我用图片带你追源码——并发编程之线程安全的集合
线程安全的集合
-
-
-
- Java集合框架概述(一)——List接口要点详述
- Java集合框架概述(二)——泛型集合与Collections工具类
- Java集合框架概述(三)——HashSet去重原理(HashCode)
- Java集合框架概述(四)——Map体系集合与底层实现原理
-
-
- 一 、集合相关知识回顾
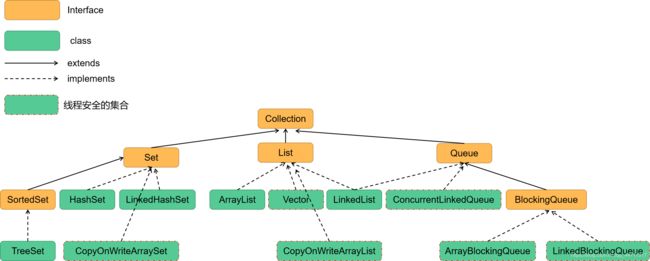
- 二、 集合框架图(Map略去)
- 三、 Collection中的工具方法
-
- synchronizedList(List list) 为例
-
- 1.源码分析
- 2. 保证线程的安全性
- 3. 代理的思想
- 4. 小结
- 四、CopyOnWriteArrayList类
-
- 1. 读写锁的了解
-
- 用真挚的钥匙打开Java多线程之锁,从此Java中有我,我中有Java!
- 2. 源码分析
- 3. CopyOnWriteArrayList的读写互斥吗?
- 4. 如何使用?
- 5. vector与CopyOnWriteArrayList
- 6. 小结
- 五、CopyOnWriteArraySet类
-
- 源码分析
- 六、 ConcurrentHashMap类
-
- HashMap
- HashTable
- ConcurrentHashMap
- ConcurrentHashMap源码分析
如果您之前对集合相关的概念有一定的了解,那对这篇博客的阅读一定会使你对集合有一个更加广阔的了解,如果您对集合的概念有些模糊了,您可以主动点开以下链接,希望对您有帮助吧!
-
Java集合框架概述(一)——List接口要点详述
-
Java集合框架概述(二)——泛型集合与Collections工具类
-
Java集合框架概述(三)——HashSet去重原理(HashCode)
-
Java集合框架概述(四)——Map体系集合与底层实现原理
一 、集合相关知识回顾
以下基本的知识概要在博文开头的链接都有详细的讲述,如需详细可点开阅览。
-
ArrayList
数组结构实现,查询快,增删慢
JDK1.2版本。运行效率快,线程不安全 -
LinkedList
链表实现,查询慢、增删快 -
Vector
数组结构实现,查询快,增删慢
JDK1.0版本。运行效率慢,线程安全 -
HashSet
此类实现Set接口,由哈希表(实际为HashMap实例)支持。 对set的迭代次序不作任何保证; 特别是,它不能保证顺序在一段时间内保持不变。 这个类允许null元素。(HashSet基于HashCode来实现元素的不可重复) -
SortedSort
Set进一步提供其元素的总排序 。 元素使用他们的自然顺序,或通常在创建有序Set时提供的Comparator进行排序。 改Set的迭代器将以递增的元素顺序遍历集合。 提供了几个额外的操作来利用订购。 (此接口是该组类似物SortedMap)。 -
LinkedHashSet
哈希表和链表实现的Set接口,具有可预测的迭代次序。 这种实现不同于HashSet,它维持于所有条目的运行双向链表。 即LinkedHashSet可以为我们保留插入顺序。 -
TreeSet
实现升降序,如果需要利用TreeSet进行排序,必须让比较对象实现Comparable接口,并重写compareTo()方法,在该方法定义排序条件(按什么排序)、排序方式(升序还是降序)。 -
HashMap
基于哈希表的实现的Map接口。 此实现提供了所有可选的映射操作,并允许null的值和null键。( 除了它是不同步的,并允许null之外,HashMap类大致相当于Hashtable)。这个类不能保证映射的顺序; 特别是,它不能保证该顺序恒久不变。
JDK1.2版本,线程不安全,运行效率快;允许使用null作为Key或者是value。 -
Hashtable
