觉得有帮助的别忘了关注一下知识图谱与大数据公众号
开始
在上一文中,我们保存了百度云盘的地址和提取码,但是这种分享链接很容易被屏蔽,最好的做法就是保存资源到自己的网盘,不过采集的链接有上万个,人肉保存并不现实,所以本文尝试了批量保存资源,如您还没看过上文,这里可以跳转。
爬虫学习3:搭建自己的电影资源网保姆式教学
观察请求
以下面资源链接为例:
https://pan.baidu.com/s/1tHSxZQueF-Wsa2T0NlT3vQ
在浏览器中输入以上链接,会自动跳转到https://pan.baidu.com/share/init?surl=tHSxZQueF-Wsa2T0NlT3vQ,
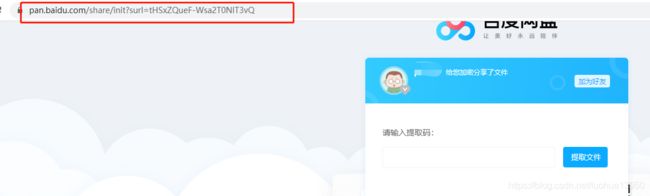
输入正确提取码后发现直接跳转到资源保存页面了,F12 NETWORK里也看不到此请求的返回值,这时候只能使用Fiddler才能抓到包了。
Fiddler抓包
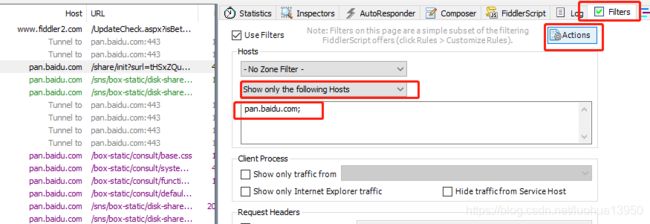
打开Fiddler,为了不让其它各类请求影响到我们,首先进行简单设置,以此来显示我们想要的请求,点击Filters 进行如下设置,最后点击Actions里的Run Filterset now,就只会显示pan.baidu.com域名的请求:
测试post数据
为了得到点击提取文件按钮时发送的请求和post的数据,先尝试输入一个错误的提取码123,查看请求:
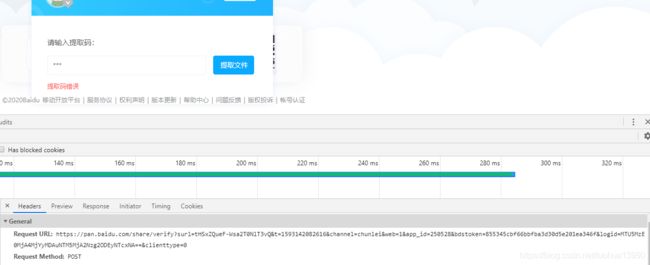
https://pan.baidu.com/share/verify?surl=tHSxZQueF-Wsa2T0NlT3vQ&t=1593142082616&channel=chunlei&web=1&app_id=250528&bdstoken=855345cbf66bbfba3d30d5e201ea346f&logid=MTU5MzE0MjA4MjYyMDAuNTM5MjA2Nzg2ODEyNTcxNA==&clienttype=0
看来上面这个url就提取数据的请求,接下来具体看一下都提交了哪些数据:
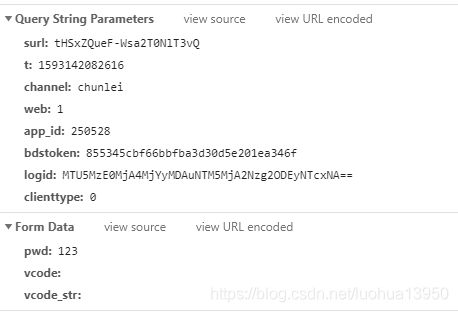
Form Data中的pwd就是刚才输入的错误提取码,而其它两个参数vcode和vcode_str在没有验证码的情况下也不用管,再看看Query String中的参数,为了测试这些参数有哪些是变化的,我挑选了一些资源链接去尝试,具体过程就省略了,总结如下:
| Query String参数 | 是否变化 |
|---|---|
| surl | 即资源链接中的最后部分,可直接获取 |
| t | 时间戳,可直接获取 |
| channel | 固定 |
| web | 固定 |
| app_id | 固定 |
| bdstoken | 固定 |
| logid | 变化 |
| clienttype | 固定 |
| Form Data参数 | 是否变化 |
|---|---|
| pwd | 即提取码 |
| vcode | 无 |
| vcode_str | 无 |
从上面表格来看,需要手动获取的就是logid,稍微有点经验的话应该都能想到这会不会是js动态生成的,抱着这个心态来到sources标签下,搜索logid关键字,果不其然,有个JS文件里有这个参数,直接定位到相应的行数:
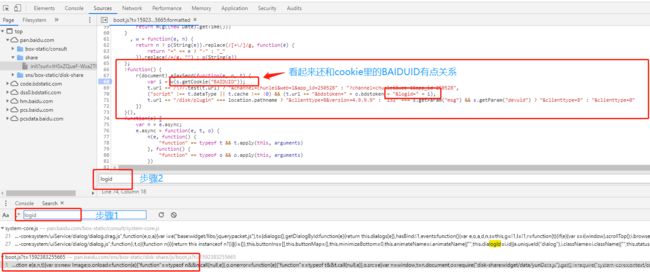
直接在68行打一个断点,查看运行状态:
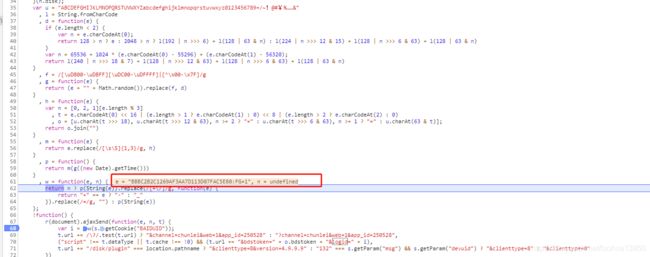
细心的同学一个很快就能发现上图红框里的值就是第一次请求https://pan.baidu.com/share/init?surl=tHSxZQueF-Wsa2T0NlT3vQ cookies里的BAIDUID的值,logid 就是通过上面一些js代码中的一些算法得到的,cookies如下:
BIDUPSID=EC39F255CF7B146E8ADD4FA37DB16739;BAIDUID=BBBC2B2C1269AF3AA7D113D07FAC5E80:FG=1; PSTM=1587390447; PANWEB=1; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; BDCLND=C4jsJ4aHacfrqq02TYbUOKGFFDefnJAMNmU%2BI3v5FNM%3D;
