首先要从Innodb怎么看待磁盘物理空间说起
一块原生的(Raw)物理磁盘,可以把他看成一个字节一个字节单元组成的物理存储介质
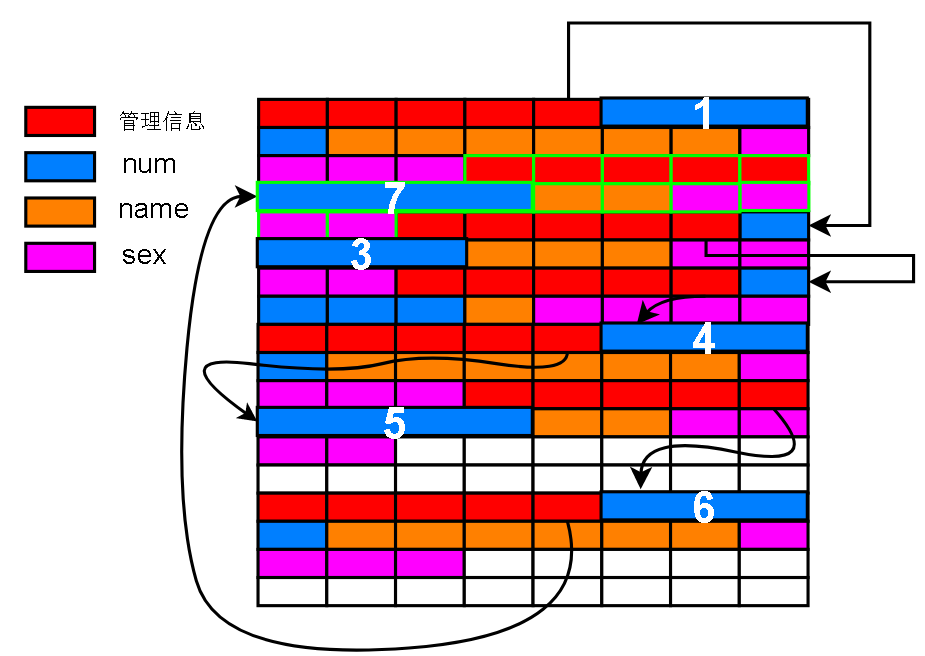
如果要在这块原生物理空间中插入一条记录,不能单单只插入数据,还需要插入一些管理记录的信息,这些管理信息被称为记录头,这里假设是5字节(compact类型记录确实记录头占用5字节,简单通俗起见,可以忽略这段括号内的解释)

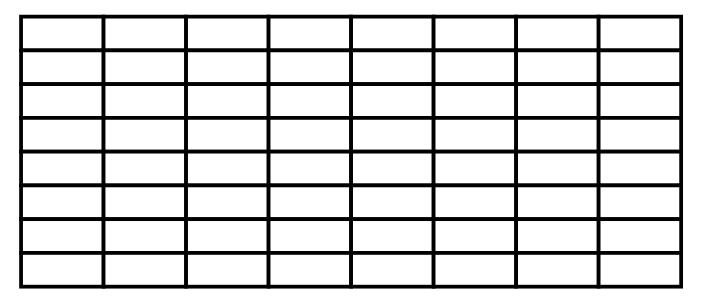
然后在记录头后面插入列,假如要插入的记录的各个列是:
![]()
其中 num 是主键 (int类型)
name 是 varchar 类型的
sex 是 int 类型的
那么按照 int 占用 4 字节,不超过长度阈值(8000+)的 varchar 按照实际长度 ('abc' 占 3 字节) 存储的规则 把这条记录填充到 Raw物理空间中

问题来了:管理信息有什么用呢?
