上一章我们简单的介绍了布尔代数以及C语言的位运算,本次我们主要来看,二进制如何表示整数,这是很重要的一章,希望各位猿友莫要错过。
C语言中的整数类型及范围
我们依然以C语言为例,C语言当中提供了多种整数类型,一共十种,位数为1、2、4、8,其中32位机器上,4位的有两种,在64位机器上,8位的有两种。具体的LZ这里就不多做介绍了。以下是32位和64位系统上,这十种整数的范围。

上述是C语言中各个整数类型的表示范围,不过C语言有它的最小数值范围,也就是说C语言要求这些数据类型至少要满足一个标准的范围。下图是C语言对整数类型要求的最小表示范围。

仔细看的话,可以发现,C语言只要求有符号数的范围是对称的,另外就是int和long类型的位数要求都比较低,分别是2位和4位。
无符号编码
可以看到以上的表中,每一种整数类型都可以加unsigned关键字,来表示一个无符号数,即没有正负之分。在书中,给出了无符号数的定义,LZ将它简化一下,对于一个w位的二进制来说,它的无符号表示为以下形式。

对于一个无符号编码来说,它的最大值和最小值很好确定,对于一个w位的二进制序列来说,当所有位都为0时,则为最小值,即
UMinw = 0
而当所有位都为1时,则为最大值,根据等比数列的求和公式,即
UMaxw = 1 * (1-2w) / 1 - 2 = 2w - 1
如果把上述的定义看成是一个函数的话,那么这个函数就是一个双射。也就是说,对于任意整数x,当0 =< x < 2w的时候,存在唯一的二进制序列与其对应。反过来也是一样的,对于任意一个w位的二进制序列,都存在唯一一个整数x满足0 =< x < 2w,与这个二进制序列对应。
无符号编码属于相对较简单的格式,因为它符合我们的惯性思维,上述定义其实就是对二进制转化为十进制的公式而已,只不过在一向严格的数学领域来说,是要给予明确的含义的。
补码编码
无符号编码符合人的惯性思维是没错,但是可惜的是,它无法表示负整数。因此我们需要一种能够表示负数的整数表示方式,这就是补码编码。与无符号编码一样,书中依然给出了补码编码的定义,即对于任意一个w位的二进制来说,它的补码表示为以下形式。
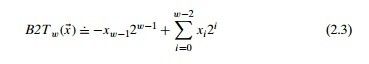
这里最高位xw-1为符号位,当它为1时,该公式得到的值为负数,当为0时,得到的则为正数。
我们观察这个公式,不难看出,补码格式下,对于一个w位的二进制序列来说,当最高位为1,其余位全为0时,得到的就是补码格式的最小值,即
TMinw = -2w-1
而当最高位为0,其余位全为1时,得到的就是补码格式的最大值,根据等比数列的求和公式,即
TMaxw = 1 * (1 - 2w-1) / 1 - 2 = 2w-1-1
与无符号编码一样,如果把上述的定义看成是一个函数的话,那么这个函数同样是一个双射。也就是说,对于任意整数x,当-2w-1 =< x < 2w-1的时候,存在唯一的二进制序列与其对应。反过来,对于任意一个w位的二进制序列,都存在唯一一个整数x满足-2w-1 =< x < 2w-1,与这个二进制序列对应。
相对于无符号编码来说,补码编码与我们的惯性思维有些不同,因此直观的理解起来会有些别扭,不过作为一个程序猿,我们应该有一颗半机器的脑子,尽量去适应机器的习惯。
两种编码的转换
在C语言当中,我们经常会使用强制类型转换,而在之前的章节中,LZ也提到过强制类型转换。强制类型转换不会改变二进制序列,但是会改变数据类型的大小以及解释方式,那么考虑相同整数类型的无符号编码和补码编码,数据类型的大小是没有任何变化的,变化的就是它们的解释方式。比如1000这个二进制序列,如果用无符号编码解释的话就是表示8,而若采用补码编码解释的话,则是表示-8。
考虑到上面我们已经说过,无论是无符号编码还是补码编码,其映射方式都是双射,因此它们都一定存在逆映射。如果我们定义U2Bw(x)为B2Uw(x)的逆映射,则对于任意一个整数x,如果0 =< x < 2w,经过U2Bw(x)的计算之后,将得到唯一一个二进制序列。同样的,如果我们定义T2Bw(x)为B2Tw(x)的逆映射,则对于任意一个整数x,如果-2w-1 =< x < 2w-1,经过T2Bw(x)的计算之后,也将得到唯一一个二进制序列。
可以很明显的看出,对于0到2w-1-1这个区间内的整数来说,两种编码得到的二进制序列是一样的。为了得到其它区间里的整数的映射关系,我们定义
T2Uw(x) = B2Uw(T2Bw(x))
这个函数代表的含义是补码编码转换为无符号编码的时候,先将补码编码转换为二进制序列,再将二进制序列转换为无符号编码,最终也就是补码编码转为无符号编码的计算。
下面我们简单的推算一下上面的定义,究竟是如何转换的,也就是无符号编码与补码编码的关系。我们将上面无符号编码和补码编码的公式相减,
即 B2Uw(x) - B2Tw(x) = xw-12w-1 - (-xw-12w-1) = xw-12w
即 B2Uw(x) = xw-12w + B2Tw(x)
此处我们令x为T2Bw(x),则 B2Uw(T2Bw(x)) = xw-12w + B2Tw(T2Bw(x)) = xw-12w + x
即 T2Uw(x) = xw-12w + x
此时考虑xw-1的情况,当xw-1为1时,也就是补码编码表示负数的时候,T2Uw(x)则为2w + x 。(LZ小提示:此时x为负数,也就是说2w + x < 2w)
若xw-1为0时,则补码编码为正数,此时T2Uw(x) = x 。
综上可知,有下列式子成立