水平有限,没办法将这段js改写为python,不过好在python提供了一个执行js代码的库pyexecjs,该库运行于Nodejs环境,首先要保证你的机器安装了Nodejs:
pip install pyexecjs
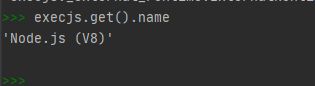
下图即代表安装正确了,execjs可以正常使用
将js代码稍微修改一下,保存为yunpan.js:
var u = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/~!@#¥%……&"
, l = String.fromCharCode
, d = function (e) {
if (e.length < 2) {
var n = e.charCodeAt(0);
return 128 > n ? e : 2048 > n ? l(192 | n >>> 6) + l(128 | 63 & n) : l(224 | n >>> 12 & 15) + l(128 | n >>> 6 & 63) + l(128 | 63 & n)
}
var n = 65536 + 1024 * (e.charCodeAt(0) - 55296) + (e.charCodeAt(1) - 56320);
return l(240 | n >>> 18 & 7) + l(128 | n >>> 12 & 63) + l(128 | n >>> 6 & 63) + l(128 | 63 & n)
}
, f = /[\uD800-\uDBFF][\uDC00-\uDFFFF]|[^\x00-\x7F]/g
, g = function (e) {
return (e + "" + Math.random()).replace(f, d)
}
, h = function (e) {
var n = [0, 2, 1][e.length % 3]
, t = e.charCodeAt(0) << 16 | (e.length > 1 ? e.charCodeAt(1) : 0) << 8 | (e.length > 2 ? e.charCodeAt(2) : 0)
,
o = [u.charAt(t >>> 18), u.charAt(t >>> 12 & 63), n >= 2 ? "=" : u.charAt(t >>> 6 & 63), n >= 1 ? "=" : u.charAt(63 & t)];
return o.join("")
}
, m = function (e) {
return e.replace(/[\s\S]{1,3}/g, h)
}
, p = function () {
return m(g((new Date).getTime()))
}
, w = function (e, n) {
return n ? p(String(e)).replace(/[+\/]/g, function (e) {
return "+" == e ? "-" : "_"
}).replace(/=/g, "") : p(String(e))
};
#获取logid函数,自己添加的
function getlogid(e) {
var logid = w(e)
return logid
}
使用execjs执行一下
def get_logid(self, bid):
with open('..//js//yunpan.js', encoding='utf-8') as f:
yunpan = f.read()
js = execjs.compile(yunpan)
logid = js.call('getlogid', bid)
return logid

得到所有的变化参数后就可以提交数据了:
requests.packages.urllib3.disable_warnings()
class YunPan(SpiderBase):
def __init__(self):
super(YunPan, self).__init__()
self.index_url = "https://pan.baidu.com/s/1wy0LC4O6iY7l9M6RD25k6w"
#提交提取码的链接
