EmberJs之Ember-Data
写在前面
最近比较忙,换了新工作还要学习很多全新的技术栈,并给自己找了很多借口来不去坚持写博客。常常具有讽刺意味的是,更多剩下的时间并没有利用而更多的是白白浪费,也许这就是青春吧,挥霍吧,这不是我想要的,既然这样,我还要继续写下去,坚持把博客做好,争取进前100博客,在此谨记。
2015年5月7日深夜,于电脑旁。
文章索引
什么是Ember-Data?
对于简单的应用来说,可以通过jQuery来从服务器加载JSON数据,并将这些JSON数据对象作为模型。
但是,使用一个模型库来管理查询、更改和将更改保存回服务器,将会大大的简化代码,同时也能提升应用的健壮性和性能,这便产生了Ember-Data数据模型。
Ember-Data不需要进行任何配置,就可以实现通过服务端提供的RESTful JSON API加载和保存记录以及它们的管理关系,这些操作都遵从于特定的惯例。
如果需要将Ember.js应用与现有的、未遵从惯例的JSON APIs进行集成,Ember-Data也进行了充分的设计,通过简单的配置就可以使用服务端返回的数据。
Ember-Data同样适用于使用流式的API,例如socket.io、Firebase或WebSockets。通过建立一个与服务器端的Socket连接,在记录发生变化的时候,将这些变更推送到本地仓库中(Store)。
核心概念
仓库
仓库是应用存放记录的中心仓库。你可以认为仓库是应用的所有数据的缓存。应用的控制器和路由都可以访问这个共享的仓库;当它们需要显示或者修改一个记录时,首先就需要访问仓库。
DS.Store的实例会被自动创建,并且该实例被应用中所有的对象所共享。
可以使用该实例来获取记录,创建新的记录等。例如,需要在路由的model钩子中查找一个类型为App.Person,ID为1的记录:
App.IndexRoute = Ember.Route.extend({ model: function() { return this.store.find('person', 1); } });
模型
模型是一个类,它定义了需要呈现给用户的数据的属性和行为。任何用户期望在其离开应用然后再回到应用时能够看见的数据,都应该通过模型来表示。
例如,如果正在编写一个可以给饭店下单的Web应用,那么这个应用中应该包含Order、LineItem和MenuItem这样的模型。
获取订单就变得非常的容易:
| 1 |
this.store.find('order'); |
模型定义了服务器提供的数据的类型。例如Person模型可能包含一个名为firstName的字符串类型的属性,还有一个名为birthday的日期类型的属性。
| 1 2 3 4 |
App.Person = DS.Model.extend({ firstName: DS.attr('string'), birthday: DS.attr('date') }); |
模型也声明了它与其他对象的关系。例如,一个Order可以有许多LineItems,一个LineItem可以属于一个特定的Order。
| 1 2 3 4 5 6 7 |
App.Order = DS.Model.extend({ lineItems: DS.hasMany('lineItem') });
App.LineItem = DS.Model.extend({ order: DS.belongsTo('order') }); |
模型本身没有任何数据;模型只定义了其实例所具有的属性和行为,而这些实例被称为记录
记录
记录是模型的实例,包含了从服务器端加载而来的数据。应用本身也可以创建新的记录,以及将新记录保存到服务器端。
记录由以下两个属性来唯一标识:
- 模型类型
- 一个全局唯一的ID
例如,如果正在编写一个联系人管理的应用,有一个模型名为Person。那么在应用中,可能存在一个类型为Person,ID为1或者steve-buscemi的记录。
| 1 |
this.store.find('person', 1); // => { id: 1, name: 'steve-buscemi' } |
ID通常是在服务器端第一次创建记录的时候设定的,当然也可以在客户端生成ID。
适配器
适配器是一个了解特定的服务器后端的对象,主要负责将对记录的请求和变更转换为正确的向服务器端的请求调用。
例如,如果应用需要一个ID为1的person记录,那么Ember Data是如何加载这个对象的呢?是通过HTTP,还是Websocket?如果是通过HTTP,那么URL会是/person/1,还是/resources/people/1呢?