在存储组织上最重要的用处是找到下一条记录

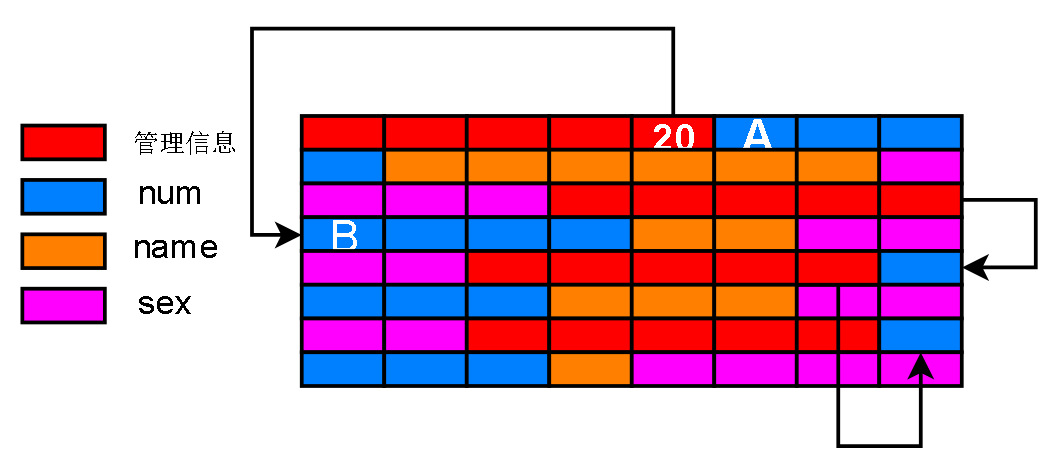
不能直接找到下一条记录吗?不能。假如我已经知道了第一条记录数据的开头部分,也就是上图第一个蓝色方格(A)的编号
现在插入多一条记录:
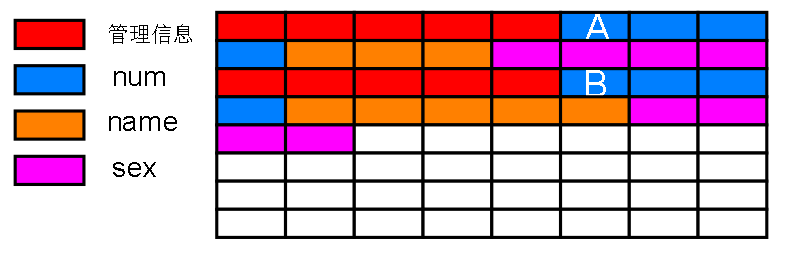
如何才能获取第二条记录的第一个蓝色方格(B)编号? 这个蓝色方格(B)就是第二条记录数据部分的起始地址
可不可以用 A 的编号加上偏移量得到呢?

B的编号 = A 的编号 + 8 + 6 ? 实际上不行,因为黄色部分的 name 是不定长的,偏移量也不一定,就如下图,偏移量随着不定长字段长度改变而改变
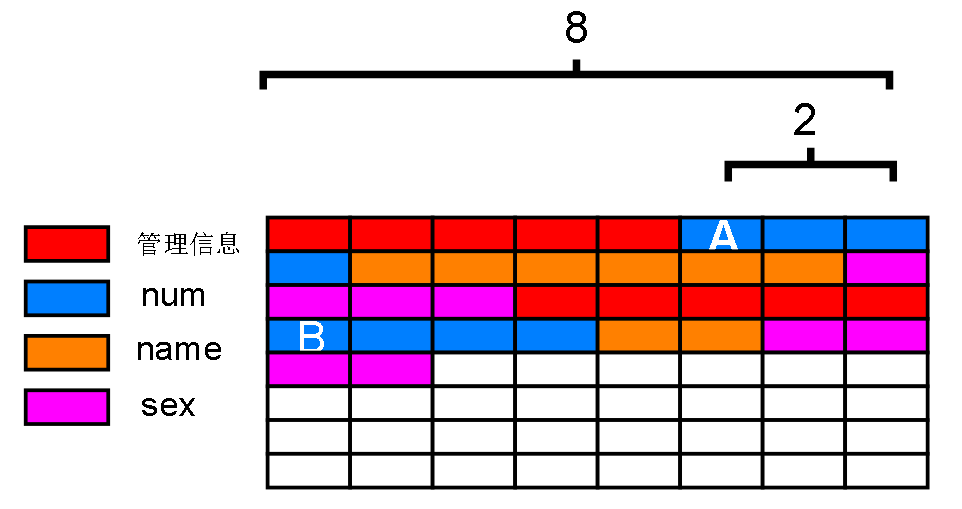
管理信息可以记录下一条记录编号的偏移量
