XSLT初步
(文章转自:http://www.zdnet.com.cn/developer/tech/story/0,3800067013,39030849-1,00.htm)
XSL也就是所谓的扩展风格表单语言(Extensible Stylesheet Language)由3种语言组成。这三种语言负责把XML文档转换为其他格式。XML FO (XSL格式化对象:XSL Formatting Objects)说明可视的文档格式化,而Xpath则访问XML文档的特定部分。但是XSLT(XSL Transformations)才是把某一XML文档转换为其他格式的实际语言。
最简单的应用情况首先涉及到两个文档:包含原始数据的XML文档和用来转换该文档的XSLT风格表单。XSLT处理器把XSLT风格表单的规则应用到XML文档从而新建出XHTML、WML、SVG或者几乎其他任何XML格式的第3个文档。
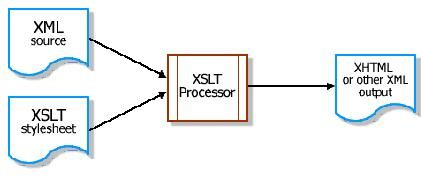
多个XSLT风格表单可以采用多种格式来表达某一文档。单一的风格表单还可以把某一数据类型的多种实例转换为标准的报告格式,你只需要修改风格表单就可以改变这些报告模式。而XSLT则可以把数据的多种实例转换为多种格式而不仅仅局限于报告格式:由此可见,XSLT是一种把某一系统的数据格式转换为另一系统(比如B2B交易)数据格式的强大工具。
XSLT从头学起
认真学习使用XSLT的高效方法会很费时间的。在学习内容中的某些方面很具有直觉性,而其他一些方便则可能会叫人很费解。不过,一旦你熟悉了XSLT 和 Xpath,你就可以相当快地在实际环境下熟练运用XSL了。
一开始你得需要一个XSLT处理器。随着各类技术的迅猛发展,你所采用的技术工具可能会让你所进行的项目要么成功要么毁灭。目前桌面XSLT原型工具并不多,因为这类工具大多数都针对全规模的产品系统。你必须仔细考虑使用的工具如何支持XSLT规范。
最近推出的浏览器,比如Internet Explorer 5.5、Netscape 6.1和Mozilla等,它们都支持XSLT处理功能。它们也许就是这方面最简单的使用工具了,可是,在其支持规范方面却相当欠缺。还有,浏览器并没有支持真正的开发工具,所以在调试代码的时候毫无用处。XSLT格式转化通常在服务器上完成,所以浏览器只能对那些包含了指向风格表单链接的XML文件才有效。
Instant Saxon 是一款用于Windows系统的命令行式的、服务器风格的XSLT简单处理器。它实现了基本的文件输出和错误信息。相比浏览器能提供更稳固的XSLT 支持。虽然这一工具还不是完全意义上的开发环境,但Instant Saxon作为实验用工具还是绰绰有余了。
XML Spy是一套完整的XML IDE,该软件可以从网络下载评估版。它采用了Instant Saxon作为其XSLT处理器。这一产品非常适合那些在应用环境下开发XML的工程人员,不过要掌握这套工具还真得需要点时间。
假如以上这些工具能为你所用,或者你希望自己动手建立一套完整的应用环境,我们在本文的末尾会为你列出一些基于服务器的XSLT处理器。
测试示例
下面的例子假设XSL处理工具和XML、XSL文件都在一个目录下。在这个例子中,我们用一个XML文档表示快餐定货单,下面我们需要把这个文档转换为可读的HTML格式。
现在请把该XML文档拷贝并且粘贴到某个文本编辑器内,然后把它另存为order.xml文件。同样的,把相应的XSL 文档拷贝为名为order.xsl的文件。这个 XML 文件链接到该 XSL风格表单,这样你就可以在合适的浏览器中查看该XML 文件,或者用XML Spy 对其进行XSL Transform 处理。接着用Instant Saxon打开一个MS-DOS命令行窗口,进到文件所在目录,键入saxon.exe order.xml order.xsl > order.html命令。
以上命令将把转换后的HTML 结果输出为一个名为 order.html的文件,这样你就可以通过自己的浏览器查看该文件了。
以上例子的结果如下:HTML页面的标题显示"Mike的定单(定单号734)",内容是他订购食品的列表,包括价格等。 XSLT 处理器处理了包含数据的 XML文件并把它转换为HTML输出结果。XSLT风格表单则定义了描述XML数据的 HTML标签定位,方法是采用组成XSLT语言的处理指令。
虽然 XSLT 处理器通常接受命令采用相应的风格表单处理,不过,XML文档可以指示自己默认的XSLT风格表单,方法是在文档中包含以下行:
 <?