该类实现了一个哈希表,它将键映射到值。 任何非null对象都可以用作键值或值。
为了从散列表成功存储和检索对象,用作键的对象必须实现hashCode方法和equals方法。
JDK1.0版本,线程安全,运行效率慢;不允许使用null作为Key或者是value。 -
TreeMap
该方法可以讲Map中的键值对按照键值的进行自然排序;
二、 集合框架图(Map略去)
三、 Collection中的工具方法
在之前的文章中有提到过Collection工具类的几个简单的方法:
| 方法 | 描述 |
|---|---|
public static void reverse(List list) |
反转集合中元素的顺序 |
public static void shuffle(List list) |
随机重置集合元素中的顺序 |
public static void sort(List list) |
升序排序(元素必须实现Comparable接口) |
当然,它也提供了多个可以获得线程安全集合的方法:
| 方法 | 描述 |
|---|---|
static |
返回由指定集合支持的同步(线程安全)集合。 |
static |
返回由指定列表支持的同步(线程安全)列表。 |
static |
返回由指定地图支持的同步(线程安全)映射。 |
static |
返回由指定集合支持的同步(线程安全)集。 |
static |
返回由指定的排序映射支持的同步(线程安全)排序映射。 |
static |
返回由指定的排序集支持的同步(线程安全)排序集。 |
synchronizedList(List list) 为例
1.源码分析
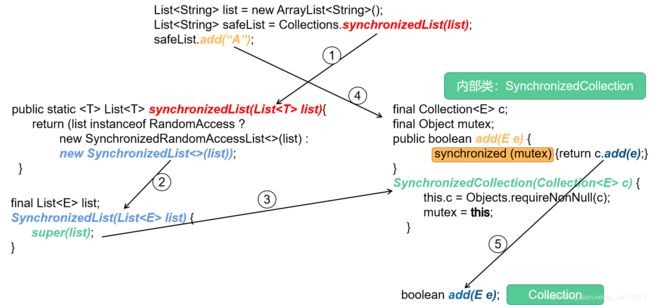
①:点进去之后,会把我们的list传进去,然后根据随机访问类型来进行一个3元运算符的判断,判断的结果就是new一个新的对象,以new SynchronizedList<>(list))为例;
②: SynchronizedList<>(list))构造方法中将用户传进来的list交给了父类,且把list付给了自己的一个属性final List
③: SynchronizedList<>(list))的父类将传进来了list在不为空的条件下,将它存到了final Collection,并且会拿到一个内部类对象mutex即相当于一个锁对象;
④:当使用对集合操作的方法时,这里以add为例,通过内部类对象使用内部类方法add,该方法必须拿到所标记才能访问,进而使用该方调用普通的add方法(⑤);
总体来看,通过对原来的集合进行了简单的包装,即加了一个锁对象mutex来保证线程的安全性;(mutex是一个实例变量,每个集合只有一个该实例变量)
2. 保证线程的安全性
如当多个对集合操作的方法需要执行时,需要拿到锁标记才可以操作集合,将原来可能并发执行的线程不安全的集合,升级为串行执行的线程安全的集合;

3. 代理的思想

当我们使用的某个类,不能满足当前需求的时候,不需要对原来的类进行操作,而是再加一个类 ,增强其功能,这就是proxy,代理;包括现在流行的Spring框架核心就两块:工厂+代理;
4. 小结
- JDK1.2提供,接口统一、维护性高,但因为都是使用
synchronizedList互斥锁实现,因此性能上没有提升;所以实质上,该方法和使用Vector以及HashTable区别不大;
四、CopyOnWriteArrayList类
1. 读写锁的了解
了解读写锁实质上是对该类设计模式的了解,因为该类设计模式上和读写锁有区别也有相似之处放在一起理解会更加印象深刻;提供一个之前关于读写锁相关的链接:
对于读写操作来说,写锁是互斥的,不能并发执行,而读锁不是互斥的可以并发执行,因此对于互斥锁来说,不存在读写之别,因为互斥,所以都不能并发,相比于此,读写锁能够大大提高效率。
-
用真挚的钥匙打开Java多线程之锁,从此Java中有我,我中有Java!
