引言
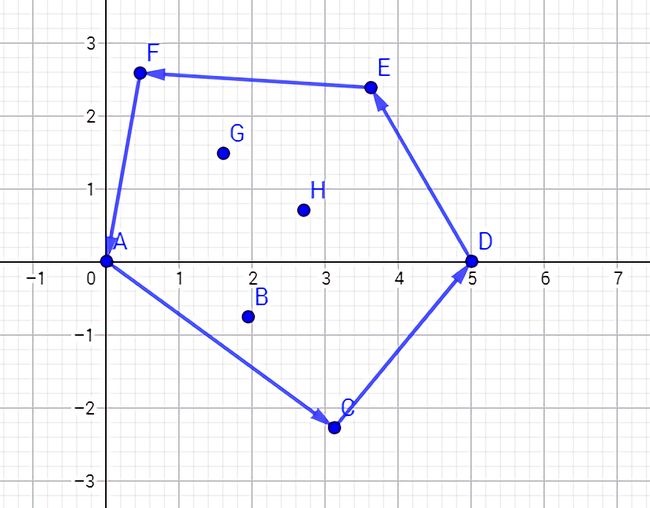
首先介绍下什么是凸包?如下图:
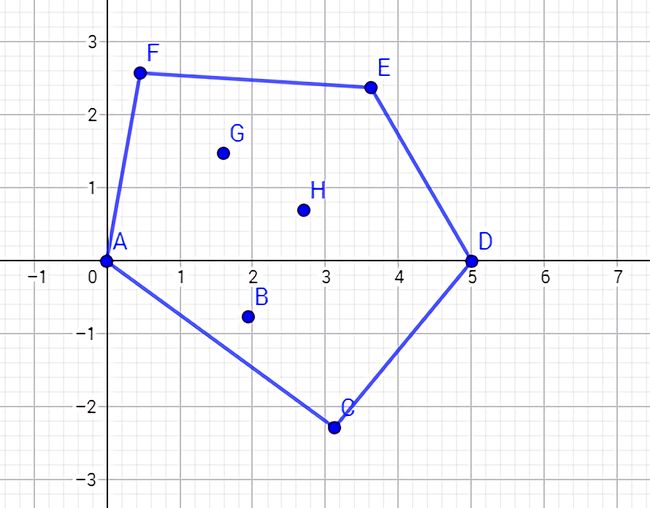
在一个二维坐标系中,有若干点杂乱排列着,将最外层的点连接起来构成的凸多边型,它能包含给定的所有的点,这个多边形就是凸包。
实际上可以理解为用一个橡皮筋包含住所有给定点的形态。
凸包用最小的周长围住了给定的所有点。如果一个凹多边形围住了所有的点,它的周长一定不是最小,如下图。根据三角不等式,凸多边形在周长上一定是最优的。
凸包的求法
寻找凸包的算法有很多种,常用的求法有 Graham 扫描法和 Andrew 算法
Graham Scan 算法求凸包
Graham Scan 算法是一种十分简单高效的二维凸包算法,能够在 \(O(nlogn)\) 的时间内找到凸包。
Graham Scan 算法的做法是先确定一个起点(一般是最左边的点和最右边的点),然后一个个点扫过去,如果新加入的点和之前已经找到的点所构成的 "壳" 凸性没有变化,就继续扫,否则就把已经找到的最后一个点删去,再比较凸性,直到凸性不发生变化。分别扫描上下两个 "壳",合并在一起,凸包就找到了。这么说很抽象,我们看图来解释:

先找 "下壳",上下其实是一样的。首先加入两个点 A 和 B。
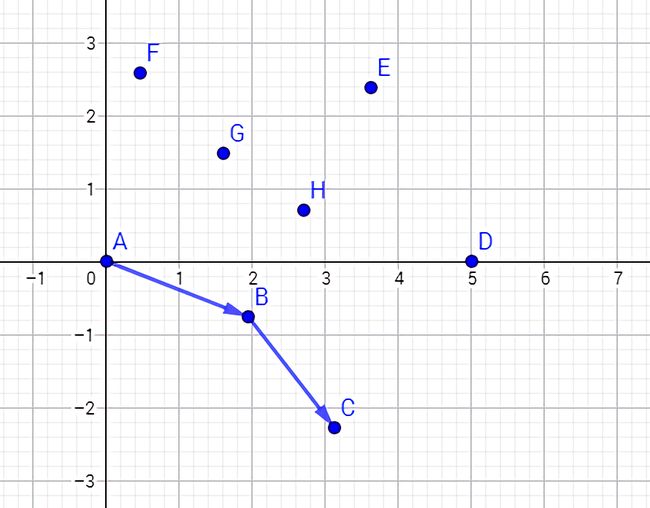
然后插入第三个点 C,并计算 \(\overrightarrow{AB}×\overrightarrow{BC}\) 的向量积,却发现向量积系数小于(等于)0,也就是说 \(\overrightarrow{BC}\) 在 \(\overrightarrow{AB}\) 的顺时针方向上。
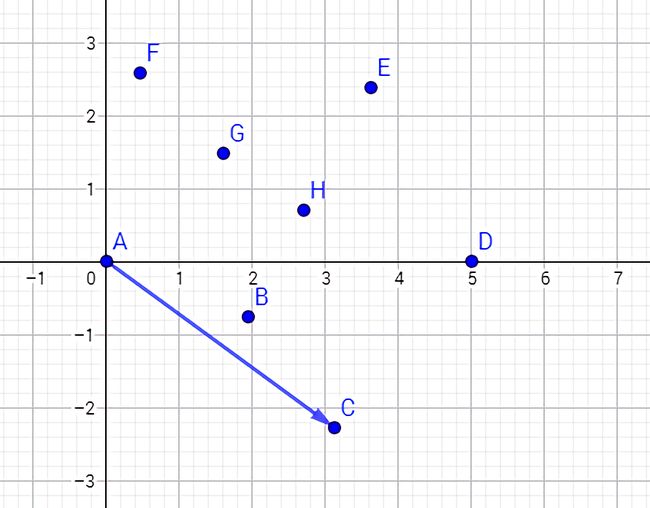
于是删去 B 点。
按照这样的方法依次扫描,找完 "下壳" 后,再找 "上壳"。
关于扫描的顺序,有坐标序和极角序两种,本文采用前者。坐标序是比较两个点的 x 坐标,小的先被扫描(扫描上凸壳的时候反过来),如果两个点 x 坐标相同,那么就比较 y 坐标,同样的也是小的先被扫描(扫描上凸壳的时候也是反过来)。极角序使用 atan2 函数的返回值进行比较,读者可以自己尝试写下。
下面贴下代码:Graham Scan 算法
struct Point
{
double x, y;
Point operator-(Point & p)
{
Point t;
t.x = x - p.x;
t.y = y - p.y;
return t;
}
double cross(Point p) // 向量叉积
{
return x * p.y - p.x * y;
}
};
bool cmp(Point & p1, Point & p2)
{
if (p1.x != p2.x)
return p1.x < p2.x;
return p1.y < p2.y;
}
Point point[1005]; // 无序点
int convex[1005]; // 保存组成凸包的点的下标
int n; // 坐标系的无序点的个数
int GetConvexHull()
{
sort(point, point + n, cmp);
int temp;
int total = 0;
for (int i = 0; i < n; i++) // 下凸包
{
while (total > 1 &&
(point[convex[total - 1]] - point[convex[total - 2]]).cross(point[i] - point[convex[total - 1]]) <= 0)
total--;
convex[total++] = i;
