数据不撒谎,Flink-Kafka性能压测全记录!
本文作者来自本号的粉丝:林夕_Yume,作者微信:wxid_nvd5wwng4v2i22
欢迎大家关注他的简书:https://www.jianshu.com/u/3fa2b243f30d
大家有同样需求的同学赶紧加他好友探讨~
1.压测方案
1.1 压测目的
本次性能测试在正式环境下单台服务器上Kafka处理MQ消息能力进行压力测试。测试包括对Kafka写入MQ消息和消费MQ消息进行压力测试,根据不同量级的消息处理结果,评估Kafka的处理性能是否满足项目需求(该项目期望Kafka能够处理上亿级别的MQ消息)。
1.2 测试范围及方法
1.2.1 测试范围概述
测试使用Kafka自带的测试脚本,通过命令对Kafka发起写入MQ消息和Kafka消费MQ消息的请求。模拟不同数量级的消息队列的消息写入和消费场景,根据Kafka的处理结果,评估Kafka是否满足处理亿级以上的消息的能力。
1.2.2测试方法
测试目的:
验证单台服务器上Kafka写入消息和消费消息的能力,根据测试结果评估当前Kafka集群模式是否满足上亿级别的消息处理能力。
测试方法
在服务器上使用Kafka自带的测试脚本,模拟1y级别的消息写入以及读取请求,查看Kafka处理不同数量级的消息数时的处理能力,包括每秒生成消息数、吞吐量、消息延迟时间。
Kafka消息写入创建的topic命名为test_kafka_throughout,Kafka消费读取的topic也是该topic;使用命令发起消费该topic的请求,针对不同的测试指标,本次我们采用固定其他值,动态变化测量值的方式来进行,具体使用脚本为kafka自带的测试脚本,分别为kafka bin目录下的kafka-producer-perf-test.sh和kafka-consumer-perf-test.sh;通过测试来查看Kafka消费不同数量级别的消息时的处理能力。
准备工作
测试之前,我们需要先用linux命令去测试磁盘的读写速度,具体命令如下:
1.测试IO读
hdparm -t --direct /dev/sda3
IO读用上面的命令测试即可,不过 hdparm 这个工具需要自己安装,而且需要root用户去执行;
2.测试IO写
sync;/usr/bin/time -p bash -c "(dd if=/dev/zero of=test.dd bs=1M count=20000)"
测试结论:
1.dd测试出的读速度和hdparm 是存在区别的;
2.通过 bs 选项 设置不通的读写块大小测试(默认512字节,测试使用1M);
3.可以看出 dd 的测出的速度与读写块的大小有关系,还可能受到系统中有IO读写的进程的影响;
4.hdparm的测试原理可能是和dd的测试方法存在差别;
整体上看,IO的实际测试速度是受到很多因素影响的,包括读写的方式(随机还是顺序,hdparm和dd测试是都是采用顺序读写)、缓存机制、测试的取样等等。
所以不太可能得到一个确定的值(相同的命令行多次测试也不一样,不过差别要小些),以上的方法中读测试还是推荐使用hdparm。
以上的数据虽然存在偏差,但还是能大体分析出机器的IO性能。只是需要明确,这些测试值是在什么样的环境下获得的。
3.测试结果
1.磁盘cache读7471m/s;
2.disk读163m/s;
3.IO写125m/s;
4.IO读206m/s;
经过测试,我们拿到的磁盘读应该在163m/s-206m/s之间,而写速度是163m/s。后续评测我们以该磁盘测试为基准来核定。1.3 测试环境

