本系列文章将介绍用户从 Spring Cloud,Dubbo 等传统微服务框架迁移到 Istio 服务网格时的一些经验,以及在使用 Istio 过程中可能遇到的一些常见问题的解决方法。
失败的 Eureka 心跳通知
在上一篇文章中,我们介绍了 Headless Service 和普通 Service 的区别。由于 Headless Service 的特殊性,在 Istio 下发给 Envoy Sidecar 的配置中,此类服务的配置参数和其他服务的参数有所不同。除了我们上次遇到的 mTLS 故障之外,这些差异可能还会导致应用出现一些其他意想不到的情况。
这次遇到的问题现象是:在 Spring Cloud 应用迁移到 Istio 中后,服务提供者向 Eureka Server 发送心跳失败。
备注:Eureka Server 采用心跳机制来判定服务的健康状态。服务提供者在启动后,周期性(默认30秒)向Eureka Server发送心跳,以证明当前服务是可用状态。Eureka Server在一定的时间(默认90秒)未收到客户端的心跳,则认为服务宕机,注销该实例。
查看应用程序日志,可以看到 Eureka 客户端发送心跳失败的相关日志信息。
2020-09-24 13:32:46.533 ERROR 1 --- [tbeatExecutor-0] com.netflix.discovery.DiscoveryClient : DiscoveryClient_EUREKA-TEST-CLIENT/eureka-client-544b94f967-gcx2f:eureka-test-client - was unable to send heartbeat!
com.netflix.discovery.shared.transport.TransportException: Cannot execute request on any known server
at com.netflix.discovery.shared.transport.decorator.RetryableEurekaHttpClient.execute(RetryableEurekaHttpClient.java:112) ~[eureka-client-1.9.13.jar!/:1.9.13]
at com.netflix.discovery.shared.transport.decorator.EurekaHttpClientDecorator.sendHeartBeat(EurekaHttpClientDecorator.java:89) ~[eureka-client-1.9.13.jar!/:1.9.13]
at com.netflix.discovery.shared.transport.decorator.EurekaHttpClientDecorator$3.execute(EurekaHttpClientDecorator.java:92) ~[eureka-client-1.9.13.jar!/:1.9.13]
at com.netflix.discovery.shared.transport.decorator.SessionedEurekaHttpClient.execute(SessionedEurekaHttpClient.java:77) ~[eureka-client-1.9.13.jar!/:1.9.13]
at com.netflix.discovery.shared.transport.decorator.EurekaHttpClientDecorator.sendHeartBeat(EurekaHttpClientDecorator.java:89) ~[eureka-client-1.9.13.jar!/:1.9.13]
at com.netflix.discovery.DiscoveryClient.renew(DiscoveryClient.java:864) ~[eureka-client-1.9.13.jar!/:1.9.13]
at com.netflix.discovery.DiscoveryClient$HeartbeatThread.run(DiscoveryClient.java:1423) ~[eureka-client-1.9.13.jar!/:1.9.13]
at java.base/java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:515) ~[na:na]
at java.base/java.util.concurrent.FutureTask.run(FutureTask.java:264) ~[na:na]
at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1130) ~[na:na]
at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:630) ~[na:na]
at java.base/java.lang.Thread.run(Thread.java:832) ~[na:na]
过期的 IP 地址
对于请求失败类的故障,我们首先可以通过 Envoy 的访问日志查看失败原因。通过下面的命令查看客户端 Envoy Sidecar 的日志:
k logs -f eureka-client-66f748f84f-vvvmz -c eureka-client -n eureka