xml-stylesheet type="text/xsl" href="my.xsl"
?>
<?
xml-stylesheet type="text/xsl" href="my.xsl"
?>
其中my.xsl是指向风格表单的URL。以上的代码对基于浏览器的格式转换是基本的要求。
XSLT风格表单
为了深入理解XSLT 编程,你必须首先理解 XML,因为 XSLT不只是负责转换 XML 而且自身还是一种完全意义上的XML标准语言。在理论上,你完全可以编写负责自身格式转换的XSLT风格表单,当然这是一件满有意思的事,只是没啥用处。
让我们回忆一下, XML 并不是一种通常意义上的语言,XML是一种元语言(metalanguage),也就是建立XML规范语言的结构(比如XSL和 XHTML就是XML规范语言)。HTML看起来很象XML,但实际上违反了好些 XML规则。
XML 语言定义了一套用来把数据标记为元素(或者可以说节点)的标签。比方说,就XHTML语法而言,<table>标签就等于开始标记某个特定的XML节点。XML节点可以包含属性和内容体。属性是由字符串组成的名字/值对。内容体可以是字符串和/或更多的 XML节点。这就意味着,XML是一种层次化的结构,可以表示很复杂的数据格式。我们不妨考虑以下的一个XHTML片段:
<
table
>
<
tr
>
<
td
>
Hello world!
</
td
>
<
td
><
img
src
="smiley.gif"
/></
td
>
</
tr
>
</
table
>
在以上的代码段中,每个节点都有自己的开-闭标签,两个标签之间是更多的节点和文本字符串。img 节点有一个src属性而没有内容,紧挨着开标签的是一个终止斜线。这个终止斜线和文本都在<td>节点内嵌套,而后者又在<tr>节点内嵌套,显然<tr>节点则在<table>内嵌套。
XSLT 的核心思想是建立上下文环境(context),也就是在XML文档内的特定节点或者整套节点同时输出为存在于这个环境内的格式化数据版本。为此, XSLT风格表单被分解为离散的模版,每个模版负责处理XML文档内某类型的标签。在这些模版内,XSLT要用到标量、传递参数、循环条件以及其他转换XML的元件。
<xsl:stylesheet>元素是任何XSLT风格表单的最外层元素,你要为其指定版本和一个或者多个名称空间(namespace):
<
xsl:stylesheet
version
="1.0"
xmlns:xsl
="http://www.w3.org/1999/XSL/Transform> </xsl:stylesheet>
</xsl:stylesheet>
你可以设置其他属性,但是,对几乎所有的基本风格表单来说,你可以原样使用这些<xsl:stylesheet>标签。其中就可以嵌套模版元素了。
XSLT模版
<xsl:template>元素定义了随导出结果输出而伴随的指令上下文环境,其语法如下所示:
<
xsl:template
match
="expression"
name
="name"
priority
="number"
mode
="mode"
>
</
xsl:template
>
XSLT 处理器在发现风格表单中的一个显式调用或者在源XML文档中发现匹配节点之后就会执行<xsl:template>。最常见的情况是当XSLT处理器扫描XML时遇到了匹配节点。匹配属性则用Xpath表达式标识模版中取出的节点。
激活的 <xsl:template> 元素输出其需要的内容。这些内容可能由文本和非XSLT的标记所组成并直接写入某个新建文档乃至更多的XSLT元素,后者则在匹配节点的上下文环境中执行。跟踪上下文环境是不可能的。XSLT元素只处理被模版激活的同类节点。
多个模版可以匹配一个节点。在这种情况下,采用模式和优先级属性的复杂规则确定了应由哪个模版来处理节点。最简单的风格表单只包含了匹配给定节点的一个模版。
对那些主要包含标记文本(比如HTML)的XML文档,你的XSLT风格表单很可能会包含你能遭遇的每个标签的一个模版。而对那些包含高度结构化层次数据的XML文档,你的风格表单可能只会包含顶级节点的模版。这些模版知道数据的结构并会直接访问子节点而不是跳到其他模版。
比方说,示例XML文件包含了一个较短的标记图书数据。它由一个<book>节点组成,而该节点则包含了<title>和多个<chapter>节点。这一模版会在顶级的<book>节点内执行每个<chapter>节点:
<
xsl:template
match
="/book/chapter"
>
This is chapter
<
xsl:number
/>
, entitled "
<
xsl:value-of
select
="title"
/>
"
</
xsl:template
>
假如某个 XSLT处理器没有针对节点或其父节点的匹配模版,它就会输出该节点的内容,不过这样做可能包含偏离其自身模版的子节点。 所以只处理模版的风格表单会产生以下的结果:
<?