2.kafka参数
在调试和优化使用Java开发的系统时,第一步绕不开对JVM的调优,Kafka也不例外,而JVM调优的重点则是在内存上。
其实Kafka服务本身并不需要很大内存,其依赖的是系统提供的PageCache来满足性能上的要求,本次测试时设置30G内存的目的是支持更高的并发,高并发本身就必然会需要更多的内存来支持,同时高并发也意味着SocketBuffer等相关缓存容量会成倍增长。实际使用中,调整内存大小的准则是留给系统尽可能多的空闲内存,Broker本身则是够用就好。
JVM上的垃圾回收器,官方文档里推荐使用最新的G1来代替CMS作为垃圾回收器。为了稳定性问题,本次我们使用jdk8以上的版本,我们本次使用G1回收器的原因如下:
G1是一种适用于服务器端的垃圾回收器,很好的平衡了吞吐量和响应能力;
对于内存的划分方法不同,Eden, Survivor, Old区域不再固定,使用内存会更高效。G1通过对内存进行Region的划分,有效避免了内存碎片问题;
G1可以指定GC时可用于暂停线程的时间(不保证严格遵守)。而CMS并不提供可控选项;
CMS只有在FullGC之后会重新合并压缩内存,而G1把回收和合并集合在一起;
CMS只能使用在Old区,在清理Young时一般是配合使用ParNew,而G1可以统一两类分区的回收算法。
其使用场景如下:
JVM占用内存较大(At least 4G);
应用本身频繁申请、释放内存,进而产生大量内存碎片时;
对于GC时间较为敏感的应用。
首先,我们设置JVM配置为:
2.1 Producer相关参数
我们在producer涉及到性能的关键因素可能会存在如下几个:
thread:我们测试时的单机线程数;
bath-size:我们所处理的数据批次大小;
ack:主从同步策略我们在生产消息时特别需要注意,是follower收到后返回还是只是leader收到后返回,这对于我们的吞吐量影响颇大;
message-size:单条消息的大小,要在producer和broker中设置一个阈值,且它的大小范围对吞吐量也有影响;
compression-codec:压缩方式,目前我们有不压缩,gzip,snappy,lz4四种方式;
partition:分区数,主要是和线程复合来测试;
replication:副本数;
througout:我们所需要的吞吐量,单位时间内处理消息的数量,可能对我们处理消息的延迟有影响;
linger.ms:两次发送时间间隔,满足后刷一次数据。
2.2 Consumer相关参数
thread:我们测试时的单机线程数;
fetch-size:抓取数据量;
partition:分区数,主要是和线程复合来测试;
replication:副本数;
througout:我们所需要的吞吐量,单位时间内处理消息的数量,可能对我们处理消息的延迟有影响;
2.3 Broker相关参数
num.replica.fetchers:副本抓取的相应参数,如果发生ISR频繁进出的情况或follower无法追上leader的情况则适当增加该值,==但通常不要超过CPU核数+1;==
num.io.threads:broker处理磁盘IO的线程数,主要进行磁盘io操作,高峰期可能有些io等待,因此配置需要大些。==建议配置线程数量为cpu核数2倍,最大不超过3倍;==
num.network.threads:broker处理消息的最大线程数,和我们生产消费的thread很类似主要处理网络io,读写缓冲区数据,基本没有io等待,==建议配置线程数量为cpu核数加1;==
log.flush.interval.messages:每当producer写入多少条消息时,刷数据到磁盘;
log.flush.interval.ms:每隔多长时间,刷数据到磁盘;
4.测试过程
4.1 producer测试
4.1.1 bath-size
测试脚本
./kafka-producer-perf-test.sh --topic test_kafka_perf1 --num-records 100000000 --record-size 687 --producer-props bootstrap.servers=10.240.1.134:9092,10.240.1.143:9092,10.240.1.146:9092 batch.size=10000 --throughput 30000
./kafka-producer-perf-test.sh --topic test_kafka_perf1 --num-records 100000000 --record-size 687 --producer-props bootstrap.servers=10.240.1.134:9092,10.240.1.143:9092,10.240.1.146:9092 batch.size=20000 --throughput 30000
./kafka-producer-perf-test.sh --topic test_kafka_perf1 --num-records 100000000 --record-size 687 --producer-props bootstrap.servers=10.240.1.134:9092,10.240.1.143:9092,10.240.1.146:9092 batch.size=40000 --throughput 30000
./kafka-producer-perf-test.sh --topic test_kafka_perf1 --num-records 100000000 --record-size 687 --producer-props bootstrap.servers=10.240.1.134:9092,10.240.1.143:9092,10.240.1.146:9092 batch.size=60000 --throughput 30000
./kafka-producer-perf-test.sh --topic test_kafka_perf1 --num-records 100000000 --record-size 687 --producer-props bootstrap.servers=10.240.1.134:9092,10.240.1.143:9092,10.240.1.146:9092 batch.size=80000 --throughput 30000测试结果
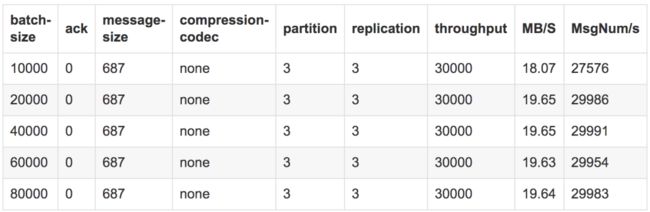
测试结论
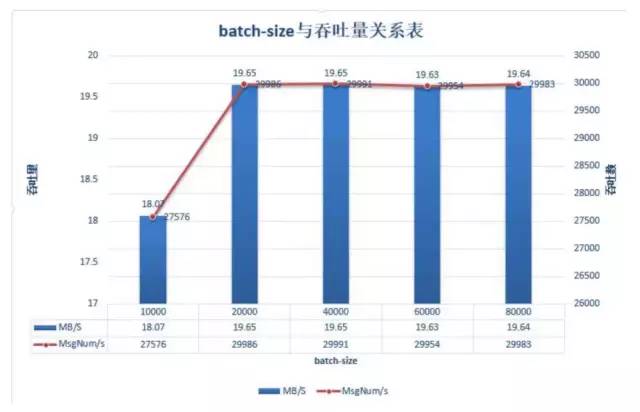
测试中通过我们增加batch-size的大小,我们可以发现在消息未压缩的前提下,20000条一批次之后吞吐稳定在30000条/s,而数据量在19.65M/s。
4.1.2 ack
测试脚本
./kafka-producer-perf-test.sh --topic test_kafka_perf1 --num-records 100000000 --record-size 4096 --producer-props bootstrap.servers=10.240.1.134:9092,10.240.1.143:9092,10.240.1.146:9092 batch.size=20000 acks=0 --throughput 30000
./kafka-producer-perf-test.sh --topic test_kafka_perf1 --num-records 100000000 --record-size 4096 --producer-props bootstrap.servers=10.240.1.134:9092,10.240.1.143:9092,10.240.1.146:9092 batch.size=20000 acks=1 --throughput 30000
./kafka-producer-perf-test.sh --topic test_kafka_perf1 --num-records 100000000 --record-size 4096 --producer-props bootstrap.servers=10.240.1.134:9092,10.240.1.143:9092,10.240.1.146:9092 batch.size=20000 acks=-1 --throughput 30000测试结果

测试结论
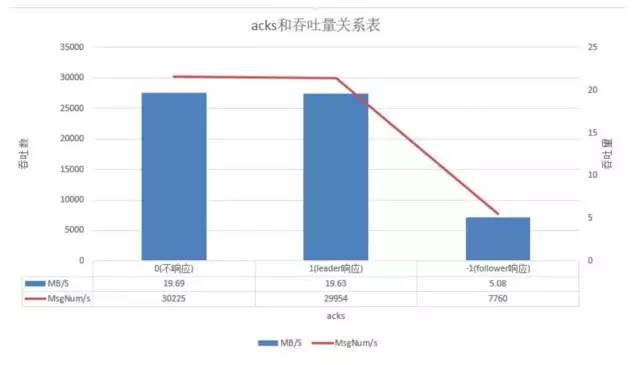
测试中通过我们使用不同的ack策略,我们可以发现在消息未压缩的前提下,不响应速度最快,其次是leader响应,而follower响应吞吐只有其25%左右,在主从同步策略上要根据数据量还有我们的数据稳定性结合来考量。
4.1.3 message-size
测试脚本
./kafka-producer-perf-test.sh --topic test_kafka_perf1 --num-records 100000000 --record-size 687 --producer-props bootstrap.servers=10.240.1.134:9092,10.240.1.143:9092,10.240.1.146:9092 batch.size=20000 acks=-1 --throughput 30000
./kafka-producer-perf-test.sh --topic test_kafka_perf1 --num-records 100000000 --record-size 454 --producer-props bootstrap.servers=10.240.1.134:9092,10.240.1.143:9092,10.240.1.146:9092 batch.size=20000 acks=-1 --throughput 30000测试结果

测试结论
 测试中通过我们使用两种不同的消息大小,发现在消息未压缩的前提下且其他参数一致的情况下,687字节的吞吐量是要优于454字节的,目前我们的两种消息为此大小,测试中发现当消息大小为4k时效果最优,这点可以在后续实践中再去证实
测试中通过我们使用两种不同的消息大小,发现在消息未压缩的前提下且其他参数一致的情况下,687字节的吞吐量是要优于454字节的,目前我们的两种消息为此大小,测试中发现当消息大小为4k时效果最优,这点可以在后续实践中再去证实
4.1.4 compression-codec
测试脚本
./kafka-producer-perf-test.sh --topic test_kafka_perf1 --num-records 100000000 --record-size 687 --producer-props bootstrap.servers=10.240.1.134:9092,10.240.1.143:9092,10.240.1.146:9092 batch.size=20000 acks=1 compression.type=none --throughput 30000
./kafka-producer-perf-test.sh --topic test_kafka_perf1 --num-records 100000000 --record-size 687 --producer-props bootstrap.servers=10.240.1.134:9092,10.240.1.143:9092,10.240.1.146:9092 batch.size=20000 acks=1 compression.type=gzip --throughput 30000
./kafka-producer-perf-test.sh --topic test_kafka_perf1 --num-records 100000000 --record-size 687 --producer-props bootstrap.servers=10.240.1.134:9092,10.240.1.143:9092,10.240.1.146:9092 batch.size=20000 acks=1 compression.type=snappy --throughput 30000
./kafka-producer-perf-test.sh --topic test_kafka_perf1 --num-records 100000000 --record-size 687 --producer-props bootstrap.servers=10.240.1.134:9092,10.240.1.143:9092,10.240.1.146:9092 batch.size=20000 acks=1 compression.type=lz4 --throughput 30000测试结果1