从 Envoy 日志中可以查看到客户端通过 HTTP PUT 向服务器发出的心跳请求。该请求的 Response 状态码为 "UF,URX",表示其 Upstream Failure,即连接上游服务失败。在日志中还可以看到,在连接失败后,Envoy 向客户端应用返回了一个 "503" HTTP 错误码。
[2020-09-24T13:31:37.980Z] "PUT /eureka/apps/EUREKA-TEST-CLIENT/eureka-client-544b94f967-gcx2f:eureka-test-client?status=UP&lastDirtyTimestamp=1600954114925 HTTP/1.1" 503 UF,URX "-" "-" 0 91 3037 - "-" "Java-EurekaClient/v1.9.13" "1cd54507-3f93-4ff3-a93e-35ead11da70f" "eureka-server:8761" "172.16.0.198:8761" outbound|8761||eureka-server.eureka.svc.cluster.local - 172.16.0.198:8761 172.16.0.169:53890 - default
从日志中可以看到访问的 Upstream Cluster 是 outbound|8761||eureka-server.eureka.svc.cluster.local ,Envoy 将该请求转发到了 IP地址 为 172.16.0.198 的 Upstream Host。
查看集群中部署的服务,可以看到 eureka-server 是一个 Headless Service。
HUABINGZHAO-MB0:eureka-istio-test huabingzhao$ k get svc -n eureka -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
eureka-server ClusterIP None 8761/TCP 17m app=eureka-server
在本系列的上一篇文章『Istio 运维实战系列(2):让人头大的『无头服务』-上』中,我们了解到 Headless Service 并没有 Cluster IP,DNS 会直接将 Service 名称解析到 Service 后端的多个 Pod IP 上。Envoy 日志中显示连接 Eureka Server地址 172.16.0.198 失败,我们来看看这个 IP 来自哪一个 Eureka Server 的 Pod 。
HUABINGZHAO-MB0:eureka-istio-test huabingzhao$ k get pod -n eureka -o wide | grep eureka-server
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
eureka-server-0 1/1 Running 0 6h55m 172.16.0.59 10.0.0.15
eureka-server-1 1/1 Running 0 6m1s 172.16.0.200 10.0.0.7
eureka-server-2 1/1 Running 0 6h56m 172.16.1.3 10.0.0.14
从上面的命令输出中可以看到 Eureka 集群中有三个服务器,但没有哪一个服务器的 Pod IP 是 Envoy 日志中显示的 172.16.0.198。进一步分析发现 eureka-server-1 Pod 的启动时间比客户端的启动时间晚很多,初步怀疑 Envoy 采用了一个已经被销毁的 Eureka Server 的 IP 进行访问,导致访问失败。
通过查看 Envoy dump 文件中 outbound|8761||eureka-server.eureka.svc.cluster.local 的相关配置,进一步加深了我对此的怀疑。从下面的 yaml 片段中可以看到该 Cluster 的类型为 “ORIGINAL_DST”。
{
"version_info": "2020-09-23T03:57:03Z/27",
"cluster": {
"@type": "type.googleapis.com/envoy.api.v2.Cluster",
"name": "outbound|8761||eureka-server.eureka.svc.cluster.local",
"type": "ORIGINAL_DST", # 该选项表明 Enovy 在转发请求时会直接采用 downstream 原始请求中的地址。
"connect_timeout": "1s",
"lb_policy": "CLUSTER_PROVIDED",
...
}
根据 Envoy 的文档说明,“ORIGINAL_DST” 的解释为:
In these cases requests routed to an original destination cluster are forwarded to upstream hosts as addressed by the redirection metadata, without any explicit host configuration or upstream host discovery.
