Java内存区域和对象创建、引用
文章目录
-
-
-
- 运行数据区域:
-
- 1.程序计数器:
- 2.虚拟机栈:
- 3.本地方法栈:
- 4.Java堆:
- 5.方法区:
- Java对象探秘:
-
-
- 1.对象的创建:
- 2.对象的内存布局:
- 3.对象的访问定位:
-
- 举个栗子:
-
-
运行数据区域:
JVM在运行过程中会把它所管理的内存划分成几个不同的运行数据区域。其中,有线程共享的堆和方法区,还有线程私有的虚拟机栈、本地方法栈、和程序计数器。
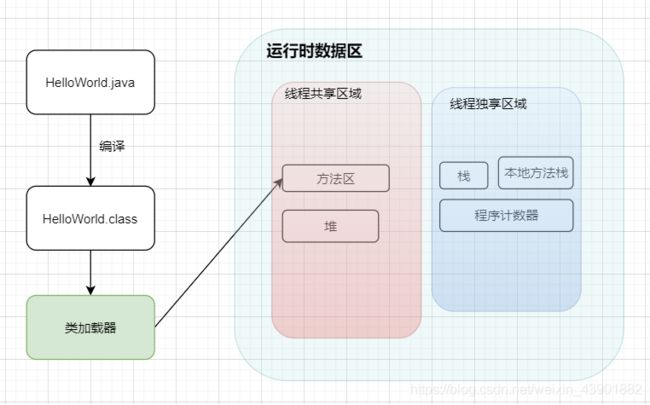
1.程序计数器:
其可以看作是当前线程所执行字节码的行号指示器,该区域是线程私有的,为了准确记录各个线程正在执行字节码指令的地址,多线程下各个线程就互不干扰。
如果线程正执行一个Java方法,这个计数器记录的是正在执行的虚拟机字节码指令的地址。
如果执行的是Native方法,这个计数器值为空(undefined)
此内存区域是唯一没有OOM的区域
2.虚拟机栈:
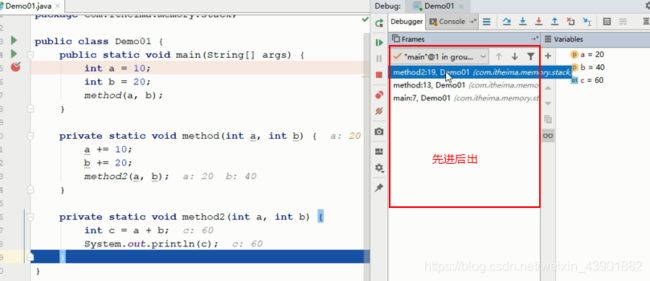
虚拟机栈描述的是Java方法执行的内存模型,每个方法在执行的同时都会创建一个栈帧,用于存储局部变量表、操作数栈、动态链接、方法出口等信息。
在IDea中debug可以看到,每次调用方法都会创建一个栈帧,每个栈帧是先进后出。
栈帧在虚拟机的入栈到出栈,就是Java方法从调用到执行完成的过程。
局部变量表: 存放了编译期可知的各种基本数据类型(boolean、byte、char、short、int、float、long、double)、对象引用(reference 类型,它不等同于对象本身,根据不同的虚拟机实现,它可能是一个指向对象起始地址的引用指针,也可能指向一个代表对象的句柄或者其他与此对象相关的位置)和 returnAddress 类型(指向了一条字节码指令的地址)。
局部变量表所需要的内存空间在编译期完成分配,当进入一个方法时,这个方法在栈中需要分配多大的局部变量空间是完全确定的,在方法运行期间不会改变局部变量表大小。
大小: 线程请求的栈深度大于虚拟机允许的栈深度,将抛出StackOverflowError。
虚拟机栈空间可以动态扩展,当动态扩展是无法申请到足够的空间时,抛出OutOfMemory异常。
3.本地方法栈:
如同虚拟机栈为虚拟机执行Java方法服务一样,本地方法栈为虚拟机使用到的Native方法服务
4.Java堆:
该内存区域的唯一目的就是 存放对象实例,同时它也是GC(垃圾收集管理器)所管理的主要区域。Java堆中还可以细分为新生代和老年代等等,不做深究。
5.方法区:
用于存储已被虚拟机加载的类信息(类的版本、字段、方法等)、常量、静态变量,如static修饰的变量加载类的时候就被加载到方法区中。
在类加载的加载阶段,将.Class文件转换为方法区的运行时数据结构。
运行时常量池:
运行时常量池是方法区的一部分,.class文件除了有类的字段、接口、方法等描述信息之外,还有常量池,其用于存
放编译期间生成的各种字面量和符号引用,这部分内容在类加载(加载阶段)后进入方法区的运行时常量池。
int a = 1; //1 就是字面量
String a = “abc”; //abc 就是字符串字面量。