2. 源码分析
首先接触一个新的类,我们不应该去尝试搞懂对他的定义,你需要通过阅读源码理解它实质上做了什么事情,进而你会知道它名字的含义和由来,这是最重要的;
- 写操作(以
add为例)
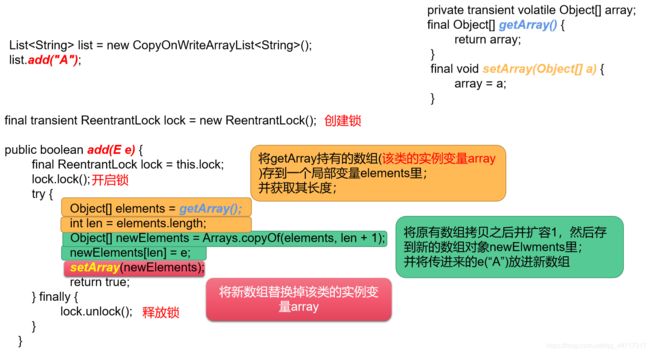
对于写操作,这里用了一个比较巧妙的方式,即拿到当前类的实例变量array,付给一个新的对象数组elements,然后基于该数组进行具体的修改,即将elments的值赋给newElements,并将newElements容量加一,然后把传进来的e(即这里的字符“A”)存进newElements,等一切就绪,然后直接将新的数组替换掉该类的实例变量array;
&esmp;总的来说,在数据的加入过程,即写的过程,并没有对类的实例变量array进行任何的操作,而仅仅是新建一个对象数组,在新建的对象数组操作完毕之后再进行对array的替换;
当多个写操作对数组进行操作的时候,因为有重入锁的原因,只能串行执行,不支持并发,保证了线程的安全; - 读方法
public E get(int index) {
return get(getArray(), index);
}
显然写操作并没有锁对象,而是直接存储,支持并发执行;
3. CopyOnWriteArrayList的读写互斥吗?
显然是不互斥的,这得益于写操作中那个巧妙的设计:即在进行写操作的时候不是对类的实例变量啊array进行操作,而是在新建的数组进行写操作,当写入完毕后直接替换;显然当多个读操作和写操作并发执行的时候,读的过程中不会看到写操作对数字操作的的过程,因此线程是安全的,读写是不互斥的!
这里可以类比App的更新,比如QQ在进行版本更新的时候,影响用户的使用吗?显然不会,程序猿会将新版本测试完毕之后,将新版本的代码替换掉旧版本,显然用户在使用的时候,功能上使用并不会受到影响,因此类比这里读写也不是互斥的;
因此,该实现类不仅线程安全,而且在读操作比较多的情境之下,会使程序效率翻倍!!!
4. 如何使用?
使用方式和ArrayList是一模一样的,这也体现了一种设计模式:接口引用指向实现类对象,更容易更换实现,是一种很好的解耦办法

5. vector与CopyOnWriteArrayList
如果在程序开发过程中,我们需要一个线程安全的List,尽量不使用也不建议使用Vector,在早期的JDK版本当中我们会使用Vector,但是因为效率比较低(Vector所有的方法都加了重入锁,互斥,不支持并发),因此在提供了高效的线程安全的CopyOnWriteArrayList集合类之后(CopyOnWriteArrayList读写、读读均支持并发),已经渐渐淘汰了对Vector的使用;
6. 小结
- 线程安全的
ArrayList,加强版读写分离(读写不互斥); - 写有锁,读无锁,读写之间不阻塞,优于读写锁;
- 写入时,先
copy一个容器副本、在添加新元素,最后替换引用。 - 使用方式于
ArrayList无异;
五、CopyOnWriteArraySet类
CopyOnWriteArraySet底层实现是CopyOnWriteArrayList,但是List的特点是有序有下标,元素不可重复,关键点:怎么实现去重的呢?
private final CopyOnWriteArrayList<E> al; //底层实现 ArrayList
public CopyOnWriteArraySet() {
al = new CopyOnWriteArrayList<E>();
}
源码分析
- 以
add方法为例,看一下Set的去重原理
/**
* Appends the element, if not present.
*
* @param e element to be added to this list, if absent
* @return {@code true} if the element was added
*/
public boolean addIfAbsent(E e) {
Object[] snapshot = getArray();
return indexOf(e, snapshot, 0, snapshot.length) >= 0 ? false :
addIfAbsent(e, snapshot);
}
/**
* A version of addIfAbsent using the strong hint that given
* recent snapshot does not contain e.