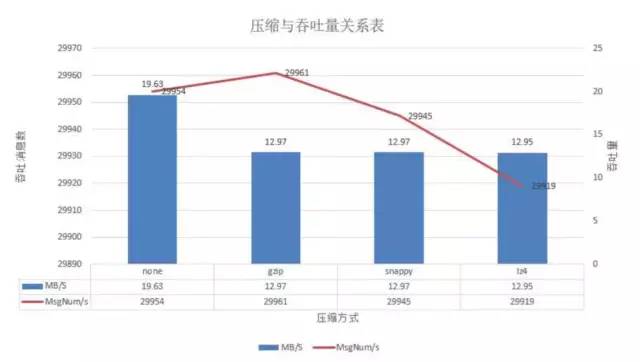
在batch-size为2w且并发量在3w时,可以看出来不压缩的吞吐量最好,其他的基本相差不大。
测试结果2

我们在后续测试中发现,在batch-size为100w且并发量在10w时,可以看出来snappy和lz4的吞吐量上升幅度明显,而gzip由于压缩的费时其吞吐最差,不压缩的在本测试中的吞吐次之。
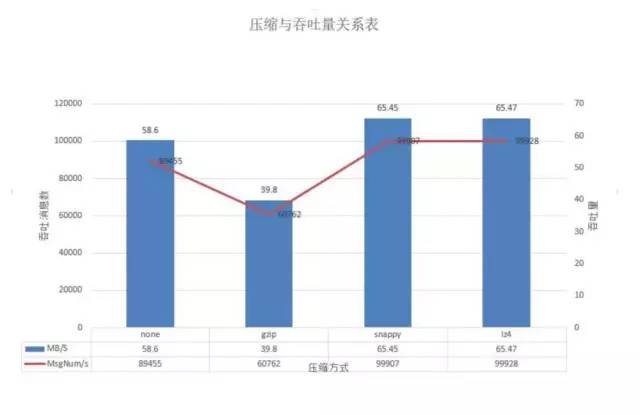
测试结果3

我们在后续测试中发现,在batch-size为100w且并发量在20w时,lz4的吞吐量优势明显达到19w/s,snappy次之为12.8w/s,而gzip由于压缩的费时其吞吐最差基本在5.8w/s,不压缩的在本测试中的吞吐也能达到11w/s。
测试结果4

在batch-size为100w且并发量在50w时,lz4的吞吐量优势明显达到31.3w/s,snappy次之为16.1w/s,而gzip由于压缩的费时其吞吐最差基本在5.3w/s,不压缩的在本测试中的吞吐也能达到9.3w/s。
测试结果5

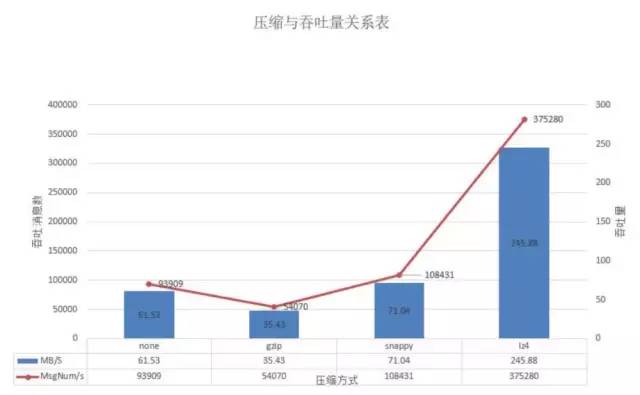
在batch-size为100w且并发量在60w时,lz4的吞吐达到37.5w/s,snappy此时下降到10.8w/s,而gzip由于压缩的费时其吞吐最差基本在5.4w/s,不压缩的在本测试中的吞吐为9.4w/s。
测试结果6

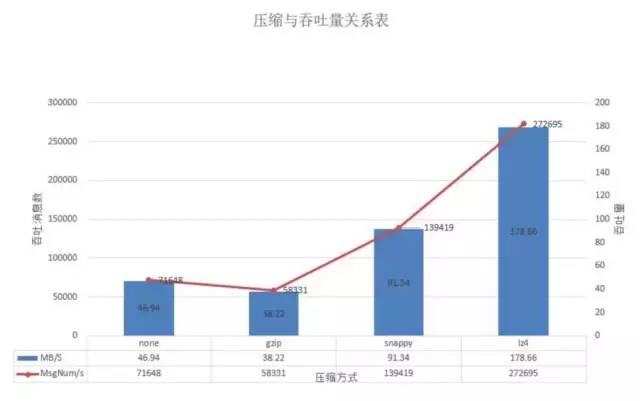
在batch-size为100w且并发量在70w时,lz4的吞吐量下降到达到27.2w/s,snappy次之为13.9w/s,而gzip则继续保持在5.8w/s,不压缩则下降到7.1w/s。
测试结果7
测试单副本单分区下的各压缩的吞吐量:
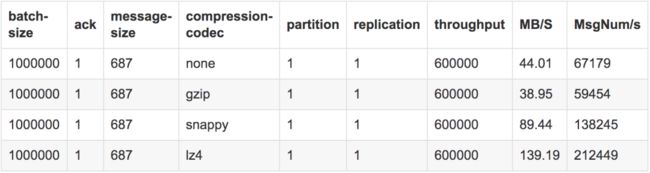