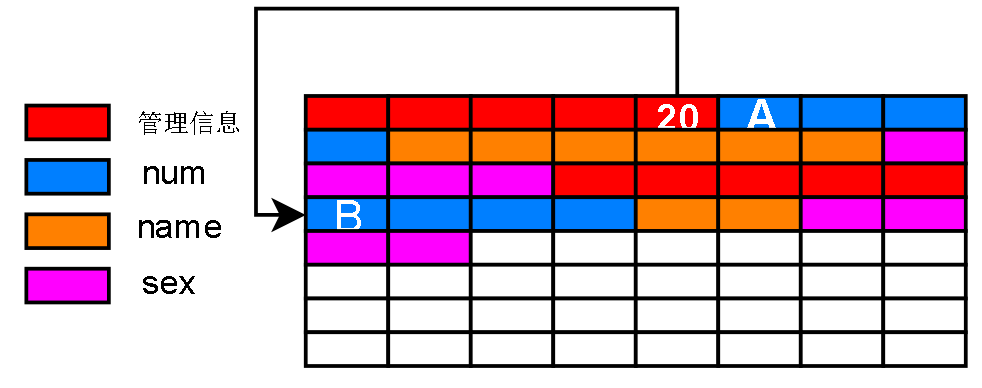
形成一种链表管理方式:每条记录的数据部分可以看成一个结点
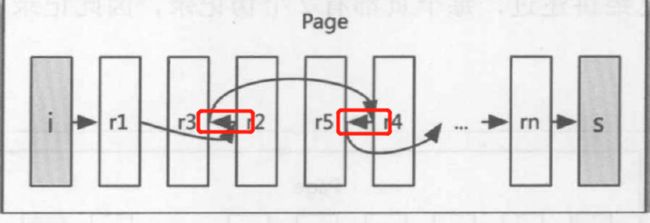
把他抽象一下就得到了 下图这种方式

但是为什么会有倒着指的情况存在呢?
(图 A )
假如删除第二条记录:
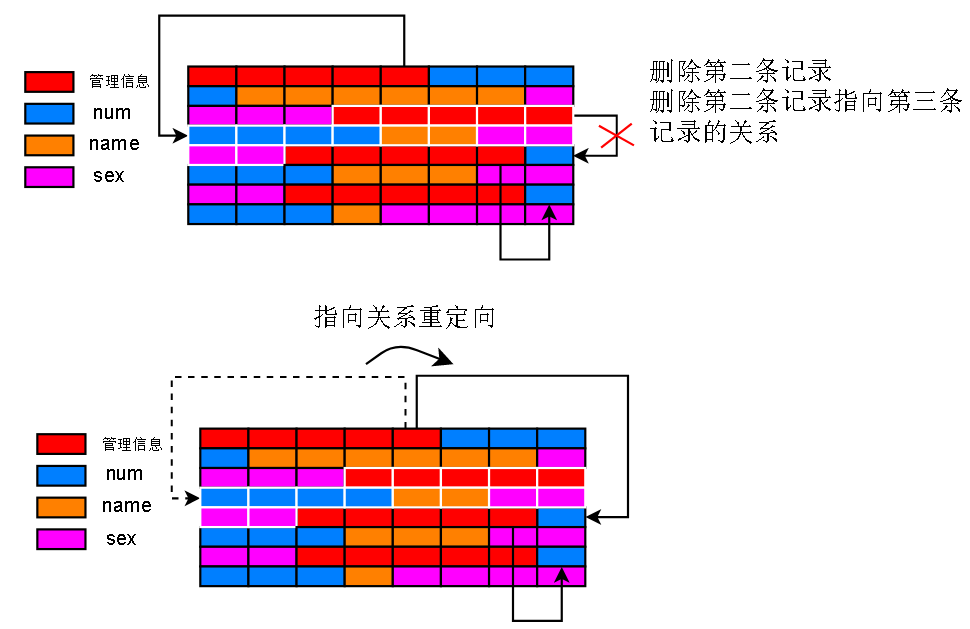
最后,被删除的第二条记录被移出了上面提到的,存储有用记录的链表

如果把整个物理空间扩大,找到其他同样也是被删除的记录。实际上这些被删除的记录,会被标记为空闲状态(管理信息中有标志位)
然后采用实际有用的数据相同的链接方式,连接成一条链表,称为空闲链表
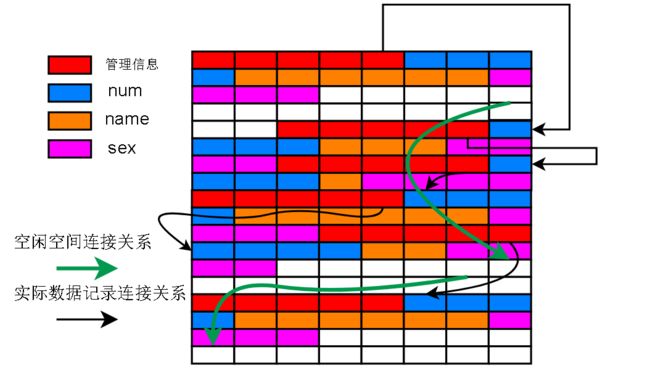
下次再插入一条数据的时候,如果从空闲链表中找到了符合要插入记录大小的空闲空间(上图白色部分)就会把这一部分分配出去