即对于“ORIGINAL_DST” 类型的 Cluster,Envoy 在转发请求时会直接采用 downstream 请求中的原始目的地 IP 地址,而不会采用服务发现机制。Istio 中 Envoy Sidecar 的该处理方式和 K8s 对 Headless Service 的处理是类似的,即由客户端根据 DNS 直接选择一个后端的 Pod IP,不会采用负载均衡算法对客户端的请求进行重定向分发。但让人疑惑的是:为什么客户端通过 DNS 查询得到的 Pod 地址 172.16.0.198 访问失败了呢?这是由于客户端查询 DNS 时得到的地址在访问期间已经不存在了。下图解释了导致该问题的原因:
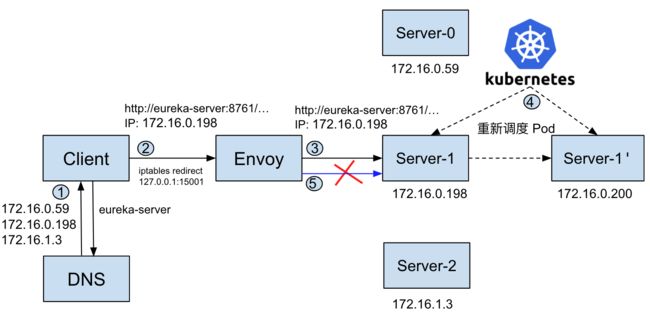
- Client 查询 DNS 得到 eureka-server 的三个IP地址。
- Client 选择 Server-1 的 IP 172.16.0.198 发起连接请求,请求被 iptables rules 拦截并重定向到了客户端 Pod 中 Envoy 的 VirtualInbound 端口 15001。
- 在收到 Client 的连接请求后,根据 Cluster 的配置,Envoy 采用请求中的原始目的地址 172.16.0.198 连接 Server-1,此时该 IP 对应的 Pod 是存在的,因此 Envoy 到 Server-1 的链接创建成功,Client 和 Envoy 之间的链接也会建立成功。Client 在创建链接时采用了 HTTP Keep Alive 选项,因此 Client 会一直保持该链接,并通过该链接以 30 秒间隔持续发送 HTTP PUT 服务心跳通知。
- 由于某些原因,该 Server-1 Pod 被 K8s 重建为 Server-1ꞌ,IP 发生了变化。
- 当 Server-1 的 IP 变化后,Envoy 并不会立即主动断开和 Client 端的链接。此时从 Client 的角度来看,到 172.16.0.198 的 TCP 链接依然是正常的,因此 Client 会继续使用该链接发送 HTTP 请求。同时由于 Cluster 类型为 “ORIGINAL_DST” ,Envoy 会继续尝试连接 Client 请求中的原始目的地址 172.16.0.198,如图中蓝色箭头所示。但是由于该 IP 上的 Pod 已经被销毁,Envoy 会连接失败,并在失败后向 Client 端返回一个这样的错误信息:“upstream connect error or disconnect/reset before headers. reset reason: connection failure HTTP/1.1 503” 。如果 Client 在收到该错误后不立即断开并重建链接,那么直到该链接超时之前,Client 都不会重新查询 DNS 获取到 Pod 重建后的正确地址。
为 Headless Service 启用 EDS
从前面的分析中我们已经知道出错的原因是由于客户端 HTTP 长链接中的 IP 地址过期导致的。那么一个最直接的想法就是让 Envoy 采用正确的 IP 地址去连接 Upstream Host。在不修改客户端代码,不重建客户端链接的情况下,如何才能实现呢?
如果对比一个其他服务的 Cluster 配置,可以看到正常情况下,Istio 下发的配置中,Cluster 类型为 EDS (Endopoint Discovery Service),如下面的 yaml 片段所示:
{
"version_info": "2020-09-23T03:02:01Z/2",
"cluster": {
"@type": "type.googleapis.com/envoy.config.cluster.v3.Cluster",
"name": "outbound|8080||http-server.default.svc.cluster.local",
"type": "EDS", # 普通服务采用 EDS 服务发现,根据 LB 算法从 EDS 下发的 endpoint 中选择一个进行连接
"eds_cluster_config": {
"eds_config": {
"ads": {},
"resource_api_version": "V3"
},
"service_name": "outbound|8080||http-server.default.svc.cluster.local"
},
...
}
在采用 EDS 的情况下,Envoy 会通过 EDS 获取到该 Cluster 中所有可用的 Endpoint,并根据负载均衡算法(缺省为 Round Robin)将 Downstream 发来的请求发送到不同的 Endpoint。因此只要把 Cluster 类型改为 EDS,Envoy 在转发请求时就不会再采用请求中错误的原始 IP 地址,而会采用 EDS 自动发现到的 Endpoint 地址。采用 EDS 的情况下,本例的中的访问流程如下图所示:
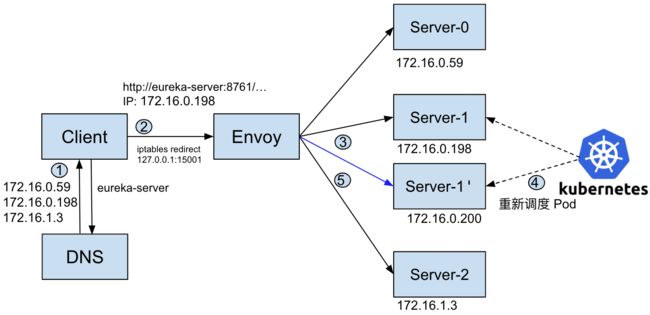
通过查阅 Istio 源码,可以发现 Istio 对于 Headless Service 缺省采用了 "ORIGINAL_DST" 类型的 Cluster,但我们也可以通过设置一个 Istiod 的环境变量 PILOT_ENABLE_EDS_FOR_HEADLESS_SERVICES 为 Headless Service 强制启用 EDS 。
func convertResolution(proxy *model.Proxy, service *model.Service) cluster.Cluster_DiscoveryType {