xml version="1.0" encoding="utf-8"
?>
Stuff HappensThis is chapter 1, entitled "How it begins"This is chapter 2, entitled "What transpires"This is chapter 3, entitled "Where it ends"
显然,<paragraph>节点被忽略了,因为它们的<chapter> 父节点被处理了,但是第1个<title>并不在<chapter>之内所以干脆打印了事。
XPath 表达式
Xpath是索引XML文档特定部分的语言,不过它支持了相当丰富的特性集而非简单地指向数据。在XSLT风格表单中, Xpath表达式返回4种类型值:节点集合(node-set--、布尔值(Boolean)、数字和字符串。XSLT元素通常把XPath 表达式当作属性值,方法是采用计算表达式的结果。
基本XSLT的最常规用法是返回节点集合或者字符串,具体取决于有关的元素。比如, <xsl:template match="chapter"> 定义了 当前节点上下文环境内针对<chapter>节点的模版。在这种情况之下,Xpath表达式chapter即可返回节点集合作为以后XSL函数可用的新上下文。而在<xsl:value-of select="title"/>代码中, Xpath表达式把当前上下文中任何<title>节点的原始内容用字符串的形式返回。
节点导航
为了指向节点而不立即指向上下文环境,Xpath导航的外观和行为完全和文件系统导航一模一样。斜线分隔父子节点:chapter/title只在当前上下文的<chapter>节点内直接索引<title>节点。常用来进出目录层次的文件系统语法即可索引节点的父节点:../title会指向上下文节点父节点内的<title>节点,比如,在我们的示例中就是从章节中查看的图书标题。
但是,这种导航方式毕竟还是同文件导航有所差别,特别是,在文件导航的情况下,同一位置是不可能出现两个同名文件的,而前者却经常遭遇同一类型的节点,所以Xpath的定位,比如chapter/paragraph经常索引多个节点而非一个节点。
我们的路径到目前为止开始于当前上下文,但在文件系统的情况下,路径可以采用绝对定位而非相对定位的方式。开始斜线指向文档的根而不是文档的第1个节点,但是抽象节点可以表示XSLT模版内文档整体和默认的起始上下文。所以/book/title 只能返回顶级<book>内的<title>节点。
双斜线(//)是节点的通配路径。在我们以上的例子中,<xsl:template match="//title">会返回文档内各个位置的<title>节点而不论其是否在/book/title还是/book/chapter/title。双斜线可以位于路径的中间,所以,就我们的例子而言,/book//title会起很好的作用。
在路径的末尾加一个星号会返回所有找到的元素,这同文件系统通配符的用法是完全一样的。在上面的例子中,/book/chapter/* 会同时索引<title> 和 <paragraph> 节点,而路径//* 则会返回文档中的所有节点。
访问数据
Xpath提供了根据比较方法选择特定属性、元素实例之一和节点的语法。
@ 符号指节点的标签属性。在以上的例子中,某些<chapter>节点具有类型type属性,可以作为@type在上下文中访问。为了可以从文档的任何地方访问它路径应该写成/book/chapter/@type。
方括号从一个集合中选出一个节点,很象是传统编程中的数组。为了只选出第2个<chapter>,你可以用一个形如/book/chapter[2]的Xpath表达式。注意,集合中的第1个节点的编号是1,而不是大多数编程语言中规定的0。
你可以把这些条件组合起来按照其属性值选择节点,比如: /book/chapter[@type="prologue"]就仅仅选出第1个<chapter>。这种选择功能有许多,其内容已经超出了本文所涉及的范围,但值得你去摸一下。
高级方法
除了导航和数据提取之外, Xpath还提供了字符计数、变量设置、基本数学计算、找出最近元素以及其他多种类型的模式匹配等函数。这些函数属于更为高级的XSLT范畴了,但我们的测试风格表单体现了一个基础的数学示例。本文末还举出了一个详细的有关示例,该例采用了高级的比较和变量设置。
执行模版
模版不是什么复杂的东西,XSLT 在扫描XML文档时一旦遇到匹配节点就会激活模版。可是,在增加了XSLT元素的情况下,你就必须控制模版执行的流程来满足你的要求。
xsl:apply-templates
<xsl:apply-templates> 元素用在模版内告诉XSL处理器把所提供的节点集合匹配其他模版,其语法如下所示:
<
xsl:apply-templates
select
="expression"
mode
="mode"
>
</
xsl:apply-templates
>
在节点触发某个模版的情况下, XSLT通常会假定这个模版会专注该节点的所有内容而不去处理它们。模版内的<xsl:apply-templates> 元素则告诉XSLT处理器处理节点内容,在过程中执行任何有关的模版。
<xsl:apply-templates>默认地处理所有的最近的子节点。选择属性可以让你指定特定的派生节点进行处理。它会让Xpath表达式管理当前模版的上下文环境,模式属性则只让具有指定模式的模版被执行。
比如,假如你对/book 和 /book/chapter都建立了模版,你打算用/book模版中的<xsl:apply-templates>来激活/book/chapter :
<
xsl:template
match
="/book"
>
This book is entitled "
<
xsl:value-of
select
="title"
/>
"
<
xsl:apply-templates
/>
</
xsl:template
>
<
xsl:template
match
="/book/chapter"
>
This is chapter
<
xsl:number
/>
, entitled "
<
xsl:value-of
select
="title"
/>
"
</
xsl:template
>
查看示例XML
你可以看到多个模版把控制权按照一定的指令链转交给了其他模版。这样做把风格表单分解了可读的多个部分,使得模版的重用成为可能。
xsl:call-template
<xsl:call-template>元素按照名字执行其他模版,它的语法如下:
<
xsl:call-template
name
="name"
>
</
xsl:call-template
>
和<xsl:apply-templates>一样,<xsl:call-templates>把命令的执行临时转给带有同样名字属性的另一个模版。在不考虑其匹配值的情况下,被调用模版按照调用模版同样的上下文环境执行。比方说:
<
xsl:template
match
="/book/chapter"
>
<
xsl:call-template
name
="output-chapter-info"
/>
</
xsl:template
>
<
xsl:template
name
="output-chapter-info"
>
The name of chapter
<
xsl:number
/>
is ">xsl:value-of select="title"/>".
</
xsl:template
>
查看示例XML
注意到,<xsl:apply-templates> 和 <xsl:call-template> 都用终止斜线代替封闭标签。封闭标签用来嵌套其他附着于特定指令或者参数的XSLT元素。
参数和变量
参数和变量是你在模版处理过程中可用的命名值。变量只定义一次,而参数则是你可以覆盖的默认值。参数也只存在于定义其含义的模版上下文环境内。在模版和任何应用的模版或者被调用的模版完成之后,变量或者参数就不存在了。为了在几个模版之间使用参数或者变量就必须针对更高级节点建立模版。
xsl:param / xsl:with-param
该元素定义了模版内的一个参数,同时,在执行模版时为该参数赋值,语法如下:
<
xsl:param
name
="name"
select
="expression"
>
</
xsl:param
>
<
xsl:with-param
name
="name"
select
="expression"
>
</
xsl:with-param
>
在<xsl:template>内使用<xsl:param>即可定义参数,name属性是其唯一的标签,而 select则是定义参数默认值的Xpath表达式。同<xsl:apply-templates>或者<xsl:call-template>内的名字匹配的<xsl:with-param>会把覆盖值传递给应用或者被调用模版。比如:
<
xsl:template
match
="/book/chapter"
>
<
xsl:param
name
="use-title"
select
="string('No Title')"
/>
The name of chapter
<
xsl:number
/>
in the book "
<
xsl:value-of
select
="$use-title"
/>
" is "
<
xsl:value-of
select
="title"
/>
".