下图绿色的部分是新记录,当然新记录不一定会占满之前留下的空闲空间
蓝色的那条指向,是一条倒着的指向,也就可以解释之前图 A 上为什么有倒着的链表指向了

所以,一个物理上的数据中的记录是逻辑上按照链表顺序连接起来的,并且是按照主键递增的顺序连接成一条单链表
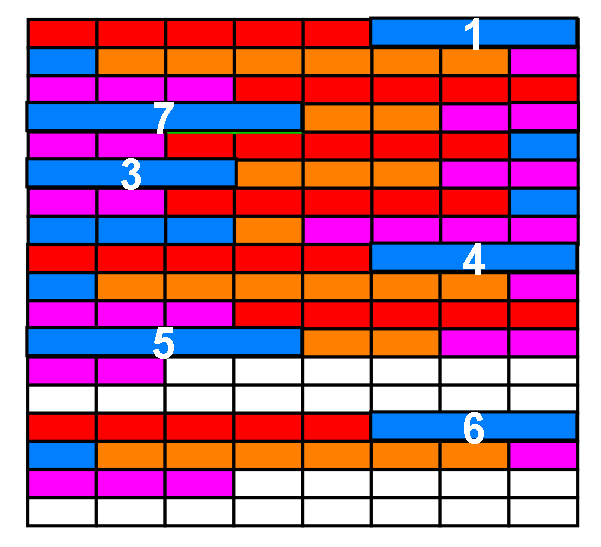
之前说过,4字节的num是主键,如果删除的是 主键 = 2 的记录,那么最后物理上看起来是这样的:
新增加的记录,主键是 7,占用了被删掉的记录(主键 = 2)的位置(不一定能占满,上图是假设占满了)
之所以说这条链表是逻辑上主键递增的,是因为在物理上这条链表并不是主键递增,上图最明显的不是递增特点表现在7插在了1和3之间
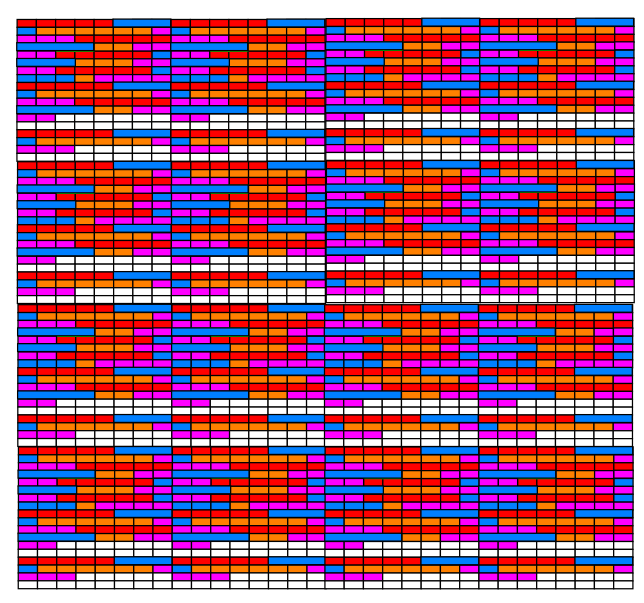
