Java使用freemarker导出docx(WPS、OFFICE都可以看!)
继上篇导出一个完美的doc后,业务又发生了变化必须生成docx格式的word才行(哭泣)。
但是利用freemarker生成的word文档(doc/docx)利用notepad++打开是xml格式。而正常的文档格式利用notepad打开是乱码。很明显,就算你废了九牛二虎之力导出来的word OFFICE也绝对打开不了(WPS作为小可爱确可以打开= =)。
例如下图:
目前你生成的doc/docx底层还是xml格式的,转pdf或者在手机上看都只能看到xml文件。
MS-Office下的word在2007以后后缀基本是以.docx结尾,是用一种xml格式的在存储数据(.doc是用二进制存储数据),这就为使用freemarker提供的条件,如果把template.docx,重命名成template.zip,再用word一样是可以打开的,如果有WinRAR之类的压缩工具打开会发现如下目录结构
我们用office工具打开看到的内容其事就存放在在这个document.xml里面!,打开看看(document.xml默认是不换行的,我用Nodpad++打开,然后下载nodpad插件Xml-tool格式化后,具体安装可参考Nodepad
格式化xml)在这个xml就是以这种格式存储的数据,只需要将我们需要的内容变成一个变量,然后通过freemarker来解析这xml,让后用解析后的xml,把template.zip里面的document.xml替换掉,然后将这个template.zip解压成data.docx,那么这个data.docx,就包含了我们需要的数据
来源:https://blog.csdn.net/u013076044/article/details/79236000
上面这段话我翻看了近100篇博客才找到。。真的是受益匪浅
导入步骤如下:
- 处理模版对应的docx,和我上篇一样替换变量就好啦。(插入图片的话,见这篇博客https://blog.csdn.net/SOME___ONE/article/details/52562743)
- 将你的docx文件重命名x.zip,用压缩包工具打开它。将word/document.xml copy出来!
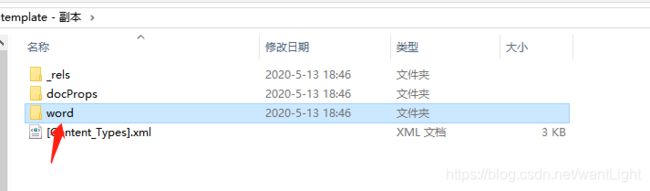
document.xml文件用于存放核心数据,文字,表格,图片引用等
media目录用于存放所有文档的图片
_rels目录下的document.xml.rels里存放的是配置信息,比如图片引用关系,即在document.xml中引用id对应media中的哪个图片。
获取zip里的document.xml文档以及_rels文件夹下的document.xml.rels文档
显而易见,如果我们要想根据数据动态导出不同的word文档,只需要:通过freemarker将本次数据填充到document.xml中,并将图片配置信息填充至document.xml.rels文档里,再用文件流把本次图片写入到media目录下替换已经存在的图片,最后把填充过内容的document.xml、document.xml.rels以及media用流的方式写入zip即可输出docx文档!