从这个式子中可以很明显的看出,最终得到的无符号数范围为0 =< x < 2w。
下图为表示补码编码与无符号编码的对应关系,可以看出在0至2w-1-1之间,两者是相等的,而其余区间则不同。

相反,我们用同样的方式也可以证明从无符号编码到补码编码的公式,这一部分书中省略了,LZ这里还是写上来,以免有的猿友不知所云。我们依然将无符号编码和补码编码的公式相减
即 B2Uw(u) - B2Tw(u) = uw-12w-1 - (-uw-12w-1) = uw-12w
即 B2Tw(u) = B2Uw(u) - uw-12w
此时我们令u为U2Bw(u),则 B2Tw(U2Bw(u)) = B2Uw(U2Bw(u)) - uw-12w = u - uw-12w
即 U2Tw(u) = u - uw-12w
此时考虑uw-1的情况,当uw-1为0时,也就是无符号编码数值小于2w-1的时候,U2Tw(u)则为u 。
若uw-1为1时,也就是无符号编码数值大于或等于2w-1的时候,此时U2Tw(u)= u - 2w。(LZ小提示:此时U2Tw(u)为负数,因为 u < 2w)
综上,我们可以得到无符号编码转换为补码编码的公式
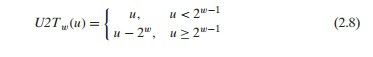
同样的,在0至2w-1-1之间,两者依然是相等的,而其余区间则不同。

小例子
以上则是我们讨论的有符号编码与补码编码的内容,下面为了让大家更好的理解上面的公式的含义,LZ带大家写一个小程序,我们来直观的在两者之间做一下强制转换,看下得到的值是否满足我们上面的结论。
为了简单起见,我们取w为8,也就是我们只采用char类型作为例子,否则位数太高的话,算起来比较麻烦。LZ本次采用32位WIN7系统下,VS2010作为例子的编译环境。
#include
int main(){
char t = 0xFF;
unsigned char u = 0xFF;
printf("t=%d u=%u\n",t,u);
printf("t2u=%u u2t=%d\n",(unsigned char)t,(char)u);
}
我们给了两个同样的二进制序列0xFF,都是8个1,我们分别用补码编码和无符号编码去解释它们,并在后面使用强制转换在补码编码和无符号编码之间互相转换,得到以下结果。
t=-1 u=255
t2u=255 u2t=-1
这里LZ就不再写计算的过程了,这个计算并不难。各位猿友可以自己套用上面的(2.6)和(2.8)公式去计算,看看是否符合公式的规定。
本章小结
本章主要介绍了二进制表示整数时采用的无符号编码以及补码编码,也算是至今为止最难的一章了,因为搀和到了证明,尽管这是很简单的证明。各位猿友若看不懂的话,可以去LZ的交流群询问,希望猿友们不要中途放弃。