self.submmit_url = "https://pan.baidu.com/share/verify?surl={}&t={}&channel=chunlei&web=1&app_id=250528&bdstoken=7a8e1e34b454fd27de65b7662f67c2fa&logid={}==&clienttype=0"
#保存链接
self.save_url = "https://pan.baidu.com/share/transfer?shareid={}&from={}&ondup=newcopy&async=1&channel=chunlei&web=1&app_id=250528&bdstoken=7a8e1e34b454fd27de65b7662f67c2fa&logid={}&clienttype=0"
self.pan_code = "Love"
def get_logid(self, bid):
with open('..//js//yunpan.js', encoding='utf-8') as f:
yunpan = f.read()
js = execjs.compile(yunpan)
logid = js.call('getlogid', bid)
return logid
def init(self):
ua = random.choice(self.ua)
header = {
"User-Agent": ua
}
resp = self.download_page(self.index_url, headers=header, verify=False)
resp.encoding = resp.apparent_encoding
bid = resp.cookies.get("BAIDUID", "")
logid = self.get_logid(bid)
key = self.index_url.split("surl=")[-1]
key = self.index_url.split("/")[-1][1:]
return bid, logid, key
def post_pan_code(self):
ua = random.choice(self.ua)
# 跳转
data = {
"pwd": "Love",
"vscode": "",
"vscode_str": "",
}
bid, logid, key = self.init()
url = self.submmit_url.format(key, timestep, logid, )
resp = self.download_page(url, method="post", headers=self.headers(), data=data, verify=False)
res = json.loads(resp.text)
print(res)
return res
通过Fiddler抓包发现返回的res为下,errno为0即代表提交成功:
{"errno":0,"err_msg":"","request_id":8738382064533520558,"randsk":"g2VwUSYs1KSuOMh9%2FQDVUUwc7ICFq4CZNmU%2BI3v5FNM%3D"}
留意上面的randsk。
如果你是用浏览器抓包就会发现输对提取码点击按钮后请求会全部刷新一次,就不能确认到底是哪个请求跳转到资源页面的,只能使用Fiddler才能抓到POST成功后的请求,经过测试,发现POST数据后又再次请求了https://pan.baidu.com/s/1wy0LC4O6iY7l9M6RD25k6w这个链接,没错,就是上面一开始请求的链接,区别就是这次请求cookie中携带了刚才返回的randsk的值。所以再次请求时添加上randsk:
res = self.post_pan_code()
randsk = res.get("randsk", "")
c = requests.cookies.RequestsCookieJar()
c.set("BDCLND", randsk)
self.session.cookies.update(c)
#之所以加 verify=False是因为https请求有时候会报OPEN SSL的异常错误
#最好在导库时加上requests.packages.urllib3.disable_warnings()
resp = self.download_page(self.index_url, headers=headers, verify=False)