- 写代码~
@Test
public void ttt() throws Exception {
/** 初始化配置文件 **/
Configuration configuration = new Configuration();
/** 设置编码 **/
/** 我的ftl文件是放在D盘的**/
String fileDirectory = "G:\\work_code";
/** 加载文件 **/
configuration.setDirectoryForTemplateLoading(new File(fileDirectory));
/** 加载模板 **/
Template template = configuration.getTemplate("document.xml");
/** 准备数据,这里是我自己的业务。就是把变量赋值上${xxxx}去啦 **/
Map<String,String> dataMap = detailService.showWordDetail();
/** 指定输出word文件的路径 **/
String outFilePath = "G:\\work_code\\data.xml";
File docFile = new File(outFilePath);
FileOutputStream fos = new FileOutputStream(docFile);
OutputStreamWriter oWriter = new OutputStreamWriter(fos);
Writer out = new BufferedWriter(new OutputStreamWriter(fos),10240);
template.process(dataMap,out);
if(out != null){
out.close();
}
ZipInputStream zipInputStream = ZipUtils.wrapZipInputStream(new FileInputStream(new File("G:\\work_code\\1.zip")));
ZipOutputStream zipOutputStream = ZipUtils.wrapZipOutputStream(new FileOutputStream(new File("G:\\work_code\\test.docx")));
String itemname = "word/document.xml";
ZipUtils.replaceItem(zipInputStream, zipOutputStream, itemname, new FileInputStream(new File("G:\\work_code\\data.xml")));
System.out.println("success");
}
public class ZipUtils {
/**
* 替换某个 item,
* @param zipInputStream zip文件的zip输入流
* @param zipOutputStream 输出的zip输出流
* @param itemName 要替换的 item 名称
* @param itemInputStream 要替换的 item 的内容输入流
*/
public static void replaceItem(ZipInputStream zipInputStream,
ZipOutputStream zipOutputStream,
String itemName,
InputStream itemInputStream
){
//
if(null == zipInputStream){
return;}
if(null == zipOutputStream){
return;}
if(null == itemName){
return;}
if(null == itemInputStream){
return;}
//
ZipEntry entryIn;
try {
while((entryIn = zipInputStream.getNextEntry())!=null)
{
String entryName = entryIn.getName();
ZipEntry entryOut = new ZipEntry(entryName);
// 只使用 name
zipOutputStream.putNextEntry(entryOut);
// 缓冲区
byte [] buf = new byte[8*1024];
int len;
if(entryName.equals(itemName)){
// 使用替换流
while((len = (itemInputStream.read(buf))) > 0) {
zipOutputStream.write(buf, 0, len);
}
} else {
// 输出普通Zip流
while((len = (zipInputStream.read(buf))) > 0) {
zipOutputStream.write(buf, 0, len);
}
}
// 关闭此 entry
zipOutputStream.closeEntry();
}
} catch (IOException e) {
e.printStackTrace();
}finally {
//e.printStackTrace();
close(itemInputStream);
close(zipInputStream);
close(zipOutputStream);
}
}
/**
* 包装输入流
*/
public static ZipInputStream wrapZipInputStream(InputStream inputStream){
ZipInputStream zipInputStream = new ZipInputStream(inputStream);
return zipInputStream;
}
/**
* 包装输出流
*/
public static ZipOutputStream wrapZipOutputStream(OutputStream outputStream){
ZipOutputStream zipOutputStream = new ZipOutputStream(outputStream);
return zipOutputStream;
}
private static void close(InputStream inputStream){
if (null != inputStream){
try {
inputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
private static void close(OutputStream outputStream){
if (null != outputStream){
try {
outputStream.flush();
outputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
- 这时候,神奇的docx就出来啦! 简单吧~

这个docx真的是花了我一周的时间研究。。流下了没有技术的泪水。。
希望这篇文章能帮助到大家!不要被别的坑爹blog误导啦~
问题及解决方案
- 特殊字符
有些文本数据中难免含有特殊字符,如:< > @ ! $ & 等等。
这些特殊字符如果不进行转义,就会引起word打不开的现象,比如表格中的超链接的&符号,就需要替换为&,如果你的文档用office打开时提示文件损坏,九成是因为特殊符号引起的,我们可以打开documet.xml定位报错位置;当然还有终极方案,我们可以利用Freemarker的语法直接在模板中使用 处理。
<w:t><![CDATA[ ${article.title} ]]></w:t>
后记
今天把这个整理成工具类啦,需要的小伙伴自己copy
/**
* @author xyzzg
* @version 1.2
*/
public class WordUtils {
/**
* 本地图片转换Base64的方法
*
* @param imgPath