适配器负责处理所有类似的问题。无论何时,当应用需要从仓库中获取一个没有被缓存的记录时,应用就会访问适配器来获取这个记录。如果改变了一个记录并准备保存改变时,仓库会将记录传递给适配器,然后由适配器负责将数据发送给服务器端,并确认保存是否成功。
序列化
序列化主要负责将服务器端返回的原生JSON数据转化为记录对象。
JSON API可能将属性、关联关系用不同的方式表示。例如,一些属性名可能采用了驼峰式命名规则,而另一些又使用了下划线隔离的命名规则。关联关系的表示方法更是五花八门:它们有可能会是一个ID数组,一个内嵌的对象集合,也可能是作为外键。
当适配器从服务器端获取到一个特定记录的数据时,它将数据交给序列化对象,进而将数据转换为Ember Data期望的格式。
大部分人都需要使用序列化来完成JSON数据的转换,因为Ember Data将这些数据作为非透明的对象来处理,它们可能是以二进制数据被存储的,也可能是ArrayBuffer。
自动化缓存
仓库会自动缓存记录。如果一个记录已经被加载了,那么再次访问它的时候,会返回同一个对象实例。这样大大减少了与服务器端的往返通信,使得应用可以更快的为用户渲染所需的UI。
例如,应用第一次从仓库中获取一个ID为1的person记录时,将会从服务器端获取对象的数据。
但是,当应用再次需要ID为1的person记录时,仓库会发现这个记录已经获取到了,并且缓存了该记录。那么仓库就不会再向服务器端发送请求去获取记录的数据,而是直接返回第一次时候获取到并构造出来的记录。这个特性使得不论请求这个记录多少次,都会返回同一个记录对象,这也被称为Identity Map(标识符映射)。
使用标识符映射非常重要,因为这样确保了在一个UI上对一个记录的修改会自动传播到UI其他使用到该记录的UI。同时这意味着你无须手动去保持对象的同步,只需要使用ID来获取应用已经获取到的记录就可以了。
架构简介
应用第一次从仓库获取一个记录时,仓库会发现本地缓存并不存在一份被请求的记录的副本,这时会向适配器发请求。适配器将从持久层去获取记录;通常情况下,持久层都是一个HTTP服务,通过该服务可以获取到记录的一个JSON表示。
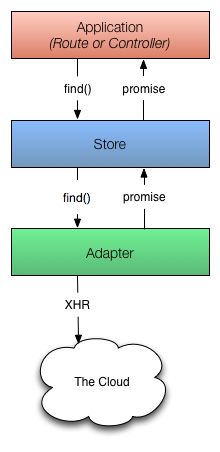
如上图所示,适配器有时不能立即返回请求的记录。这时适配器必须向服务器发起一个异步的请求,当请求完成加载后,才能通过返回的数据创建的记录。
由于存在这样的异步性,仓库会从find()方法立即返回一个承诺(promise)。另外,所有请求需要仓库与适配器发生交互的话,都会返回承诺。
一旦发给服务器端的请求返回被请求记录的JSON数据时,适配器会履行承诺,并将JSON传递给仓库。
仓库这时就获取到了JSON,并使用JSON数据完成记录的初始化,并使用新加载的记录来履行已经返回到应用的承诺。
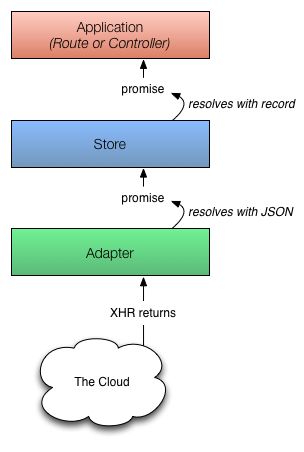
下面将介绍一下当仓库已经缓存了请求的记录时会发生什么。
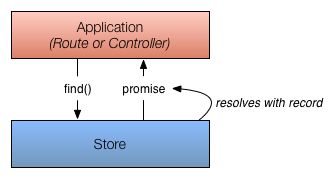
在这种情形下,仓库已经缓存了请求的记录,不过它也将返回一个承诺,不同的是,这个承诺将会立即使用缓存的记录来履行。此时,由于仓库已经有了一份拷贝,所以不需要向适配器去请求(没有与服务器发生交互)。