#保证没有乱码
resp.encoding = resp.apparent_encoding
#这时候resp里已经时资源页面的内容了
保存资源
抓包分析
抓包保存资源链接发现为:
#保存链接
https://pan.baidu.com/share/transfer?shareid=4180912663&from=2693937402&ondup=newcopy&async=1&channel=chunlei&web=1&app_id=250528&bdstoken=7a8e1e34b454fd27de65b7662f67c2fa&logid=MTU5MzE4MTYzNDY0NDAuOTE1MzE0NDI5MzI1NTY4OA==&clienttype=0"
Query String和Form Data为:
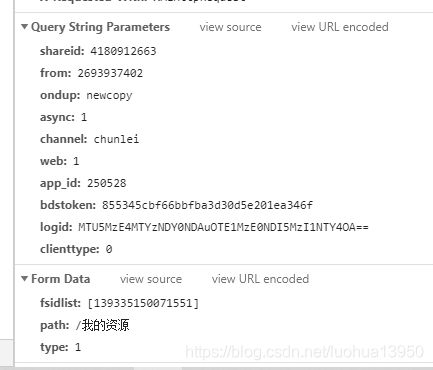
Query String大部分参数都提到过,可以参考上面,这里出现了新的两个参数shareid和from,经过测试除了这两个参数和上文中logid,其它参数均为固定。
| Form Data参数 | 是否变化 |
|---|---|
| fsidlist | 变化 |
| path | 你自己选择保存的路径,约等于固定 |
| type | 固定 |
到这里又稍微被shareid和from、fsidlist三个参数卡住了,在页面中搜索这三个参数也没有结果,在source中搜索了一下,倒是又一个shareid,但是貌似也关系不大,折腾了一会就想到既然参数名搜不到,那我搜一下参数值试试?,果然在资源页面中搜到了三个参数的值(即https://pan.baidu.com/s/1wy0LC4O6iY7l9M6RD25k6w这页面),如下图:
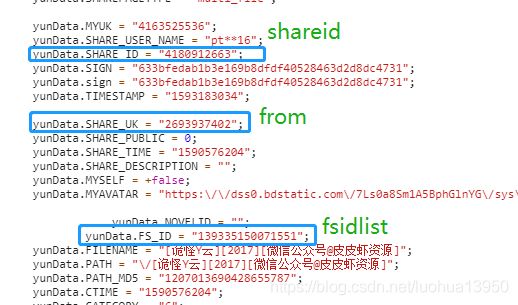
正则表达式即可提取出三个值。
def extract_data(self, html):
#提取三个值
import re
share_id_pattern = 'yunData.SHARE_ID = "(.*?)";'
from_pattern = 'yunData.SHARE_UK = "(.*?)";'
fsid_pattern = 'yunData.FS_ID = "(.*?)";'
try:
share_id = re.findall(share_id_pattern, html, re.S)[0]
_from = re.findall(from_pattern, html, re.S)[0]
fsid = re.findall(fsid_pattern, html, re.S)[0]
except IndexError:
print("提取shareid、from、fsid失败")
return share_id, _from, fsid
转存
转存时候注意cookie里要携带BDUSS和STOKEN,这两个参数在资源页面的cookies里,且都为固定的,没有登录的话只有STOKEN,BDUSS的值要在登录状态下才能看到,下图时登录后的cookie:
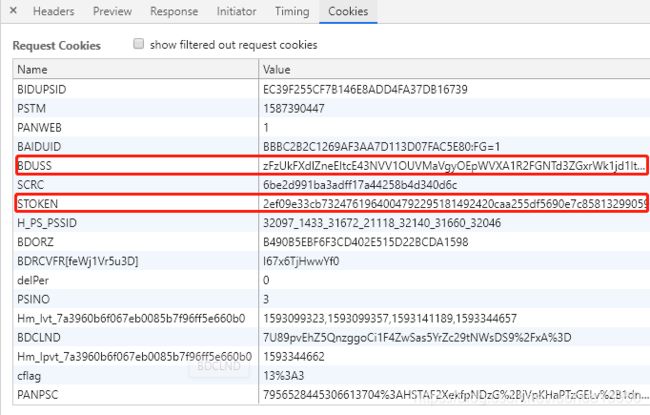
代码如下:
def transfer_resource(self,share_id, from_id, fsid,logid,randmsk):
url = self.save_url.format(share_id,from_id,logid)
data = {
"fsidlist":"["+fsid+"]",
"path":"/我的资源",
"type":'1'
}
BDUSS="你的cookies里的BDUSS"
self.session.cookies.set("STOKEN","STOKEN",domain=".baidu.com")
self.session.cookies.set("BDUSS",BDUSS,domain=".baidu.com")
resp = self.download_page(url,method="post",headers=self.headers(),data=data,verify=False)
#这里返回resp errno为0即代表成功
完结,撒花
到这里就结束了,本文讲解了如何使用python转存百度云盘资源。
更多内容请关注知识图谱与大数据公众号,获取更多内容,当然不关注也无所谓。