我们这次使用1个分区1个副本的主题,测试中通过我们使用不同的压缩格式,在其他参数一致的情况下,在并发和batch-size增大到60w和100w的情况下,lz4达到最好的吞吐21.2w/s,而普通不压缩的方式则维持在6.7w/s。
测试结论
本次测试对数据的存储块大小未测,但在之前的测试中发现压缩以及解压的情况也是lz4算法最优,==lz4压缩最大时可以达到30w+/s的吞吐,而不压缩为12w/s,snappy最大为16w/s,gzip最大为5.8w/s==;故后续生产消息时建议采用lz4压缩,不仅可以节省磁盘,也可以大幅度增加我们的吞吐。
4.1.5 partition
测试脚本
1、创建topic
/bin/kafka-topics.sh --create --zookeeper 110.240.0.9:2181,10.240.0.10:2181,10.240.0.13:2181/kafka --topic test_kafka_perf11 --partitions 1 --replication-factor 1
/bin/kafka-topics.sh --create --zookeeper 110.240.0.9:2181,10.240.0.10:2181,10.240.0.13:2181/kafka --topic test_kafka_perf8 --partitions 2 --replication-factor 1
/bin/kafka-topics.sh --create --zookeeper 110.240.0.9:2181,10.240.0.10:2181,10.240.0.13:2181/kafka --topic test_kafka_perf16 --partitions 3 --replication-factor 1
/bin/kafka-topics.sh --create --zookeeper 110.240.0.9:2181,10.240.0.10:2181,10.240.0.13:2181/kafka1 --topic test_kafka_perf24 --partitions 4 --replication-factor 1
/bin/kafka-topics.sh --create --zookeeper 110.240.0.9:2181,10.240.0.10:2181,10.240.0.13:2181/kafka --topic test_kafka_perf32 --partitions 5 --replication-factor 1
2、生产数据
/bin/kafka-producer-perf-test.sh --topic test_kafka_perf1 --num-records 100000000 --record-size 10240 --producer-props bootstrap.servers=10.240.1.134:9092,10.240.1.143:9092,10.240.1.146:9092 batch.size=80000 acks=1 compression.type=lz4 --throughput 29000
3、初步结论
分区数越多,单线程消费者吞吐率越小。随着更多的broker线程和磁盘开始扫描不同的分区,吞吐量开始显著增加。但是,一旦使用了所有broker线程和磁盘,添加额外的分区没有任何效果。
测试结果
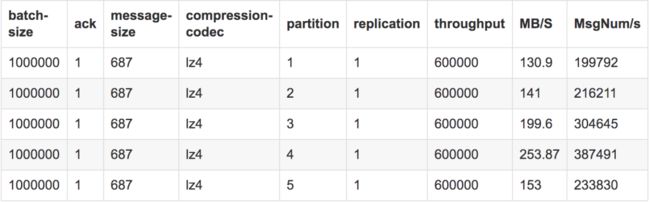
测试结论

在我们的broker线程小于partiton数时,随着线程增多,吞吐上升,而在两者对等时,达到最优,后续基本稳定,但是由于网络和磁盘的问题可能会有一些起伏。
4.1.6 replication
测试脚本
1、创建topic
/bin/kafka-topics.sh--create --zookeeper 110.240.0.9:2181,10.240.0.10:2181,10.240.0.13:2181/kafka --topic test_kafka_rep2 --partitions 1 --replication-factor 1
/bin/kafka-topics.sh--create --zookeeper 110.240.0.9:2181,10.240.0.10:2181,10.240.0.13:2181/kafka --topic test_kafka_rep3 --partitions 1 --replication-factor 2
/bin/kafka-topics.sh--create --zookeeper 110.240.0.9:2181,10.240.0.10:2181,10.240.0.13:2181/kafka --topic test_kafka_rep24 --partitions 1 --replication-factor 3
2、生成数据
/bin/kafka-producer-perf-test.sh --topic test_kafka_perf1 --num-records 100000000 --record-size 687 --producer-props bootstrap.servers=10.240.1.134:9092,10.240.1.143:9092,10.240.1.146:9092 batch.size=1000000 acks=1 compression.type=lz4 --throughput 500000
3、初步结论
备份数越多,吞吐率越低。
测试结果

测试结论

Replication是我们对不同partition所做的副本,它的大小会在ISR中显示,为了保证数据的安全性,ISR中掉出的版本应该保持在1,所以此处我们从replica为2开始测试。在ack不同时,其数量的多少会对性能造成线性的影响,数量过少会影响数据的可用性,太多则会白白浪费存储资源,一般建议在2~4为宜,我们设置为3个,既能保障数据的高可用,又避免了浪费过多的存储资源。
4.1.7 throughout/IO
测试脚本:
/bin/kafka-producer-perf-test.sh --topic test_kafka_perf1 --num-records 100000000 --record-size 10240 --producer-props bootstrap.servers=10.240.1.134:9092,10.240.1.143:9092,10.240.1.146:9092 batch.size=1000000 acks=1 compression.type=lz4 --throughput 10000
/bin/kafka-producer-perf-test.sh --topic test_kafka_perf1 --num-records 100000000 --record-size 10240 --producer-props bootstrap.servers=10.240.1.134:9092,10.240.1.143:9092,10.240.1.146:9092 batch.size=1000000 acks=1 compression.type=lz4 --throughput 30000
/bin/kafka-producer-perf-test.sh --topic test_kafka_perf1 --num-records 100000000 --record-size 10240 --producer-props bootstrap.servers=10.240.1.134:9092,10.240.1.143:9092,10.240.1.146:9092 batch.size=1000000 acks=1 compression.type=lz4 --throughput 50000
/bin/kafka-producer-perf-test.sh --topic test_kafka_perf1 --num-records 100000000 --record-size 10240 --producer-props bootstrap.servers=10.240.1.134:9092,10.240.1.143:9092,10.240.1.146:9092 batch.size=1000000 acks=1 compression.type=lz4 --throughput 70000
/bin/kafka-producer-perf-test.sh --topic test_kafka_perf1 --num-records 100000000 --record-size 10240 --producer-props bootstrap.servers=10.240.1.134:9092,10.240.1.143:9092,10.240.1.146:9092 batch.size=1000000 acks=1 compression.type=lz4 --throughput 100000
测试结果

测试结论
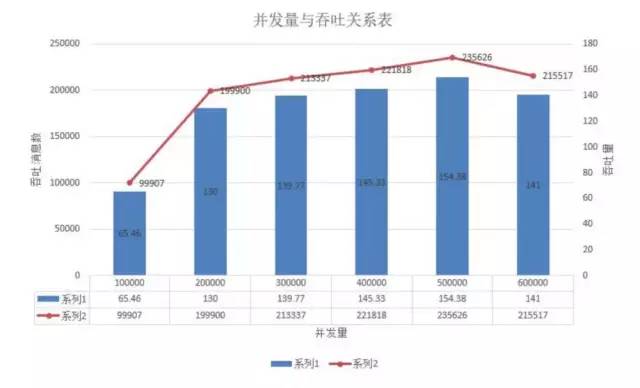
在主题是一个分区和一个副本时,我们看到在并发50w以下时,随着并发数增大,吞吐上升,但是在50w以后时,可以看出并发增大反而吞吐降低了,这是因为IO的限制,在高并发的情况下,产生了阻塞而导致。
4.2 consumer测试
4.2.1 thread
测试脚本
./kafka-consumer-perf-test.sh --zookeeper 110.240.0.9:2181,10.240.0.10:2181,10.240.0.13:2181/kafka --topic test_kafka_perf1 --fetch-size 1048576 --messages 100000 --threads 1 --hide-header --num-fetch-threads 1
./kafka-consumer-perf-test.sh --zookeeper 110.240.0.9:2181,10.240.0.10:2181,10.240.0.13:2181/kafka --topic test_kafka_perf1 --fetch-size 1048576 --messages 100000 --threads 4 --hide-header --num-fetch-threads 1
./kafka-consumer-perf-test.sh --zookeeper 110.240.0.9:2181,10.240.0.10:2181,10.240.0.13:2181/kafka --topic test_kafka_perf1 --fetch-size 1048576 --messages 100000 --threads 7 --hide-header --num-fetch-threads 1
./kafka-consumer-perf-test.sh --zookeeper 110.240.0.9:2181,10.240.0.10:2181,10.240.0.13:2181/kafka --topic test_kafka_perf1 --fetch-size 1048576 --messages 100000 --threads 10 --hide-header --num-fetch-threads 1测试结果