}
temp = total;
for (int i = n - 2; i >= 0; i--) // 上凸包
{
while (total > temp &&
(point[convex[total - 1]] - point[convex[total - 2]]).cross(point[i] - point[convex[total - 1]]) <= 0)
total--;
convex[total++] = i;
}
return total - 1; // 返回组成凸包的点的个数,实际上多了一个,就是起点,所以组成凸包的点个数是 total - 1
}
Andrew 算法求凸包
首先把所有点以横坐标为第一关键字,纵坐标为第二关键字排序。
显然排序后最小的元素和最大的元素一定在凸包上。而且因为是凸多边形,我们如果从一个点出发逆时针走,轨迹总是“左拐”的,一旦出现右拐,就说明这一段不在凸包上。因此我们可以用一个单调栈来维护上下凸壳。
因为从左向右看,上下凸壳所旋转的方向不同,为了让单调栈起作用,我们首先 升序枚举 求出下凸壳,然后 降序 求出上凸壳。
求凸壳时,一旦发现即将进栈的点( \(P\) )和栈顶的两个点( \(S_1,S_2\) ,其中 \(S_1\) 为栈顶)行进的方向向右旋转,即叉积小于 \(0\) : \(\overrightarrow{S_2S_1}\times \overrightarrow{S_1P}<0\) ,则弹出栈顶,回到上一步,继续检测,直到 \(\overrightarrow{S_2S_1}\times \overrightarrow{S_1P}\ge 0\) 或者栈内仅剩一个元素为止。
通常情况下不需要保留位于凸包边上的点,因此上面一段中 \(\overrightarrow{S_2S_1}\times \overrightarrow{S_1P}<0\) 这个条件中的“ \(<\) ”可以视情况改为 \(\le\) ,同时后面一个条件应改为 \(>\) 。
代码实现
// stk[]是整型,存的是下标
// p[]存储向量或点
tp = 0; //初始化栈
std::sort(p + 1, p + 1 + n); //对点进行排序
stk[++tp] = 1;
//栈内添加第一个元素,且不更新used,使得1在最后封闭凸包时也对单调栈更新
for (int i = 2; i <= n; ++i) {
while (tp >= 2 //下一行*被重载为叉积
&& (p[stk[tp]] - p[stk[tp - 1]]) * (p[i] - p[stk[tp]]) <= 0)
used[stk[tp--]] = 0;
used[i] = 1; // used表示在凸壳上
stk[++tp] = i;
}
int tmp = tp; // tmp表示下凸壳大小
for (int i = n - 1; i > 0; --i)
if (!used[i]) {
// ↓求上凸壳时不影响下凸壳
while (tp > tmp && (p[stk[tp]] - p[stk[tp - 1]]) * (p[i] - p[stk[tp]]) <= 0)
used[stk[tp--]] = 0;
used[i] = 1;
stk[++tp] = i;
}
for (int i = 1; i <= tp; ++i) //复制到新数组中去
h[i] = p[stk[i]];
int ans = tp - 1;
根据上面的代码,最后凸包上有 \(ans\) 个元素(额外存储了 \(1\) 号点,因此 \(h\) 数组中有 \(ans+1\) 个元素),并且按逆时针方向排序。周长就是
参考
- Graham Scan 凸包算法
- Andrew 凸包算法