时,即训练语料库中绝大部分n-gram未出现的情况(一般都是如此),Add-one Smoothing后有些“喧宾夺主”的现象,效果不佳。那么,可以对该方法扩展以缓解此问题,如Lidstone's Law,Jeffreys-Perks Law。
- Good-Turing Smoothing
其基本思想是利用频率的类别信息对频率进行平滑。调整出现频率为c的n-gram频率为c*:
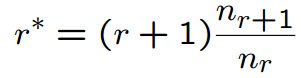


但是,当nr+1或者nr > nr+1时,使得模型质量变差,如下图所示:

直接的改进策略就是“对出现次数超过某个阈值的gram,不进行平滑,阈值一般取8~10”,其他方法请参见“Simple Good-Turing”。
- Interpolation Smoothing
不管是Add-one,还是Good Turing平滑技术,对于未出现的n-gram都一视同仁,难免存在不合理(事件发生概率存在差别),所以这里再介绍一种线性插值平滑技术,其基本思想是将高阶模型和低阶模型作线性组合,利用低元n-gram模型对高元n-gram模型进行线性插值。因为在没有足够的数据对高元n-gram模型进行概率估计时,低元n-gram模型通常可以提供有用的信息。公式如下:

扩展方式(上下文相关)为:
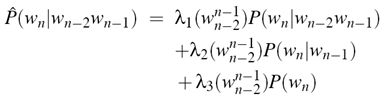
λs可以通过EM算法来估计,具体步骤如下:
- 首先,确定三种数据:Training data、Held-out data和Test data;

- 然后,根据Training data构造初始的语言模型,并确定初始的λs(如均为1);
- 最后,基于EM算法迭代地优化λs,使得Held-out data概率(如下式)最大化。

- Kneser-Ney Smoothing
- Web-scale LMs
如Google N-gram语料库,压缩文件大小为27.9G,解压后1T左右,面对如此庞大的语料资源,使用前一般需要先剪枝(Pruning)处理,缩小规模,如仅使用出现频率大于threshold的n-gram,过滤高阶的n-gram(如仅使用n<=3的资源),基于熵值剪枝,等等。
另外,在存储优化方面也需要做一些优化,如使用trie数据结构存储,借助bloom filter辅助查询,把string映射为int类型处理(基于huffman编码、Varint等方法),float/double转成int类型(如概率值精确到小数点后6位,然后乘10E6,即可将浮点数转为整数)。
2007年Google Inc.的Brants et al.提出了针对大规模n-gram的平滑技术——“Stupid Backoff”,公式如下:

数据平滑技术是构造高鲁棒性语言模型的重要手段,且数据平滑的效果与训练语料库的规模有关。训练语料库规模越小,数据平滑的效果越显著;训练语料库规模越大,数据平滑的效果越不显著,甚至可以忽略不计——锦上添花。
5)语言模型变种
- Class-based N-gram Model
该方法基于词类建立语言模型,以缓解数据稀疏问题,且可以方便融合部分语法信息。
- Topic-based N-gram Model
该方法将训练集按主题划分成多个子集,并对每个子集分别建立N-gram语言模型,以解决语言模型的主题自适应问题。架构如下:
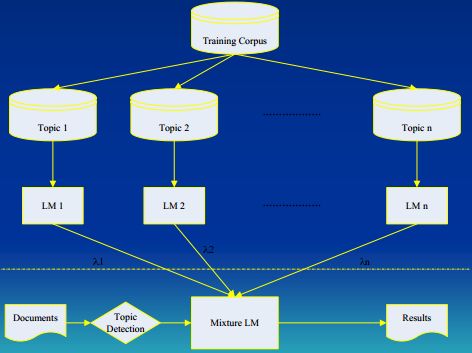
- Cache-based N-gram Model
该方法利用cache缓存前一时刻的信息,以用于计算当前时刻概率,以解决语言模型动态自适应问题。
-People tends to use words as few as possible in the article.
-If a word has been used, it would possibly be used again in the future.
架构如下:

猜测这是目前QQ、搜狗、谷歌等智能拼音输入法所采用策略,即针对用户个性化输入日志建立基于cache的语言模型,用于对通用语言模型输出结果的调权,实现输入法的个性化、智能化。由于动态自适应模块的引入,产品越用越智能,越用越好用,越用越上瘾。
- Skipping N-gram Model&Trigger-based N-gram Model
二者核心思想都是刻画远距离约束关系。
- 指数语言模型:最大熵模型MaxEnt、最大熵马尔科夫模型MEMM、条件随机域模型CRF
传统的n-gram语言模型,只是考虑了词形方面的特征,而没有词性以及语义层面上的知识,并且数据稀疏问题严重,经典的平滑技术也都是从统计学角度解决,未考虑语法、语义等语言学作用。
MaxEnt、MEMM、CRF可以更好的融入多种知识源,刻画语言序列特点,较好的用于解决序列标注问题。
三、参考资料
- Lecture Slides: Language Modeling
- http://en.wikipedia.org
- 关毅,统计自然语言处理基础 课程PPT
- 微软拼音输入法团队,语言模型的基本概念
- 肖镜辉,统计语言模型简介
- fandywang,统计语言模型
-
Stanley F. Chen and Joshua Goodman. An empirical study of smoothing techniques for language modeling. Computer Speech andLanguage, 13:359-394, October 1999.
- Thorsten Brants et al. Large Language Models in Machine Translation
- Gale & Sampson, Good-Turing Smoothing Without Tears
- Bill MacCartney,NLP Lunch Tutorial: Smoothing,2005
P.S. : 基于本次笔记,整理了一份slides,分享下:统计语言模型(fandywang 20121106)
****************************************************************************************************************************************************************************************************************************************************************************************************************************************
转自:http://blog.csdn.net/yqzhao/article/details/7932056
最近学习了一下SRILM的源代码,分享一下学习笔记(最新完整版本),希望能够对大家了解SRI语言模型训练工具有些许帮助。限于本人水平,不足之处,望大家多多指教。
笔记的主要内容使用starUML及其逆向工程工具绘制,主要针对SRILM的训练(ngram-count),内含5个jpg文件:
- 类图--与ngram-count相关的主要类的静态图;
- ngram-count--从语料训练出模型的主要流程;
- lmstats.countfile--ngram-count的子流程,用于构建词汇表和统计ngram的频度
- ngram.estimate--ngram-count的子流程,在词汇表和ngram频度的基础上计算ngram条件概率以及backoff权值的过程
- ngram.read--与训练无关,分析读取ARPA格式的语言模型的过程
SRILM训练ngram的过程简单说来,可归结为以下几个步骤:
- 先建立Vocab(词汇表)类型与LMStats(用于ngram统计)类型的两个实例(即vocab和intStats,intStats中存有vocab的一个引用);
- 调用intStats的countFile函数完成(对输入语料文件中)ngram的统计,这其中也包括词汇表的构建(以及词汇索引映射的构建);
- 建立Discount*的一个数组(长度为order参数的值,即要训练的模型的ngram的最大阶数),按选定的平滑方式计算各阶的折扣率,并保存其中;
- 建立Ngram类型(语言模型类)的实例(即lm),调用其estimate函数(以折扣率数组和ngram统计类的对象为参数),计算各阶ngram的概率及bow,完成语言模型的训练;
- 按训练命令参数选项,输出训练好的语言模型、ngram的频度统计结果、词汇表、词汇索引表等到相应的指定文件中。
笔记中对这个流程做了较详细的说明,下面补充两点内容(主要数据结构的内存布局和ngram条件概率计算式中的参量说明),可以作为笔记内容的基线,便于从总体上把握ngram-count的逻辑。
一、SRILM中所用到的主要数据结构的内存布局
Trie:trie树,以hash表实现,做ngram统计和计算ngram的概率值以及backoff weight都以此为基础
Vocab:词汇表,内含一个以词形为键获取索引值的hash表,以及一个通过索引值(即下标)获得词形的Array
LMStats:负责ngram频度统计,主要成员counts是一棵trie树,从树根到某个结点的路径给出了一个以正常顺序(从左向右)的ngram的各个元的索引
BOnode:Ngram 的主要基础数据结构,用于存储n-1阶gram的backoff权值(存于bow域),以及以此n-1阶gram为历史的所有n阶gram的概率值(存于 probs域);probs域为一hash表,以n阶gram的第n个元素(在词汇表vocab中)的索引值为键,以此n阶gram的频度的log值(以 10为底)为值
Ngram:继承LM,其主要成员contexts为一棵trie树,从根到某个结点的路径是一个n-1阶gram的逆序(从右向左),其bow域存放该n-1-gram在正序情况下的backoff权值,其probs域则为以(正序下)该n-1-gram为历史的(所有)n-gram的概率值(的对数)
二、参数说明
ngram的概率值计算公式为(参见http://ssli.ee.washington.edu/people/duh/papers/flm-manual.pdf):
SRILM训练语言模型的目的就是统计给定语料中的ngram,根据上式算出其相应的(条件)概率值。
-
顶
- 1
-
踩