我们把下图的这一块称为一个数据页,数据页是 Innodb 磁盘存储管理的最小单位。当然,实际上数据页不会像下图这样才几条记录,下图只是一个迷你版的表示
默认数据页真正大小一般是16 KB , 真正看起来可能是密密麻麻一大片:
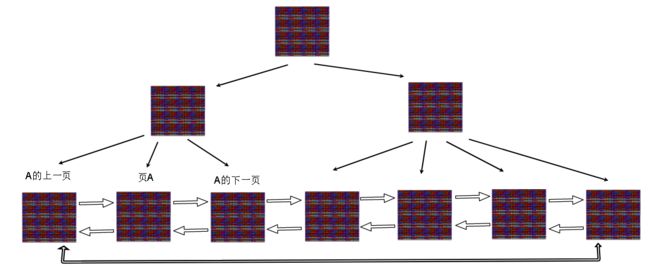
每一页都持有上一页和下一页在物理文件中的编号(地址)页和页之间可以串起来:
(实际上是页结构中的File Header部分保存了上一页/下一页在表空间文件中的偏移量(编号)
如果一个独立的表空间文件(.idb) 的大小是1GB,每个页的大小是 16KB, 那么总共有1GB / 16KB = 65536个页
下文均讨论聚簇索引

(下文的B+树都是简化的,实际上B树节点的度不会那么小)
这些页都是 Innodb 的 B+ 树存储结构中的 数据页节点,也就是叶子节点
可以加上非叶子节点(索引节点),让他成为一颗完整的 B+ 树:
现在大概有一个存储结构的大体认识了,来解决一个比较深入的问题:上图的索引节点是什么,怎么通过这些索引节点做查找
首先了解表的存储结构:如果使用独立表空间,表的索引和记录将会存储在一个独立的idb文件中
idb文件可以按照规定好的数据页大小切分成若干页

每个数据页都有自己独特的页号,其实就是页的偏移量,可以唯一表示一个数据页

需要注意的是物理页的物理顺序和逻辑顺序可能不一样,比如:
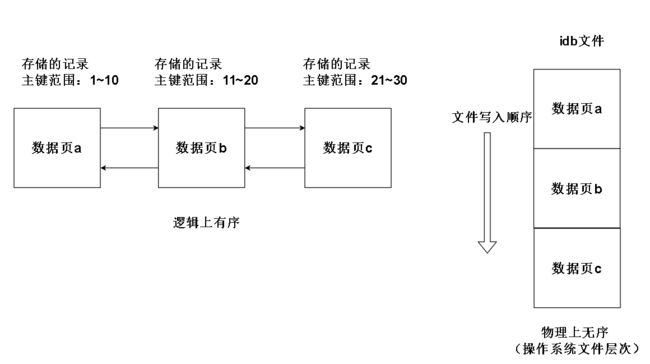
数据页无需的结果可能是这样的:
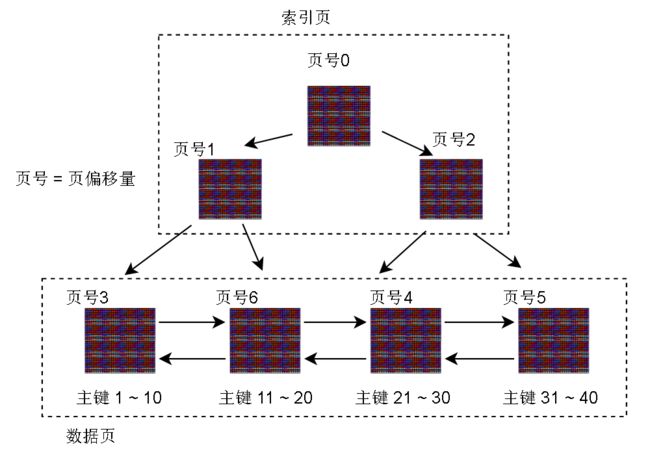
聚簇索引页的记录只是简单的把页的最小主键值和页的页号关联起来

聚簇索引页的上一层索引页(逻辑上)也只是简单的记录下层索引页最小主键值和页号的映射
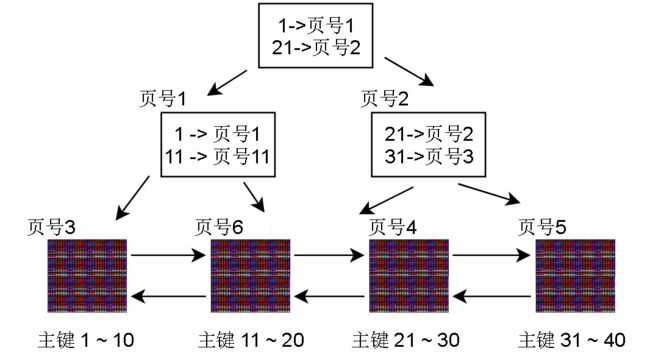