运行时常量池具有动态性,运行期间也可以将新的常量放入池中,比如String.intern()方法。举个栗子:
public class Test{
public static void main(String[] args){
String s1 = "abc";
String s2 = "abc";
System.out.println(s1 == s2);
String s3 = new String("abc");
System.out.println(s1 == s3);
System.out.println(s1 == s3.intern());
}
}
abc是字符串字面量,存放于运行时常量池中;s1存放于栈(虚拟机栈)中,并指向abc;代码又上往下执行,s2存
放于栈中,并指向运行时常量池中同一个abc。== 比较的是引用地址,所以s1==s2为true;
new新建会在Java堆中开辟看块新内存存储abc,s3作为对象引用存储在栈中,显然,s1 == s3为false。
s3.intern()会将堆中abc放入运行时常量池,因为abc在池中本来就有了,所以其引用地址和s1是一样的,所以结果
为true。
Java对象探秘:
1.对象的创建:
.java文件编译后生成的各种字面量和符号引用,这部分内容在类加载(加载阶段)后进入方法区的运行时常量池。
虚拟机遇到一条new指令时,首先将去检查这个指令的参数是否能在常量池中定位到一个类的符号引用,并且检查这个符号引用表的类是否已被加载,解析和初始化过。如果没有,那必须先执行相应的类加载过程。在类加载检查通过后,接下来虚拟机将为新生对象分配内存。
类加载的生命周期:加载、连接(验证、准备、解析)、初始化、使用和卸载
遇到一条new指令时,首先将去检查这个指令的参数是否能在常量池中定位到一个类的符号引用(如果没有,则执行类加载的加载阶段)
检查这个符号引用表的类是否已被加载,解析和初始化过(如果没有,则执行相应的解析、初始化阶段)。
在类加载检查通过后,接下来虚拟机将为新生对象分配内存。
内存分配方式:
1). 指针碰撞(Java堆内存规整):
所有已使用的内存放在一边,空闲的在另一边,中间放着一个指针作为分界点的指示器,那所分配的内存仅仅就是
把那个指针向空闲的那边挪动一段与对象大小相等的距离
2). 指针碰撞(Java堆内存不规整):
虚拟机维护一个列表,记录哪些内存块是可用的,再分配的时候从列表中找到一块足够大的空间会分给对象实例,
并更新列表记录。

线程安全解决:
1). 线程安全问题:
虚拟机正给对象A分配内存,指针还没来得及修改,对象B又同时使用原来的指针来分配内存的情况。
2). 解决:

调用对象初始化方法:
开始执行< init >方法进行对象的初始化,按照程序员的意愿初始化对象,至此一个真正可用的对象才算产生。
2.对象的内存布局:
对象在内存中存储的布局分3块区域:对象头、实例数据(对象真正存储的有效信息)、对齐填充(占位用的)。
对象头(Header): 包括用于存储对象自身的运行时数据(Mark World)和类型指针。
1). 自身运行时数据(Mark World): 包括哈希码、GC分代年龄、锁状态标志、线程持有的锁等等。
2). 类型指针: 对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例。
3.对象的访问定位:
1). 使用句柄: Java堆中划分一块内存作为句柄池,reference中存储的是对象的句柄地址,而句柄中包含对象实例数据和类型数据各自的具体地址。
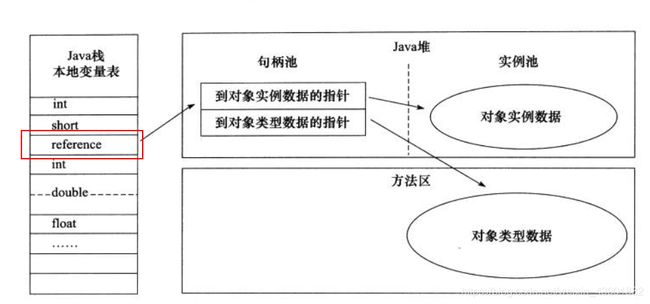
2). 直接指针: reference中存储的直接就是对象的地址,HotSpot虚拟机主要使用的。

3). 二者优点:

举个栗子:
Student类:
public class Student{
public String name;
public Student(String name){
this.name = name;
}
public void sayWord(String Word){
//Word="helloWord";
}
}
程序入口类:
public class APP{
public static void main(String[] args){
Student stu = new Student("abc");
String s1 = "hello";
stu.sayWord(s1);
System.out.println(s1);
}
}
过程:
1). 编译好 App.java 后得到 App.class 后,执行 App.class,系统会启动一个 JVM 进程,从 classpath 路径中找到一个名为 App.class 的二进制文件,将 App 的类信息加载到运行时数据区的方法区内(类加载)。
2). JVM 找到 App 的主程序入口,执行main方法。
3). 自上而下执行,遇到new指令,发现方法区的运行时常量池没有Student类的符号引用,则先加载Student类(可见类加载是懒加载)
4). 加载完 Student 类后,JVM 再在堆中为一个新的 Student 实例分配内存,然后调用< init >()构造函数初始化 Student 实例。
5). (直接指针)此时栈中存储对象引用stu,指向堆中Student的地址,这个 Student 内存区域(实例)持有实例数据(如name = abc)和指向方法区中的 Student 类的类型数据的指针。
6). 执行String s1 = “hello”; 在main()栈帧的局部变量表存储了s1(字符串为引用类型),指向方法区的字符串字面量"hello"
6).执行stu.sayWord(s1);时,JVM 根据 stu 的引用找到 student 对象,然后根据 student 对象持有的引用定位到方法区中 student 类的类型信息的方法表,获得 sayWord(s1) 的字节码地址。
7). 执行sayWord(s1)。
8). 虚拟机栈创建一个栈帧sayWord,该栈帧的局部变量表存储了Word,指向方法区的字符串字面量"hello",方法调用即入栈,调用完毕即出栈。
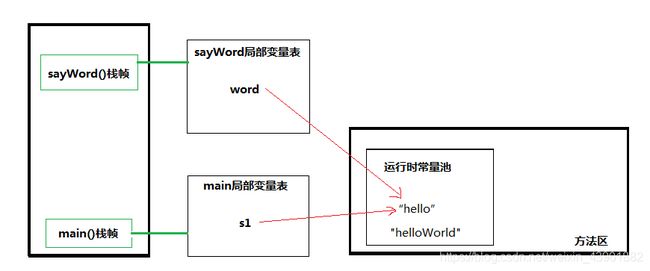
如果在sayWord方法中修改了Word=“helloWorld"的值,实际是在常量池中新开辟了"helloWorld"的内存,Word重新指向"helloWorld”,所以在main()中打印s1还是 “hello”
参考:
《深入理解Java虚拟机:JVM高级特性与最佳实践(第二版)》
大部分内容均来自这本书,下图为思维导图。
互相交流,互相学习,有误指正。