switch service.Resolution {
case model.ClientSideLB:
return cluster.Cluster_EDS
case model.DNSLB:
return cluster.Cluster_STRICT_DNS
case model.Passthrough: // Headless Service 的取值为 model.Passthrough
if proxy.Type == model.SidecarProxy {
// 对于 Sidecar Proxy,如果 PILOT_ENABLE_EDS_FOR_HEADLESS_SERVICES 的值设为 True,则启用 EDS,否则采用 ORIGINAL_DST
if service.Attributes.ServiceRegistry == string(serviceregistry.Kubernetes) && features.EnableEDSForHeadless {
return cluster.Cluster_EDS
}
return cluster.Cluster_ORIGINAL_DST
}
return cluster.Cluster_EDS
default:
return cluster.Cluster_EDS
}
}
在将 Istiod 环境变量 PILOT_ENABLE_EDS_FOR_HEADLESS_SERVICES 设置为 true 后,再查看 Envoy 的日志,可以看到虽然请求原始 IP 地址还是 172.16.0.198,但 Envoy 已经把请求分发到了实际可用的三个 Server 的 IP 上。
[2020-09-24T13:35:28.790Z] "PUT /eureka/apps/EUREKA-TEST-CLIENT/eureka-client-544b94f967-gcx2f:eureka-test-client?status=UP&lastDirtyTimestamp=1600954114925 HTTP/1.1" 200 - "-" "-" 0 0 4 4 "-" "Java-EurekaClient/v1.9.13" "d98fd3ab-778d-42d4-a361-d27c2491eff0" "eureka-server:8761" "172.16.1.3:8761" outbound|8761||eureka-server.eureka.svc.cluster.local 172.16.0.169:39934 172.16.0.198:8761 172.16.0.169:53890 - default
[2020-09-24T13:35:58.797Z] "PUT /eureka/apps/EUREKA-TEST-CLIENT/eureka-client-544b94f967-gcx2f:eureka-test-client?status=UP&lastDirtyTimestamp=1600954114925 HTTP/1.1" 200 - "-" "-" 0 0 1 1 "-" "Java-EurekaClient/v1.9.13" "7799a9a0-06a6-44bc-99f1-a928d8576b7c" "eureka-server:8761" "172.16.0.59:8761" outbound|8761||eureka-server.eureka.svc.cluster.local 172.16.0.169:45582 172.16.0.198:8761 172.16.0.169:53890 - default
[2020-09-24T13:36:28.801Z] "PUT /eureka/apps/EUREKA-TEST-CLIENT/eureka-client-544b94f967-gcx2f:eureka-test-client?status=UP&lastDirtyTimestamp=1600954114925 HTTP/1.1" 200 - "-" "-" 0 0 2 1 "-" "Java-EurekaClient/v1.9.13" "aefb383f-a86d-4c96-845c-99d6927c722e" "eureka-server:8761" "172.16.0.200:8761" outbound|8761||eureka-server.eureka.svc.cluster.local 172.16.0.169:60794 172.16.0.198:8761 172.16.0.169:53890 - default
神秘消失的服务
在将 Eureka Server Cluster 的类型从 ORIGINAL_DST 改为 EDS 之后,之前心跳失败的服务正常了。但过了一段时间后,发现原来 Eureka 中注册的部分服务下线,导致服务之间无法正常访问。查询 Eureka Server 的日志,发现日志中有如下的错误:
2020-09-24 14:07:35.511 WARN 6 --- [eureka-server-3] c.netflix.eureka.cluster.PeerEurekaNode : EUREKA-SERVER-2/eureka-server-2.eureka-server.eureka.svc.cluster.local:eureka-server-2:8761:[email protected]: missing entry.