</
xsl:template
>
<
xsl:template
match
="/book"
>
<
xsl:apply-templates
select
="chapter"
>
<
xsl:with-param
name
="use-title"
select
="title"
/>
</
xsl:apply-templates
>
</
xsl:template
>
查看示例XML
这里的/book 模版把use-title参数传递给/book/chapter 模版。它传递的值就是Xpath表达式标题,意思是任何<book>以内的(我们的例子中就只有一个)<title>节点。该参数覆盖了默认值"No Title"。
xsl:variable
以上元素可以让你计算表达式并反复重用,这样可以使得代码具有更强大的可读性也更为优化。语法如下:
<
xsl:variable
name
="name"
select
="expression"
>
</
xsl:variable
>
name属性标记变量,而select则定义了Xpath值。XSLT不象大多数编程语言,后者一旦定义了变量就不能再改变。这就有局限性了,但是,一旦你熟悉XSLT风格表单,你就会发现,在大多数时间里,你可以不用重新指定变量就可以实现格式转换的目的。
<
xsl:template
match
="/book/chapter"
>
<
xsl:variable
name
="var-title"
select
="title"
/>
<
xsl:variable
name
="var-num"
><
xsl:number
/></
xsl:variable
>
The title of chapter
<
xsl:value-of
select
="$var-num"
/>
(I repeat:
<
xsl:value-of
select
="$var-num"
/>
) is "
<
xsl:value-of
select
="$var-title"
/>
".Did I mention the title is "
<
xsl:value-of
select
="$var-title"
/>
"?
</
xsl:template
>
查看示例XML
对所有的参数和变量元素而言,你可以用开闭标签之间的内容赋值而不用select属性来完成这些功能,比如以上的var-num 变量就是如此。注意,在以上两个例子中,元素<xsl:value-of>根据一个美元符号标记的名字索引了变量或者值。
计算值
由于模版包含了输出到转化后格式的内容,所以除了固定文本之外你还需要想办法完成输出操作。这些元素输出XML源文档和基于模版逻辑的文本所表达的内容。
xsl:value-of
<xsl:value-of>元素只输出Xpath表达式的值。语法如下:
<
xsl:value-of
select
="expression"
disable-output-escaping
="yes | no"
/>
XSLT处理器计算select属性并输出字符串形式的结果。节点路径产生节点的内容而属性路径、参数和变量则产生自己的值,比如说:
<
xsl:template
match
="/book/title"
>
Book Title =
<
xsl:value-of
select
="."
/>
</
xsl:template
>
<
xsl:template
match
="/book/chapter"
>
Title =
<
xsl:value-of
select
="title"
/>
Paragraph 1 =
<
xsl:value-of
select
="paragraph[1]"
/>
Paragraph 2 =
<
xsl:value-of
select
="paragraph[2]"
/>
</
xsl:template
>
查看示例XML
xsl:number
<xsl:number>元素输出数值。语法是:
<
xsl:number
level
="single | multiple | all"
value
="number"
count
="expression"
from
="expression"
/>
默认结果是当前节点在XML源文档中所在的位置,在第2个<paragraph>元素里,<xsl:number>会输出2。Level属性决定了位置是否在当前节点的父节点之内或者在整个文档范围之内,而level="all"的情况下,第3个<chapter>的第2个<paragraph>则会输出 6。Count和from 属性使用Xpath表达式指定计数的节点和从哪里开始计数。
该元素可以用来把变量声明为真实值而不是字符串,如下所示:
<
xsl:variable
name
="var-num"
><
xsl:number
value
="4"
/></
xsl:variable
>
数字系统和分组可用的<xsl:number>属性还有不少。注意, <xsl:value-of> 和 <xsl:number>都是自封闭的,没有封闭标签或者嵌套内容。 循环和排序
Xpath表达式可以一次指向具有给定类型的多个节点。假如你针对这类节点没有匹配的模版,你就需要从其他模版对其进行处理。假如你确实拥有了一个匹配的模版,你可能打算以不同的顺序从XML源文档处理节点。