测试结论

在threads为4时,消费速度最好达到24.1w/s,而后续慢慢平稳。
4.2.2 fetch-size
测试脚本
./bin/kafka-consumer-perf-test.sh --zookeeper 110.240.0.9:2181,10.240.0.10:2181,10.240.0.13:2181/kafka --topic s1 --messages 1000000 --fetch-size 1000 --threads 3 --hide-header
./bin/kafka-consumer-perf-test.sh --zookeeper 110.240.0.9:2181,10.240.0.10:2181,10.240.0.13:2181/kafka--topic s1 --messages 1000000 --fetch-size 2000 --threads 3 --hide-header
./bin/kafka-consumer-perf-test.sh --zookeeper 110.240.0.9:2181,10.240.0.10:2181,10.240.0.13:2181/kafka --topic s1 --messages 1000000 --fetch-size 5000 --threads 3 --hide-header
./bin/kafka-consumer-perf-test.sh --zookeeper 110.240.0.9:2181,10.240.0.10:2181,10.240.0.13:2181/kafka --topic s1 --messages 1000000 --fetch-size 10000 --threads 3 --hide-header
./bin/kafka-consumer-perf-test.sh --zookeeper 110.240.0.9:2181,10.240.0.10:2181,10.240.0.13:2181/kafka --topic s1 --messages 1000000 --fetch-size 15000 --threads 3 --hide-header
./bin/kafka-consumer-perf-test.sh --zookeeper 110.240.0.9:2181,10.240.0.10:2181,10.240.0.13:2181/kafka --topic s1 --messages 1000000 --fetch-size 20000 --threads 3 --hide-header测试结果

测试结论

4.2.3 partition
测试脚本
1、创建topic
/bin/kafka-topics.sh --create --zookeeper 110.240.0.9:2181,10.240.0.10:2181,10.240.0.13:2181/kafka --topic test_kafka_part3 --partitions 3 --replication-factor 1
/bin/kafka-topics.sh --create --zookeeper 110.240.0.9:2181,10.240.0.10:2181,10.240.0.13:2181/kafka --topic test_kafka_part5 --partitions 5 --replication-factor 1
/bin/kafka-topics.sh --create --zookeeper 110.240.0.9:2181,10.240.0.10:2181,10.240.0.13:2181/kafka --topic test_kafka_part7 --partitions 7 --replication-factor 1
/bin/kafka-topics.sh --create --zookeeper 110.240.0.9:2181,10.240.0.10:2181,10.240.0.13:2181/kafka --topic test_kafka_part7 --partitions 9 --replication-factor 1
2、生成数据
/bin/kafka-producer-perf-test.sh --topic test_kafka_perf1 --num-records 10000000 --record-size 687 --producer-props bootstrap.servers=10.240.1.134:9092,10.240.1.143:9092,10.240.1.146:9092 batch.size=1000000 acks=1 compression.type=lz4 --throughput 500000
3、消费数据
./kafka-consumer-perf-test.sh --broker-list localhost:9092 --zookeeper 110.240.0.9:2181,10.240.0.10:2181,10.240.0.13:2181/kafka --topic test_kafka_part --messages 10000000 --fetch-size 10240 --threads 5 --hide-header --num-fetch-threads 1
4、初步结论
分区数越多,单线程消费者吞吐率越小。随着更多的broker线程和磁盘开始扫描不同的分区,吞吐量开始显著增加。但是,一旦使用了所有broker线程和磁盘,添加额外的分区没有任何效果。测试结果
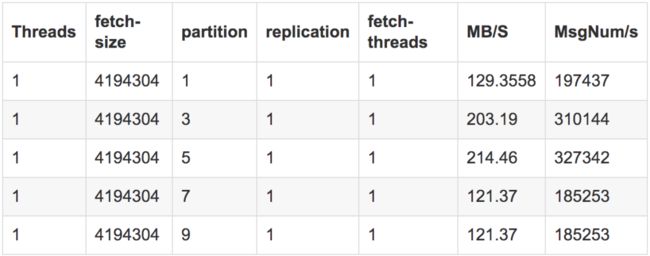
测试结论

分区数在kafka中和处理的线程数有一定的关系,当thread小于partition数时,那么可能存在一个thread消费两个partition,而==两者一样或者说thread大于partition时,实际是一一对应关系==。
4.2.4 replication
测试脚本
1、创建topic
/bin/kafka-topics.sh--create --zookeeper 10.240.0.9:2181,10.240.0.10:2181,10.240.0.13:2181/kafka --topic test_kafka_rep2 --partitions 5 --replication-factor 2
/bin/kafka-topics.sh--create --zookeeper 10.240.0.9:2181,10.240.0.10:2181,10.240.0.13:2181/kafka --topic test_kafka_rep3 --partitions 5 --replication-factor 3
/bin/kafka-topics.sh--create --zookeeper 10.240.0.9:2181,10.240.0.10:2181,10.240.0.13:2181/kafka --topic test_kafka_rep4 --partitions 5 --replication-factor 4
/bin/kafka-topics.sh--create --zookeeper 10.240.0.9:2181,10.240.0.10:2181,10.240.0.13:2181/kafka --topic test_kafka_rep5 --partitions 5 --replication-factor 5
2、生成数据
/bin/kafka-producer-perf-test.sh --zookeeper 10.240.0.9:2181,10.240.0.10:2181,10.240.0.13:2181/kafka --topics test_kafka_rep --messages 10000000 --message-size 4096 --batch-size 10000 --threads 1 --compression-codec 3 --hide-header
3、消费数据
./bin/kafka-consumer-perf-test.sh --zookeeper 10.240.0.9:2181,10.240.0.10:2181,10.240.0.13:2181/kafka --topic test_kafka_rep --messages 10000000 --fetch-size 1048576 --threads 5
--num-fetch-threads 1
4、初步结论
备份数越多,吞吐率越低。测试结果
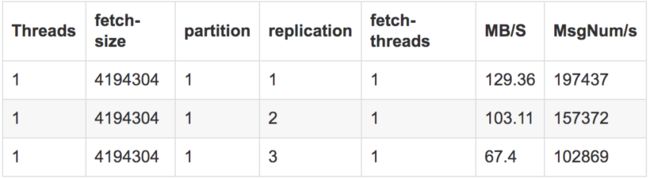
测试结论