当然,Innodb的B+树的扇出度 (fan out)是很高的,像上图这样少量的数据页一般只有一层索引节点,且只有一个。
回到一开始我们的目的,假如我要查询 主键 = 25 的记录
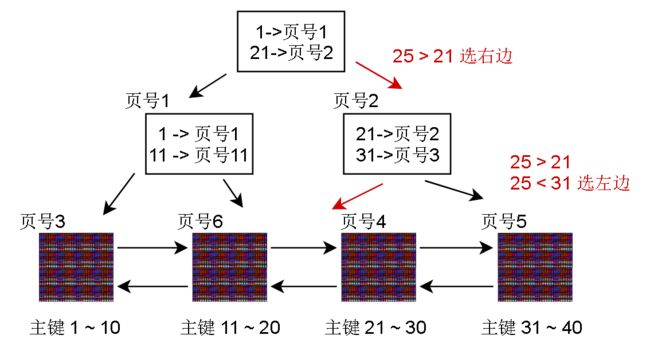
找到数据页4,但是要怎么找记录呢?innodb会把这片数据页加载入内存,根据这个数据页的page Directory进行二分查找
Page Directory 其实只是一堆偏移量而已
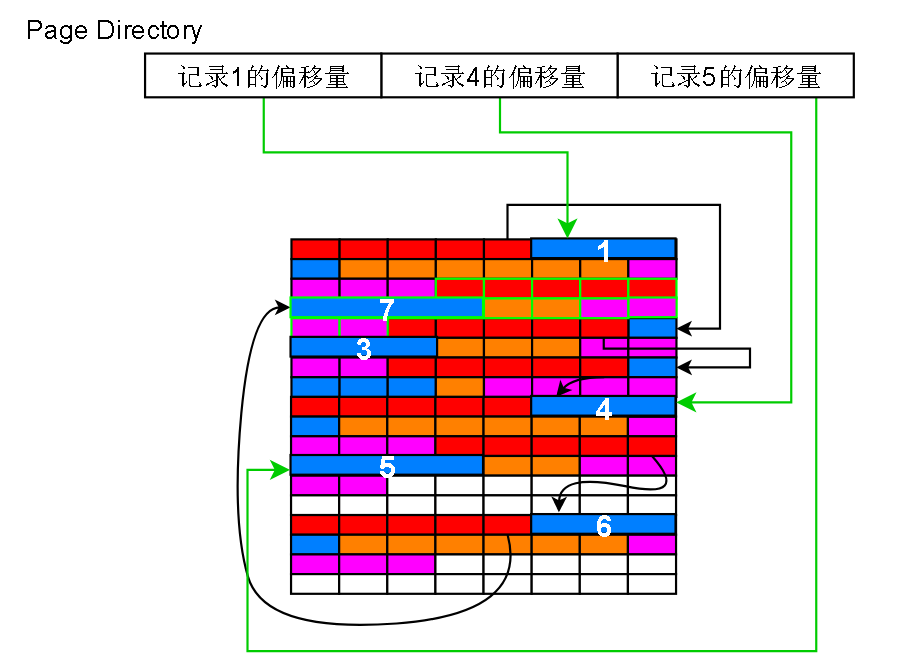
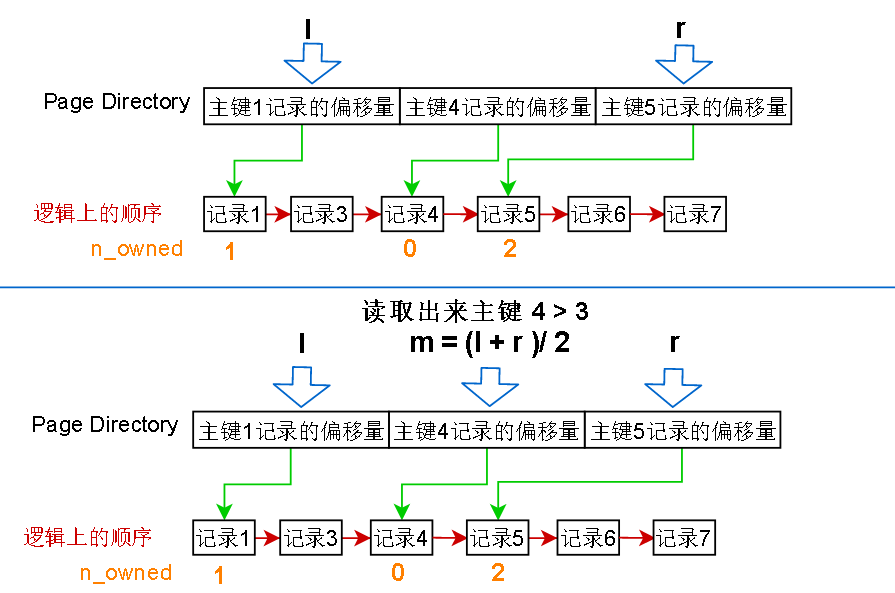
在上面的页中,如果我要查找主键 = 3 的记录,那么先设置左指针 l = 第一个page directory 项的位置,右指针 r = 最后一个 page directory项的位置
