Tire Tree
本文讨论一棵最简单的trie树,基于英文26个字母组成的字符串,讨论插入字符串、判断前缀是否存在、查找字符串等基本操作;至于trie树的删除单个节点实在是少见,故在此不做详解。
l Trie原理
Trie的核心思想是空间换时间。利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。
l Trie性质
好多人说trie的根节点不包含任何字符信息,我所习惯的trie根节点却是包含信息的,而且认为这样也方便,下面说一下它的性质 (基于本文所讨论的简单trie树)
1. 字符的种数决定每个节点的出度,即branch数组(空间换时间思想)
2. branch数组的下标代表字符相对于a的相对位置
3. 采用标记的方法确定是否为字符串。
4. 插入、查找的复杂度均为O(len),len为字符串长度
l Trie的示意图
如图所示,该trie树存有abc、d、da、dda四个字符串,如果是字符串会在节点的尾部进行标记。没有后续字符的branch分支指向NULL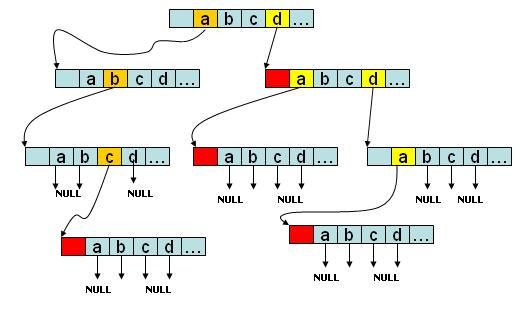
l TrieTrie的优点举例
已知n个由小写字母构成的平均长度为10的单词,判断其中是否存在某个串为另一个串的前缀子串。下面对比3种方法:
1. 最容易想到的:即从字符串集中从头往后搜,看每个字符串是否为字符串集中某个字符串的前缀,复杂度为O(n^2)。
2. 使用hash:我们用hash存下所有字符串的所有的前缀子串。建立存有子串hash的复杂度为O(n*len)。查询的复杂度为O(n)* O(1)= O(n)。
3. 使用trie:因为当查询如字符串 abc是否为某个字符串的前缀时,显然以b,c,d....等不是以a开头的字符串就不用查找了。所以建立trie的复杂度为O(n*len),而建立+ 查询在trie中是可以同时执行的,建立的过程也就可以成为查询的过程,hash就不能实现这个功能。所以总的复杂度为O(n*len),实际查询的复杂 度只是O(len)。
解释一下hash为什么不能将建立与查询同时执行,例如有串:911,911456输入,如果要同 时执行建立与查询,过程就是查询911,没有,然后存入9、91、911,查询911456,没有然后存入9114、91145、911456,而程序没 有记忆功能,并不知道911在输入数据中出现过。所以用hash必须先存入所有子串,然后for循环查询。
而trie树便可以,存入911后,已经记录911为出现的字符串,在存入911456的过程中就能发现而 输出答案;倒过来亦可以,先存入911456,在存入911时,当指针指向最后一个1时,程序会发现这个1已经存在,说明911必定是某个字符串的前缀, 该思想是我在做pku上的3630中发现的,详见本文配套的“入门练习”
|
|
10.3 Trie树
当关键码是可变长时,Trie树是一种特别有用的索引结构。
10.3.1 Trie树的定义
Trie树是一棵度 m ≥ 2 的树,它的每一层分支不是靠整个关键码的值来确定,而是由关键码的一个分量来确定。
如下图所示Trie树,关键码由英文字母组成。它包括两类结点:元素结点和分支结点。元素结点包含整个key数据;分支结点有27个指针,其中有一个空白字符‘b’,用来终结关键码;其它用来标识‘a’, ‘b’,..., ‘z’等26个英文字母。
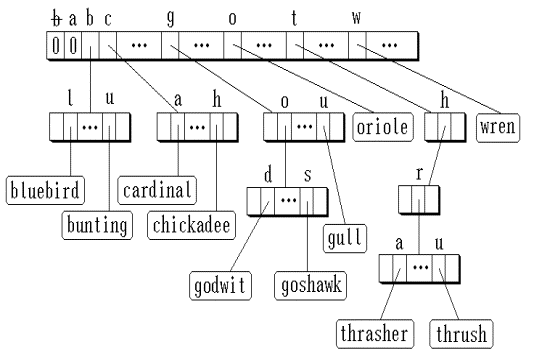
在第0层,所有的关键码根据它们第0位字符, 被划分到互不相交的27个类中。
因此,root→brch.link[i] 指向一棵子Trie树,该子Trie树上所包含的所有关键码都是以第 i 个英文字母开头。
若 某一关键码第 j 位字母在英文字母表中顺序为 i ( i = 0, 1, ?, 26 ), 则它在Trie树的第 j 层分支结点中从第 i 个指针向下找第 j+1 位字母所在结点。当一棵子Trie树上只有一个关键码时,就由一个元素结点来代替。在这个结点中包含有关键码,以及其它相关的信息,如对应数据对象的存放 地址等。
Trie树的类定义:
const int MaxKeySize = 25; //关键码最大位数
typedef struct { //关键码类型
char ch[MaxKeySize]; //关键码存放数组
int currentSize; //关键码当前位数
} KeyType;
class TrieNode { //Trie树结点类定义
friend class Trie;
protected:
enum { branch, element } NodeType; //结点类型
union NodeType { //根据结点类型的两种结构
struct { //分支结点
int num; //本结点关键码个数
TrieNode *link[27]; //指针数组
} brch;
struct { //元素结点
KeyType key; //关键码
recordNode *recptr; //指向数据对象指针
} elem;
}
}
class Trie { //Trie树的类定义
private:
TrieNode *root, *current;
public:
RecordNode* Search ( const keyType & );
int Insert ( const KeyType & );
int Delete ( const KeyType & );
}
10.3.2 Trie树的搜索
为了在Trie树上进行搜索,要求把关键码分解成一些字符元素, 并根据这些字符向下进行分支。
函数 Search 设定 current = NULL, 表示不指示任何一个分支结点, 如果 current 指向一个元素结点 elem,则 current→elem.key 是 current 所指结点中的关键码。
Trie树的搜索算法:
RecordNode* Trie::Search ( const KeyType & x ) {
k = x.key;
concatenate ( k, ‘b’ );
current = root;
int i = 0; //扫描初始化
while ( current != NULL && current→NodeType != element && i <= x.ch[i] ) {
current = current→brch.link[ord (x.ch[i])];
i = i++;
};
if ( current != NULL && current→NodeType == element && current→elem.key == x )
return current→recptr;
else
return NULL;
}
经验证,Trie树的搜索算法在最坏情况下搜索的时间代价是 O(l)。其中, l 是Trie树的层数(包括分支结点和元素结点在内)。
在用作索引时,Trie树的所有结点都驻留在磁盘上。搜索时最多做 l 次磁盘存取。
当结点驻留在磁盘上时,不能使用C++的指针 (pointer) 类型, 因为C++不允许指针的输入 / 输出。在结点中的 link 指针可改用整型(integer) 实现。
10.3.3 在Trie树上的插入和删除
示例:插入关键码bobwhite和bluejay。
a. 插入 x = bobwhite 时,首先搜索Trie树寻找 bobwhite 所在的结点。
b. 如果找到结点, 并发现该结点的 link[‘o’] = NULL。x不在Trie树中, 可以在该处插入。插入结果参看图。
c. 插入 x = bluejay时,用Trie树搜索算法可找到包含有 bluebird 的元素结点,关键码bluebird 和 bluejay 是两个不同的值,它们在第5个字母处不匹配。从 Trie树沿搜索路径,在第4层分支。插入结果参看图。
在Trie树上插入bobwhite和bluejay后的结果 :
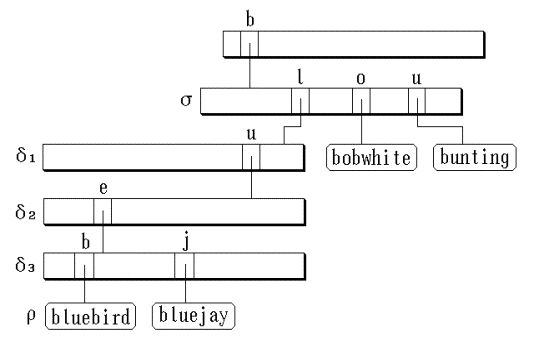
示例:考虑在上图所示Trie树中删除bobwhite。此时,只要将该结点link[‘o’]置为0 (NULL)即可,Trie树的其它部分不需要改变。
考 虑删除 bluejay。删除之后在标记为δ3 的子Trie树中只剩下一个关键码,这表明可以删去结点δ3 ,同时结点 ρ 向上移动一层。对结点δ2 和δ1 可以做同样的工作,最后到达结点б。因为以б 为根的子Trie树中有多个关键码,所以它不能删去,令该结点link[‘l’] = ρ即可。
为便于Trie树的删除, 在每个分支结点中设置了一个 num 数据成员,它记载了结点中子女的数目。
Trie,又称单词查找树,是一种树形结构,用于保存大量的字符串。它的优点是:利用字符串的公共前缀来节约存储空间。
性质
它有3个基本性质:
例子
这是一个Trie结构的例子:
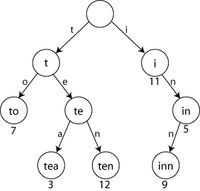
在这个Trie结构中,保存了t、to、te、tea、ten、i、in、inn这8个字符串,仅占用8个字节(不包括指针占用的空间)