xsl:for-each
<xsl:for-each>元素循环遍历节点集合同时用元素嵌套内容处理各个节点。语法是:
<
xsl:for-each
select
="expression"
>
</
xsl:for-each
>
该元素在模版内应用。Select属性是一个Xpath表达式,从模版的上下文环境指向节点集合。元素的嵌套内容在自己的上下文环境中处理这些节点。比如:
<
xsl:template
match
="book"
>
<
xsl:for-each
select
="chapter"
>
This is chapter
<
xsl:number
/>
, entitled
<
xsl:value-of
select
="title"
/>
</
xsl:for-each
>
</
xsl:template
>
在循环以内,上下文成为当前的<chapter>节点,而模版则打印章节的<title>而非书籍的<title>。
xsl:sort
<xsl:sort>元素在<xsl:apply-templates>或者<xsl:for-each>元素对节点处理之前对节点集合排序。其语法如下:
<
xsl:sort
select
="expression"
order
="ascending | descending"
data-type
="text | number"
case-order
="upper-first | lower-first"
lang
="language"
/>
select属性指定排序的节点,你可以按照节点的属性或者子节点进行排序操作。Order属性指定升序或者降序排序,data-type则设定是否按照数字或者字母计算结果排序, case-order规定了比较大小写字母的方式,lang属性告诉XSL处理器按照语言相关算法排序。
<
xsl:template
match
="/book"
>
<
xsl:apply-templates
select
="chapter"
>
<
xsl:sort
select
="title"
order
="ascending"
/>
</
xsl:apply-templates
>
</
xsl:template
>
<
xsl:template
match
="chapter"
>
The title of chapter
<
xsl:number
/>
is "
<
xsl:value-of
select
="title"
/>
".
</
xsl:template
>
按照标题对章节模版排序,以上的例子会按照字母顺序打印章节标题。
条件
对给定类型的各个节点仅仅确定执行还是不执行是不够的。XSLT还提供了conditional(条件)元素来支持例外和替代方法。
xsl:if
如果<xsl:if>元素内Xpath表达式的select属性值为真,那么<xsl:if>元素会处理自身的嵌套内容,其语法如下:
<
xsl:if
select
="expression"
>
</
xsl:if
>
尽管类似于其他编程语言中的条件构造,<xsl:if>没有"else"语句。所以你只能使用<xsl:choose>元素,比如:
<
xsl:template
match
="/book/chapter"
>
<
xsl:variable
name
="num"
><
xsl:number
/></
xsl:variable
>
<
xsl:if
test
="$num = 1"
>
This is chapter 1!
</
xsl:if
>
<
xsl:if
test
="$num = 2"
>
This is chapter 2!
</
xsl:if
>
</
xsl:template
>
xsl:choose / xsl:when / xsl:otherwise
同<xsl:if>元素相似,<xsl:choose>按顺序检查各种不同条件,在所有的其他条件都不满足的情况下执行默认操作,语法如下:
<
xsl:choose
>
<
xsl:when
select
="expression"
>
</
xsl:when
>
<
xsl:when
select
="expression"
>
</
xsl:when
>
<
xsl:otherwise
>
</
xsl:otherwise
>
</
xsl:choose
>
只有第1个<xsl:when>计算为真才执行自身嵌套内容。假如以上各个条件都不满足就要执行<xsl:choose>内的默认行为了。比如:
<
xsl:template
match
="book/chapter"
>
<
xsl:variable
name
="num"
><
xsl:number
/></
xsl:variable
>
<
xsl:choose
>
<
xsl:when
test
="$num = 1"
>
This is chapter 1
</
xsl:when
>
<
xsl:when
test
="$num = 2"
>
This is chapter 2
</
xsl:when
>
<
xsl:otherwise
>
This had better be chapter 3.