*/
private boolean addIfAbsent(E e, Object[] snapshot) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] current = getArray();
int len = current.length;
if (snapshot != current) {
// Optimize for lost race to another addXXX operation
int common = Math.min(snapshot.length, len);
for (int i = 0; i < common; i++)
if (current[i] != snapshot[i] && eq(e, current[i]))
return false;
if (indexOf(e, current, common, len) >= 0)
return false;
}
Object[] newElements = Arrays.copyOf(current, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
关键的代码如下,其余和CopyOnWriteArrayList相似

六、 ConcurrentHashMap类
HashMap
HashMap:HashMap是线程不安全的,在并发环境下,可能会形成环状链表(扩容时可能造成),导致get操作时,cpu空转,所以,在并发环境中使用HashMap是非常危险的。
横向看Map数组状,存储了16个主要元素,接着每一个元素下有挂靠了以链表结构存储的其他元素。
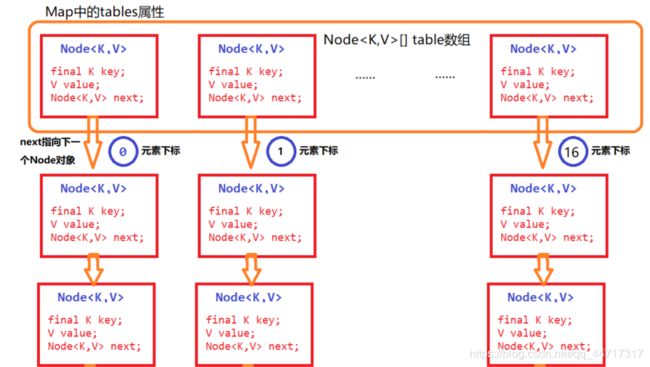
推荐阅读:HashMap实现原理及源码分析
但是怎么保证线程的安全性呢?毫无疑问讲就是通过加锁,因此引入线程安全的HashTable;
HashTable
HashTable和HashMap区别:
- 1.HashTable不允许key和value为null;
- 2.HashTable是线程安全的。
HashTable使用的是synchronized互斥锁,在多线程访问时候,因为一个临界资源 对象只有一把锁,因此当某个线程那到锁标记操作该对象时,那其他线程只能阻塞,不支持并发执行,相当于将所有的操作串行化,在高并发场景中性能就会非常差。
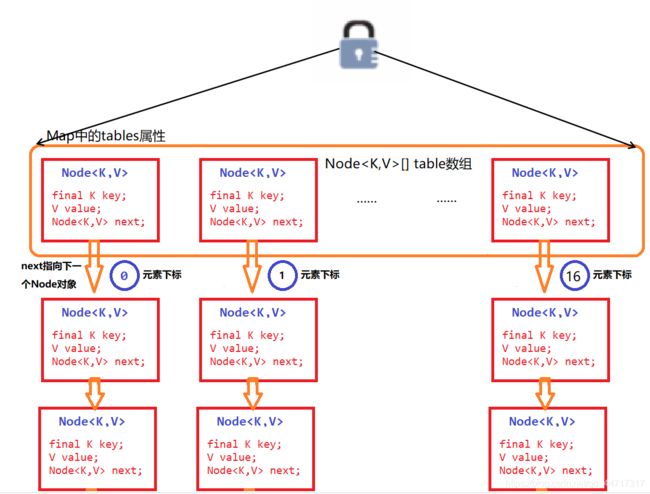
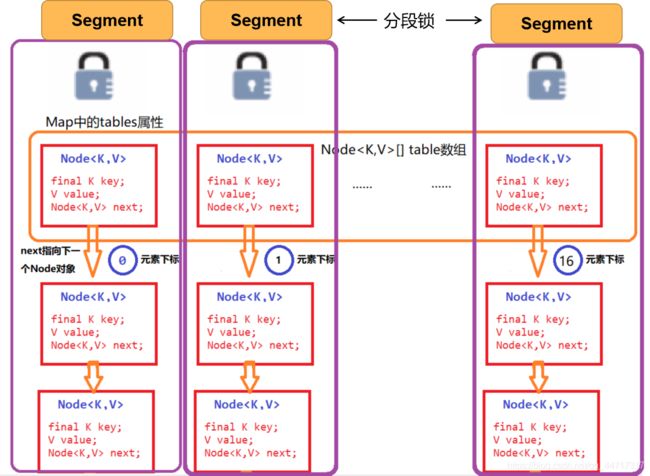
HashTable性能差主要是由于所有操作需要竞争同一把锁,而如果容器中有多把锁,每一把锁锁一段数据,这样在多线程访问时不同段的数据时,互不影响,就不会导致阻塞状态了,这样便可以有效地提高并发效率。这就是ConcurrentHashMap所采用的"分段锁"思想。
ConcurrentHashMap
- 初始容量默认为16段(
Segment),使用分段锁思想设计; - 不像
HashMap对整体加锁,而是分别为每个Segment加锁; - 当多个对象存入同一个
Segment时,才需要互斥; - 最理想的状态为16个对象分别存入16个
Segment,并行数量为16 - 使用方法与
HashMap一样
ConcurrentHashMap源码分析
待更…