数量过少会影响数据的可用性,太多则会白白浪费存储资源,一般建议在2~4为宜,我们设置为3个,既能保障数据的高可用,又避免了浪费过多的存储资源。
4.2.5 fetch-threads
测试脚本:
./kafka-consumer-perf-test.sh --zookeeper 10.240.0.9:2181,10.240.0.10:2181,10.240.0.13:2181/kafka --topic test_perf --fetch-size 1048576 --messages 1000000 --threads 5 --num-fetch-threads 1
./kafka-consumer-perf-test.sh --zookeeper 10.240.0.9:2181,10.240.0.10:2181,10.240.0.13:2181/kafka --topic test_perf --fetch-size 1048576 --messages 10000000 --threads 5 --num-fetch-threads 3
./kafka-consumer-perf-test.sh --zookeeper 10.240.0.9:2181,10.240.0.10:2181,10.240.0.13:2181/kafka --topic test_perf --fetch-size 1048576 --messages 50000000 --threads 5 --num-fetch-threads 5
./kafka-consumer-perf-test.sh --zookeeper 10.240.0.9:2181,10.240.0.10:2181,10.240.0.13:2181/kafka --topic test_perf --fetch-size 1048576 --messages 100000000 --threads 5 --num-fetch-threads 7
./kafka-consumer-perf-test.sh --zookeeper 10.240.0.9:2181,10.240.0.10:2181,10.240.0.13:2181/kafka --topic test_perf --fetch-size 1048576 --messages 100000000 --threads 5 --num-fetch-threads 10测试结果
Threads|fetch-size|partition|replication|fetch-threads|MB/S|MsgNum/s--|--|--|--|--|--|--|--1|4194304| 1 | 1 | 1 | 117.86 | 1798811|4194304| 1 | 1 | 3 | 137.56 | 2099731|4194304| 1 | 1 | 6 | 127.63| 1948101|4194304| 1 | 1 | 7 | 126.73 | 1934341|4194304| 1 | 1 | 10 | 146.40 | 223458
测试结论

在我们控制其他条件不变的情况下,我们更改fetch-thread的线程数,可以发现是随着线程数增多而消费速度加快,在fetch-threads=10时,最优为146.4m/s。
4.3 broker测试
涉及的参数众多,诸如以下:
default.replication.factor
num.replica.fetchers
auto.create.topics.enable
min.insync.replicas
unclean.leader.election.enable
broker.rack
log.flush.interval.messages
log.flush.interval.ms
unclean.leader.election.enable
min.insync.replicas
num.recovery.threads.per.data.dir
参数中很多都是我们调优方面需要的参数,对吞吐影响小的参数我们本次不进行测试,而产生影响的partition,replic以及IO的部分我们在producer和consumer中已得出结论,此处只进行和broker相关的系列参数的测试。影响参数具体如下:
其中涉及到调优延时的num.replica.fetchers,如果发生ISR频繁进出的情况或follower无法追上leader的情况则适当增加该值,但通常不要超过CPU核数+1,在reblance中会对我们的吞吐产生间接影响;
涉及持久性的诸如:default.replication.factor我们已测,auto.create.topics.enable=false此处我们不允许自动创建主题,min.insync.replicas建议设置为replication factor-1 这块我们需要保证ISR中的版本不掉,unclean.leader.election.enable= false 是否允许不具备ISR资格的replicas选举为leader,这个为了数据准确性设置为false,broker.rack如果有机架信息,则最好设置上,保证数据在多个rack间的分布性以达到高持久化,log.flush.interval.messages和log.flush.interval.ms如果是特别重要的topic并且TPS本身也不高,则推荐设置成比较低的值,比如1,此处刷盘对我们数据的持久化是有影响的,后续进行测试;
涉及到高可用的如下:min.insync.replicas=1最少ISR中需要保留的broker数,num.recovery.threads.per.data.dirlog.dirs中配置的目录数,此三者在配置中我们来设置;
4.3.1 num.replica.fetchers
测试方法:
首先我们的参数是在broker的配置文件中设置,该参数设置的依据是如果发生ISR频繁进出的情况或follower无法追上leader的情况则适当增加该值,但通常不要超过CPU核数+1,所以我们从1开始测试到Num(core)+1;
测试结果:
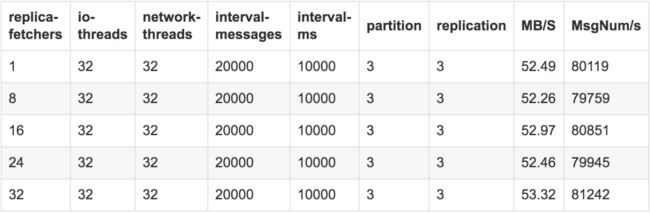
测试结论:
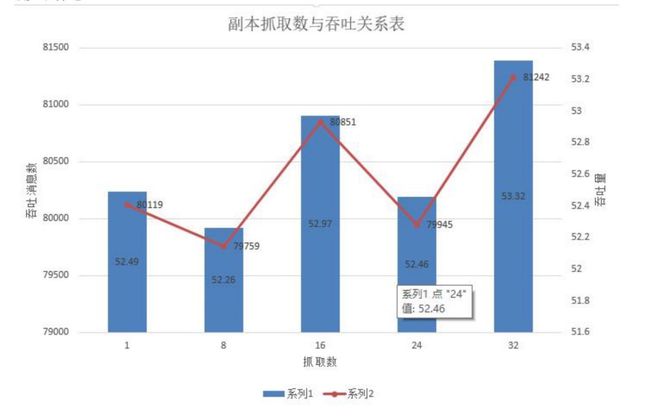
测试fetchers对吞吐的影响时,可以发现产生波动但是整体变化不大,因此我们还是选取在32时最优。
4.3.2 num.io.threads
测试方法:
该参数也在broker的配置文件中来配,主要进行磁盘io操作,高峰期可能有些io等待,因此配置需要大些。配置线程数量建议为cpu核数2倍,最大不超过3倍,我们从core的整数倍测到3倍;
测试结果:

测试结论:
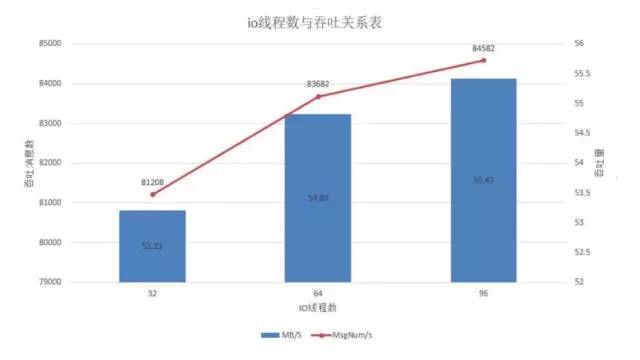
io-thread对吞吐的影响是随着线程数增多而逐步上升的,但不宜超过整体核数的3倍,因此我们还是选取在96时最优。
4.3.3 num.network.threads
测试方法:
该参数也在broker的配置文件中来配,主要处理网络io,读写缓冲区数据,基本没有io等待,配置线程数量从1开始,测到核数+1;
测试结果:

测试结论:

net-thread对吞吐的影响是随着线程数增多而逐步上升的,但不宜超过整体核数,因此我们还是选取在32时最优。
4.3.4 interval.messages
测试脚本:
该参数也在broker的配置文件中来配,为大幅提高producer写入吞吐量,需要定期批量写文件,此配置为满足多大进行flush;
测试结果:

测试结论:

该项参数在测试中发现对吞吐的影响不是很大,通过测试,我们可以发现在messages数为2w时,性能较好。
4.3.5 interval.ms
测试脚本:
该参数也在broker的配置文件中来配,为大幅提高producer写入吞吐量,需要定期批量写文件,此配置为满足多长时间进行flush;
测试结果:
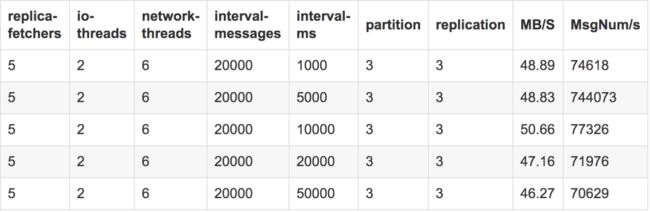
测试结论:

该项参数在测试中发现对吞吐的影响不是特别巨大,通过测试,由于刷盘还会以消息数为依据,因而此处我们设置为1w ms每次刷盘一次。
5. 容灾测试
5.1 broker宕机
5.1.1 broker集群宕机
这个做过测试后,发现具体情况如下:
即使设置了acks=all,但是如果整个集群都连接不上了,也是不能避免消息丢失的(重发次数到了设定的值,或者发送请求超时了都会导致生产者丢弃该条消息,发送下一条消息)。重试次数增多、发送请求超时这个参数设置长点可以减少“丢失”(丢失只是相对于消费者角度来说的,实际上是生产者由于超时或者重发次数限制丢弃了一些消息)的消息数。重试次数增多,发送请求超时增加都意味着对发送失败的消息进行更长时间的重发。因此相对来说,被生产者丢弃的消息数会少些。
5.1.2 部分broker宕机
集群有n份replication,那么一般来说,挂掉n-1 个节点都是没关系的。挂掉的broker对原来的消息收发几乎不产生任何影响。
5.1.2.1 对consumer的影响
broker挂掉之后,分区自然也要重新平衡,这时候会对消费产生什么影响,具体实验如下。
实验过程:
生产者发送n条信息;
生产者发送完毕后马上kill一个broker;
观察消费者状态(应该是阻塞了)。此处消费者每次消费完一条记录休眠2秒,方便我们有时间KILL BROKER。此外设置poll为1毫秒,方便执行休眠;
重启broker并观察消费者是否继续消费,消费的条数和正确性怎样;
消息条数为10:
发送前状况:所有leader负载均衡,ISR集合包含2个server,没有处在同步中的分区。
发送后,KILL掉broker后状态:分区进行重新平衡,leader重新选举为0,ISR集合只有一个SERVER,所有分区处于under replicated状态。
看剩下的BROKER上也可以看到消费者的重新组织。
结论:此时consumer仍然成功消费到所有消息,无重复,无丢失。不同发送量:

5.1.2.2 对producer的影响
生产者发送过程中(消费者保持正常消费),kill broker之后生产者可能会有如下的警告,但是因为设置了重发,重新发送后会发送到那个正常的broker上(retries可以设置)。观察消费者端的消费情况可以发现消费者稍微消费了几条数据后,稍微被阻塞了一会,但是很快又能回复消费正确拿到所有数据。
5.1.2.3 对分区leader和ISR的影响
在正常运行时,所有leader都是平衡的,而且ISR集合也是包含所有SERVER,所有分区都不处于under replicated状态。
当其中一个broker被kill后,其变化如下(PS:此时处于under replicated状态,这个在kafka manager上可以看),此时已经很快的选举好了新leader,然后尝试重启server,重启后可以发现ISR集合很快同步完成(此时在kafka manager上的Under Replicated状态又变为false),但是leader还没有平衡。leader的平衡有参数leader.imbalance.check.interval.seconds来控制,默认为300秒,因此需要等待5分钟才会leader重新平衡。
5分钟后查看,一切恢复如初。
5.2 磁盘故障
磁盘故障情况:当某个broker上的磁盘发生故障时,分区leader在该broker上的分区都无法进行访问,broker server进程被阻塞。如果磁盘上的数据能及时恢复,并且磁盘重新进行工作的话,出现磁盘故障的broker就能够重新恢复服务。而在磁盘故障没修复之前,其实整个kafka集群是不可用的。因此对可用性要求比较高的场景下,如果某个broker由于磁盘故障而不能服务,可以考虑尽快下线该broker,触发分区复制,确保整个集群可用。
磁盘故障恢复方法:首先第一件事还是下线出问题的broker,确保整个集群可用。然后尽快修复磁盘上的数据,然后重启broker。如果磁盘上的数据没法恢复,也没有关系。可以尽快替换健康的磁盘,然后重启broker,这样数据还是可以通过复制恢复过来的。
5.3 恢复能力
这个测试主要测试kafka进行数据恢复的能力。当kafka集群上有大量历史数据时,如果其中一个broker挂了,需要多少时间来完成恢复,同时对生产和消费会产生神马影响,是我们主要关心的内容。由于我们采用3个节点,并且admin.benchmark这个topic只有2份副本,也就是意味着只能容忍1个broker故障。如果超过1个broker故障,就会影响消息收发,需要尽快恢复broker。
实验过程:
按照第5节的方法进行大量消息的收发(先在上面保留2亿条记录,然后按照原来3个生产者9个消费者的方式启动整个收发流程)
在收发过程中下线broker1,观察对消息收发的影响(延迟变化、是否发生错误或者异常)
过几小时后重新启动broker1,查看恢复的时长和对生产消费的影响。
再次关掉broker1并且清除broker1上面所有的日志记录,查看集群需要多久时间恢复约10亿条记录。
PS:我们下线broker1的时间为14:48分,这个对照图来分析的时候请留意。
实验结果:
下线broker1之后,消费者没有报错,生产者开始刷出大量报错,约1分钟之后,所有生产者均开始重新恢复发送。在下线broker1之后,该broker上面的leader分区无法访问。这时候需要重新选取分区,然后到新的broker上去获取分区数据。而且还要触发复制。整个异常过程中,只有kafka集群的生产者会受影响,并且在较短的时间内自动恢复。
下线broker1之后,broker1的网卡仍然占用着比较大的网络带宽,主要是复制分区数据导致。
下线broker1之后,生产者的发送吞吐量降低、平均延迟增加、峰值时的延迟也增加。
下线broker1之后的10分钟的时间内,消费者的消费速率会有显著下降,应该是要等待分区选举leader吧。不过总体上,消费者受影响仍然较小,总体上仍然是以比较正常的速率进行消费(平均有3W+条消息每秒的消费速率)。下图是broker2的一个消费者的消费统计信息,可供参考。
broker1下线后整个集群仍然正常提供服务。过几小时后重新恢复broker1,由于其节点上原来的数据仍然是保留的,所以整个集群马上可以恢复。
broker1如果下线后删除上面10亿条记录再上线,发现数据恢复需要耗时较久。
5.4 恢复能力
kafka作为分布式的消息系统,在集群可用性上还是做得比较完善的。在副本数充足的情况下发生节点故障,只会对生产和消费的速率产生一些影响,总体系统仍然是可用的。
而针对突发的大量消息收发,kafka集群能非常稳定的工作。从实验结果我们也可以看到,即使使用万兆网卡,我们的生产和消费都快要跑满整块网卡的带宽。一般来说,只要网络带宽给力,kafka的吞吐性能绝对是够用了(前提是生产及发送者本身不是性能瓶颈)。
目前我们遇到的问题故障恢复问题还有就是在reblance过程中,特别是虚拟机在物理机上会不定时的产生leader和follower的切换,这在我们生产消费时其实是会存在数据的抖动,此时设置好重试次数以及exactly-once策略很重要。
6. 单台机器测试
前置条件,一台机器,主题也是单分区单副本。
6.1 ack=1&&compression=lz4
在这种情况下,kafka使用虚拟内存为65.90g,而实际占用内存2.7g,cpu使用率最高能达到305%,内存占用率达到4.9%;
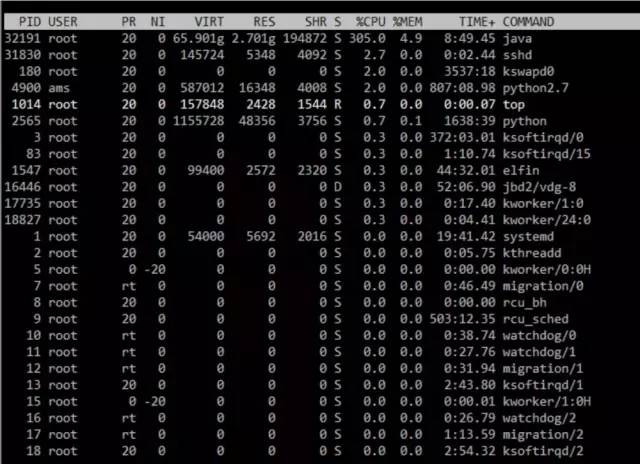
从进程来看,cpu占用率在304%,内存使用率则在5.2%;