</
xsl:otherwise
>
</
xsl:choose
>
</
xsl:template
>
采用条件元素的时候需要更多高级的Xpath表达式进行计算和比较。
到现在为止,你应该对XSLT有了一个比较全面的认识,所以有必要动手编写风格表单了。为此,我们准备了一个更为复杂的例子,试图进一步地演示XSLT的强大功能。记住,这个例子并没有说明XSLT其他更高级和更复杂的方面,但也足够让你能清楚地意识到你能用它来做什么。
在示例中,我们首先用一个XML文档来代表2002年世界杯CONCACAF半决赛。该文档包含了位置、比赛日期和各队比分。以下是其中的部分 XML代码(完整的文档相当长):
<?
xml version="1.0" encoding="utf-8"
?>
<
world-cup
year
="2002"
>
<
conference
name
="CONCACAF"
>
<
round
level
="Semifinal"
group
="C"
>
<
match
>
<
date
>
2001-07-16
</
date
>
<
location
>
Edmonton
</
location
>
<
team
>
<
name
>
Canada
</
name
>
<
score
>
0
</
score
>
<
score-at-half
>
0
</
score-at-half
>
</
team
>
<
team
>
<
name
>
Trinidad and Tobago
</
name
>
<
score
>
2
</
score
>
<
score-at-half
>
1
</
score-at-half
>
</
team
>
</
match
>
<
match
>
<
date
>
2001-07-16
</
date
>
<
location
>
Panama City
</
location
>
<
team
>
<
name
>
Panama
</
name
>
<
score
>
0
</
score
>
<
score-at-half
>
0
</
score-at-half
>
</
team
>
<
team
>
<
name
>
Mexico
</
name
>
<
score
>
1
</
score
>
<
score-at-half
>
0
</
score-at-half
>
</
team
>
</
match
>
</
round
>
</
conference
>
</
world-cup
>
我们的XSLT风格表单用类似官方的FIFA 世界杯网站的风格表达有关信息。它把比赛数据转换为HTML,采用高级 XPath 来计算胜负和总分。HTML表内的数学表达式改变每行的颜色。比赛和被调用模版接收传递的参数并对节点集合进行排序。
为了检查以上示例的运行情况,你可以拷贝以下的完整文档然后通过XSLT处理器运行。
如何使用XSLT
作为一条原则,你表达信息的方法应当同信息本身相分离。不论你是把HTML提交给人浏览或者作为特定的XML格式交付给计算机,你的数据都是用多种格式存储的。假如格式是XML或者可以很方便地转化为 XML,那么XSLT正是把你的数据转化为信息接受者所需要表达格式的好东西。
虽然任何人都可以使用XSLT,在具体的商务应用方面却还有有些标准模式需要遵循的。在动态发布环境下,比如在线商店等, HTML开发人员或者模版工程师通常负责控制XSLT。后端工程师则负责开发提供动态内容的XML数据系统,而工程师和接口专家则负责定义可视外观和前端功能。XSLT开发人员驻留在这个团队的中心,灵活地按照设计组的要求表达XML。
或者,也许你的公司从事销售信息业务。你把自己的数据存储为XML类型的格式,其他公司订购你的 XML数据信息。这些公司可能会把他们的数据存储为不同的XML类型数据。 所以激提供了一个转换服务用XSLT把自己的XML信息转换为他们的XML格式。每一种不同的XML格式只需要一个或者几个XSLT风格表单,同时当数据发送给接收者的时候这种转换就实时进行了。
基本XSLT之外
在完全的应用环境下开发 XSLT 同简单的桌面开发具有相当大的差异。在本文所阐述的内容范围之外读者不妨了解一些值得关注的开发包。大多数人已经用Java开发出了相应的工具, Perl和C++开发的相应软件也有一些:
" Apache Xalan处理器
" Apache Xalan 用C++实现
" Michael Kay的Saxon
" James Clark的XT
" Cocoon 发布框架
" LotusXSL
" Perl XSL模块
许多 XSL 处理器都有可定制扩展或者允许你自己编写。而对Saxon来说,你可以用Java编写自己的 XSLT标签。 Apache的 Xalan也允许这种情况而且还有一个不断增长中的扩展库。
JSP 标签库同XSLT一样满足了把动态XML数据实时转换为HTML的多种目标。这两种技术有许多相似之处,许多公司都开始同时使用它们。Jakarta Taglibs项目就在用JSP技术实现 XSLT。
XSL Formatting Objects是第3类XSL,这是一种用于复杂可视化表示的XML语言。它同 XSLT一道把 XML 数据转换为非XML格式。而 Apache FOP 和 REXP则可以用XSL把 XML翻译为Adobe PDF。