根据二分查找,求出中间的位置,然后把中间的 page directory 项读出来,发现记录的主键是4,比要找的 3 大,那就缩小范围,把右指针 r 设置成刚才
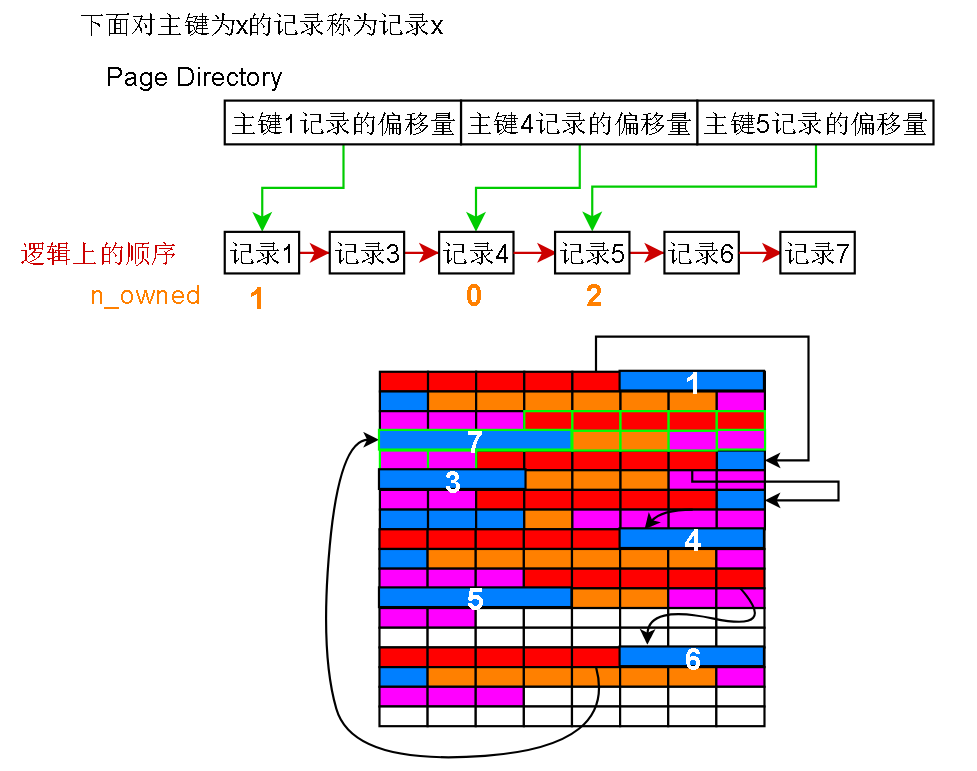
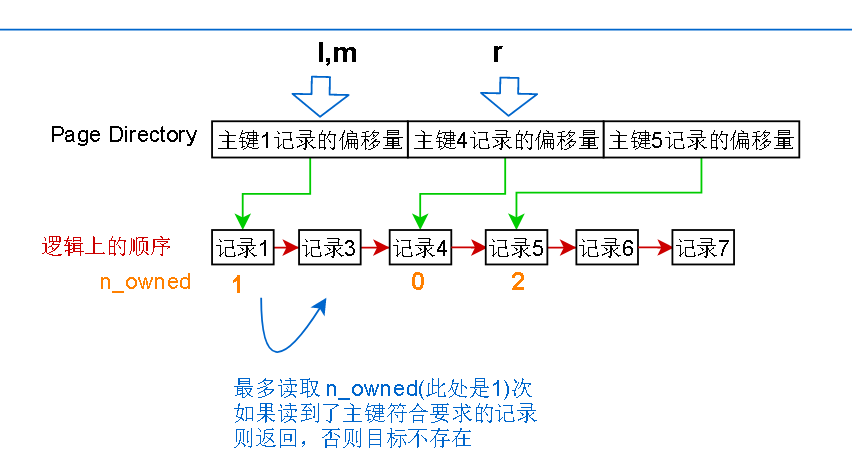
算出来的中间项的位置,l 和 r 之间已经没有没有page director的项 了,所以从 l 指针指向的记录开始,一条条往后读,最多读取其实记录的n_owned次
读不到就表示目标不存在,n_owned其实表示的就是当前记录到下一个Page Directory有指向的记录之间有多少条记录,这些记录的查询都是归当前记录管


所以根据索引只能查到数据页,把页读进内存在进行二分查找,因为是在内存中操作,相比于索引查找时的磁盘操作,可以忽略