从吞吐来看,达到了233409条/s,167.34m/s;

IO方面,我们的写入量峰值在19.82w/s,数据量达到4495wkB/s;

6.2 ack=0&&compression=lz4
在这种情况下,kafka使用虚拟内存为65.91g,而实际占用内存3.0g,cpu使用率最高能达到323.9%,内存占用率达到5.5%;

从进程来看,cpu占用率在259%,内存使用率则在5.4%;

从吞吐来看,达到了350988 r/s,229.96m/s;

IO方面,我们的写入量峰值在19.82w/s,数据量达到4495wkB/s;

6.3 ack=0&&compression=none
在这种情况下,kafka使用虚拟内存为65.93g,而实际占用内存3.1g,cpu使用率最高能达到204.7%,内存占用率达到5.7%;

从进程来看,cpu占用率在253%,内存使用率则在5.6%;

从吞吐来看,达到了72673条/s,47.61m/s;

IO方面,我们的写入量峰值在19.82w/s,数据量达到4495wkB/s;

6.4 ack=1&&compression=none
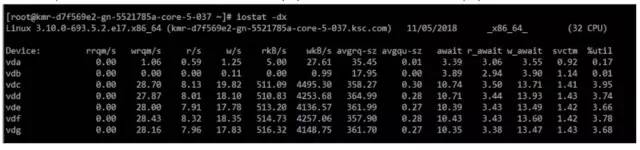
在这种情况下,kafka使用虚拟内存为66.42g,而实际占用内存3.14g,cpu使用率最高能达到232.5%,内存占用率达到5.7%;
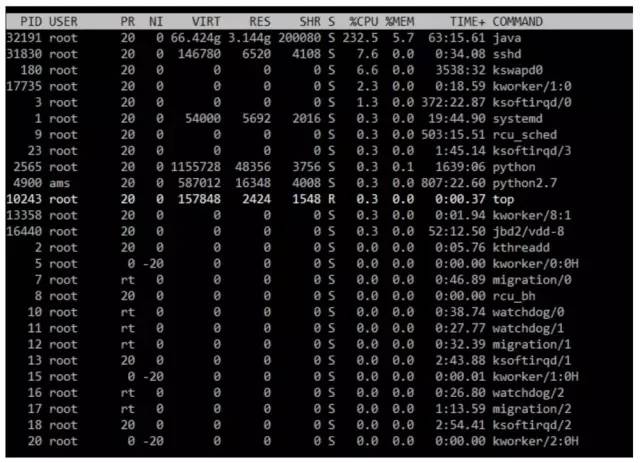
从进程来看,cpu占用率在181%,内存使用率则在5.7%;
![]()
从吞吐来看,达到了71676条/s,46.96m/s;

IO方面,我们的写入量峰值在19.82w/s,数据量达到4495wkB/s;
7.测试结论
通过目前对服务器磁盘,kafka集群broker,producer,consumer的吞吐及生产消费的性能测试:
producer方面,在主从同步选取1时性能和稳定性适中,压缩方面,我们选择lz4压缩方式,而批大小我们可以选择100w左右,并发保持在60,消息的大小建议在4k左右较好,分区数在3-5个,副本数为3个既可以保证性能也能维持高可用;
而consumer的处理线程我们选择4个,抓取消息大小则设置在400w条左右,抓取线程设置为10个即可;
broker的参数方面,replica.fetcher设置为服务器core的个数时较好,io.threads 则设置为core个数的3倍,network.threads保持和core个数相等即可,interval.messages数设置为2w,interval.ms则设置为10000 ms;
在5章的单机器测试中,我们lz4的最优的性能达到了350988 r/s,229.96m/s,是比之前134上测试的211779r/s,138.75m/s要告出一部分的,因为之前134和143云服务器实际是基于一台物理机,而149和146则是在一台机器上,可能因为之前3个分区3个副本的方式因为这点会有影响,所以可以看出来,独自的kafka服务器目前可以得到的最好吞吐量在35w/s左右,磁盘IO写在19.82w/s,CPU占用率最高在323%,内存使用率在6%左右。