2020-09-24 14:07:35.511 WARN 6 --- [eureka-server-3] c.netflix.eureka.cluster.PeerEurekaNode : EUREKA-SERVER-2/eureka-server-2.eureka-server.eureka.svc.cluster.local:eureka-server-2:8761:[email protected]: cannot find instance
从日志中我们可以看到多个 Eureka Server 之间的数据同步发生了错误。当部署为集群模式时,Eureka 集群中的多个实例之间会进行数据同步,本例中的 Eureka 集群中有三个实例,这些实例之间的数据同步如下图所示:
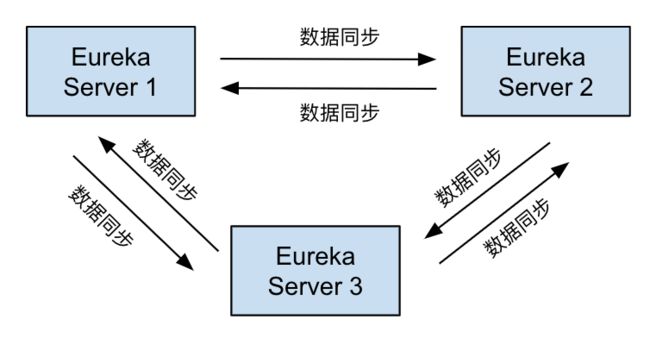
当改用 EDS 之后,当集群中的每一个 Eureka Server 向集群中的其他 Eureka Server 发起数据同步时,这些请求被请求方 Pod 中的 Envoy Sidecar 采用 Round Robin 进行了随机分发,导致同步消息发生了紊乱,集群中每个服务器中的服务注册消息不一致,导致某些服务被误判下线。该故障现象比较随机,经过多次测试,我们发现在 Eureka 中注册的服务较多时更容易出现改故障,当只有少量服务时不容易复现。
找到原因后,要解决该问题就很简单了,我们可以通过将 Eureka Server 的 Sidecar Injection 设置为 false 来规避该问题,如下面的 yaml 片段所示:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: eureka-server
spec:
selector:
matchLabels:
app: eureka-server
serviceName: "eureka-server"
replicas: 3
template:
metadata:
labels:
app: eureka-server
annotations:
sidecar.istio.io/inject: "false" # 不为 eureka-server pod 注入 Envoy Siedecar
spec:
containers:
- name: eureka-server
image: zhaohuabing/eureka-test-service:latest
ports:
- containerPort: 8761
name: http
反思
对于 Headless Service,Istio 缺省采用 “ORIGINAL_DST” 类型的 Cluster,要求 Envoy Sidecar 在转发时采用请求原始目的 IP 地址的行为其实是合理的。如同我们在本系列的上一篇文章『Istio 运维实战系列(2):让人头大的『无头服务』-上』所介绍的,Headless Service 一般用于定义有状态的服务。对于有状态的服务,需要由客户端根据应用特定的算法来自行决定访问哪一个后端 Pod,因此不应该在这些 Pod 前加一个负载均衡器。
在本例中,由于 Eureka 集群中各个节点之间会对收到的客户端服务心跳通知进行同步,因此对于客户端来说,将心跳通知发送到哪一个 Eureka 节点并不重要,我们可以认为 Eureka 集群对于外部客户端而言是无状态的。因此设置 PILOT_ENABLE_EDS_FOR_HEADLESS_SERVICES 环境变量,在客户端的 Envoy Sidecar 中对客户端发往 Eureka Server 的请求进行负载均衡是没有问题的。但是由于 Eureka 集群内部的各个节点之间的是有状态的,修改后影响了集群中各个 Eureka 节点之间的数据同步,导致了后面部分服务错误下线的问题。对于引发的该问题,我们通过去掉 Eureka Server 的 Sidecar 注入来进行了规避。
对于该问题,更合理的处理方法是 Envoy Sidecar 在尝试连接 Upstream Host 失败一定次数后主动断开和客户端侧的链接,由客户端重新查询 DNS,获取正确的 Pod IP 来创建新的链接。经过测试验证,Istio 1.6 及之后的版本中,Envoy 在 Upstream 链接断开后会主动断开和 Downstream 的长链接,建议尽快升级到 1.6 版本,以彻底解决本问题。也可以直接采用腾讯云上的云原生 Service Mesh 服务 TCM(Tencent Cloud Mesh),为微服务应用快速引入 Service Mesh 的流量管理和服务治理能力,而无需再关注 Service Mesh 基础设施自身的安装、维护、升级等事项。
参考文档
- All about ISTIO-PROXY 5xx Issues
- Service Discovery: Eureka Server
- Istio 运维实战系列(2):让人头大的『无头服务』-上
- Eureka 心跳通知问题测试源码
【腾讯云原生】云说新品、云研新术、云游新活、云赏资讯,扫码关注同名公众号,及时获取更多干货!!