*/
public static String imageToBase64(String imgPath) {
byte[] data = null;
// 读取图片字节数组
try {
// 打包后Spring试图访问文件系统路径,但无法访问JAR中的路径。 必须使用resource.getInputStream()
ClassPathResource classPathResource = new ClassPathResource(imgPath);
InputStream in = classPathResource.getInputStream();
data = new byte[in.available()];
in.read(data);
in.close();
} catch (IOException e) {
e.printStackTrace();
}
// 对字节数组Base64编码
BASE64Encoder encoder = new BASE64Encoder();
// 返回Base64编码过的字节数组字符串
return encoder.encode(Objects.requireNonNull(data));
}
/**
*
* @param fileDirectory 模板路径 "G:\\work_code";
* @param docxZipPath zip文件的zip输入流
* @param outputDocxName 输出的zip输出流
* @param itemName 要替换的 item 名称 一般固定"word/document.xml"
*
* @param dataMap
* @throws Exception
*/
public static void exportWordDocx(String fileDirectory, String docxZipPath, String outputDocxName, String itemName, Map<String,Object> dataMap) throws Exception {
/** 初始化配置文件 **/
Configuration configuration = new Configuration(DEFAULT_INCOMPATIBLE_IMPROVEMENTS);
/** 加载文件 **/
configuration.setDirectoryForTemplateLoading(new File(fileDirectory));
/** 加载模板 **/
Template template = configuration.getTemplate("document.xml");
/** 指定输出word文件的路径 **/
String outFilePath = fileDirectory + File.separator + "data.xml";
File docFile = new File(outFilePath);
FileOutputStream fos = new FileOutputStream(docFile);
// OutputStreamWriter oWriter = new OutputStreamWriter(fos);
Writer out = new BufferedWriter(new OutputStreamWriter(fos),10240);
template.process(dataMap,out);
if(out != null){
out.close();
}
// ZipUtils 是一个工具类,主要用来替换具体可以看github工程
ZipInputStream zipInputStream = ZipUtils.wrapZipInputStream(new FileInputStream(new File(docxZipPath)));
ZipOutputStream zipOutputStream = ZipUtils.wrapZipOutputStream(new FileOutputStream(new File(outputDocxName)));
ZipUtils.replaceItem(zipInputStream, zipOutputStream, itemName, new FileInputStream(new File(outFilePath)));
}
private WordUtils() {
throw new AssertionError();
}
public static void exportMillCertificateWordDoc(HttpServletResponse response, Map map, String ftlFile, String fileName, String path) throws IOException {
/** 初始化配置文件 **/
Configuration configuration = new Configuration(DEFAULT_INCOMPATIBLE_IMPROVEMENTS);
/** 加载文件 **/
configuration.setDirectoryForTemplateLoading(new File("xxxxxxx"));
Template freemarkerTemplate = configuration.getTemplate(ftlFile);
File file = null;
InputStream fin = null;
OutputStream os = null;
try {
// 调用工具类的createDoc方法生成Word文档
file = createDoc(map, freemarkerTemplate);
// ClassPathResource classPathResource = new ClassPathResource("files");
// 保存word至bash文件夹
// 1K的数据缓冲
byte[] bs = new byte[1024];
// 读取到的数据长度
int len;
File tempFile = new File(path);
if (!tempFile.exists()) {
tempFile.mkdirs();
}
fin = new FileInputStream(file);
os = new FileOutputStream(tempFile.getPath() + File.separator + fileName);
// 开始读取
while ((len = fin.read(bs)) != -1) {
os.write(bs, 0, len);
}
} catch (IOException e){
e.printStackTrace();
} finally {
if (fin != null) fin.close();
if (file != null) file.delete(); // 删除临时文件
}
}
private static File createDoc(Map<?, ?> dataMap, Template template) {
String name = "sellPlan.doc";
File f = new File(name);
Template t = template;
try {
// 这个地方不能使用FileWriter因为需要指定编码类型否则生成的Word文档会因为有无法识别的编码而无法打开
Writer w = new OutputStreamWriter(new FileOutputStream(f), "utf-8");
t.process(dataMap, w);
w.close();
} catch (Exception ex) {
ex.printStackTrace();
throw new RuntimeException(ex);
}
return f;
}
}
如果生成后不满意格式,修改模板和前几步骤一样:
- 改docx模板
- 改docx后缀名为zip,放到配置的目录里
- 拿出来这个word/document.xml放到配置的目录里