智算之道——人工智能应用挑战赛(初赛)-baseline 0.844
智算之道——人工智能应用挑战赛(初赛)-baseline
比赛类型:数据挖掘
比赛数据:表格题(csv)
学习方式:有监督
比赛链接
比赛任务:疾病的预测往往能够从病人的病历历史数据挖掘当中判断,而许多有价值的发现也往往是在对于结构化数据的建模与分析之中得出。本赛题希望通过结构化的数据预测与分析,判断一名病人的是否患有肝炎。
提交结果

注:本baseline仅供大家快速上手和提交
目录
- 智算之道——人工智能应用挑战赛(初赛)-baseline
- 1 项目创建和使用
- 2 数据读取
-
- 2.1 导入相关库
- 2.2 读取数据
- 2.3 数据EDA
- 2.4 特征工程
- 3 模型
-
- 3.1 准备数据集
- 3.2 训练模型
- 3.3 提交
1 项目创建和使用

从上图的平台入口进入平台——工作台——新建项目(填写项目名称和项目描述即可),之后在项目创建notebook便可进入环境
2 数据读取
2.1 导入相关库
import os
import pandas as pd
import warnings
from itertools import combinations
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import LabelEncoder, MinMaxScaler
from sklearn.model_selection import StratifiedKFold
from tqdm import tqdm
from xgboost import XGBClassifier
from lightgbm import LGBMClassifier
from catboost import CatBoostClassifier
%matplotlib inline
warnings.filterwarnings('ignore')
pd.set_option('display.max_rows',None)
pd.set_option('display.max_columns',None)
2.2 读取数据
数据集路径在 ‘/home/kesci/data/competition_A/’ 下
path = '/home/kesci/data/competition_A/'
train_df = pd.read_csv(path+'train_set.csv')
test_df = pd.read_csv(path+'test_set.csv')
submission = pd.read_csv(path+'submission_example.csv')
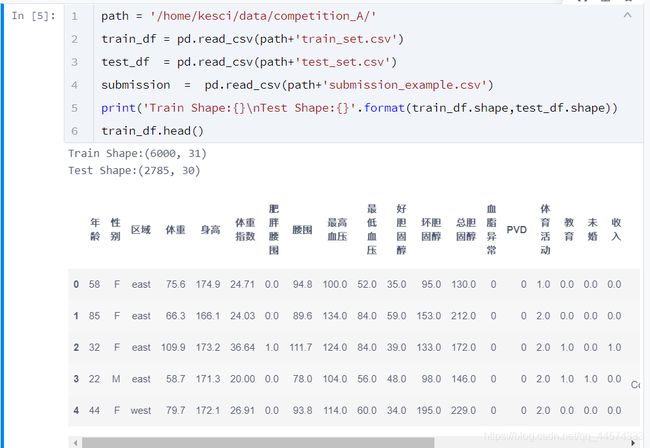
print('Train Shape:{}\nTest Shape:{}'.format(train_df.shape,test_df.shape))
train_df.head()
2.3 数据EDA
findfont: Font family [‘sans-serif’] not found. Falling back to DejaVu Sans.
对不起,环境中没有SimHei字体,sns的中文暂时没法显示
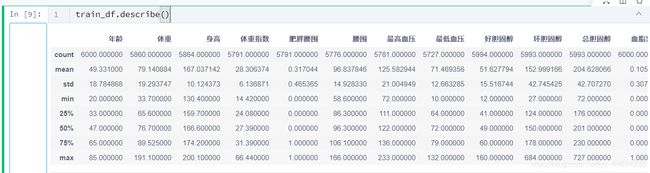
根据训练集的列可以得到大致如下三种特征:数字列、二值列(0或1)、字符列
num_columns = ['年龄','体重','身高','体重指数', '腰围', '最高血压', '最低血压',
'好胆固醇', '坏胆固醇', '总胆固醇','收入']
zero_to_one_columns = ['肥胖腰围','血脂异常','PVD']
str_columns = ['性别','区域','体育活动','教育','未婚','护理来源','视力不佳','饮酒','高血压',
'家庭高血压', '糖尿病', '家族糖尿病','家族肝炎', '慢性疲劳','ALF']
肝炎与年龄
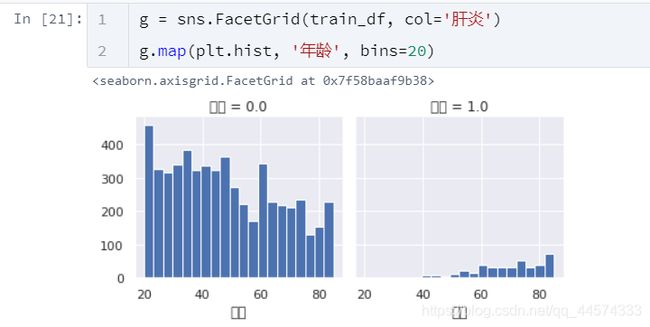
从上图中可以看出在训练集中患肝炎的年龄都是比较大的,也就是说年龄将会是一个很重要的区分是否患肝炎特征
暂时先不画了,如果解决了中文字体,会持续更新
2.4 特征工程
字符编码,将如[‘A’,‘B’,‘C’,‘D’]编码成[0,1,2,3]
# 字符编码
for i in tqdm(str_columns):
lbl = LabelEncoder()
train_df[i] = lbl.fit_transform(train_df[i].astype(str))
test_df[i] = lbl.fit_transform(test_df[i].astype(str))
数据归一化
# 数值归一化
train_df[num_columns] = MinMaxScaler().fit_transform(train_df[num_columns])
test_df[num_columns] = MinMaxScaler().fit_transform(test_df[num_columns])
空值填充
train_df.fillna(0,inplace=True)
test_df.fillna(0,inplace=True)
3 模型
3.1 准备数据集
all_columns = [i for i in train_df.columns if i not in ['肝炎','ID']]
train_x,train_y = train_df[all_columns].values,train_df['肝炎'].values
test_x = test_df[all_columns].values
submission['hepatitis'] =0
3.2 训练模型
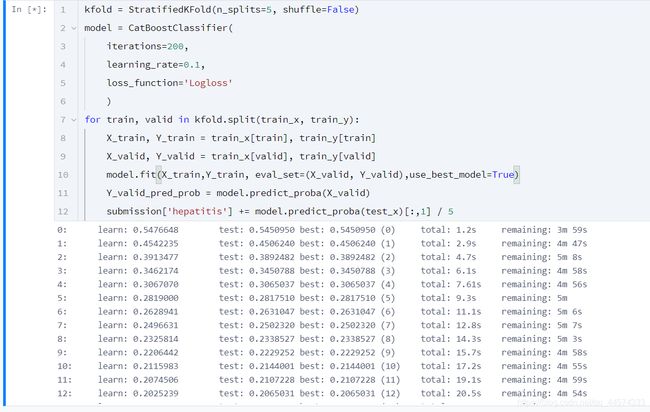
kfold = StratifiedKFold(n_splits=5, shuffle=False)
model = CatBoostClassifier(
iterations=200,
learning_rate=0.1,
loss_function='Logloss'
)
for train, valid in kfold.split(train_x, train_y):
X_train, Y_train = train_x[train], train_y[train]
X_valid, Y_valid = train_x[valid], train_y[valid]
model.fit(X_train,Y_train, eval_set=(X_valid, Y_valid),use_best_model=True)
Y_valid_pred_prob = model.predict_proba(X_valid)
submission['hepatitis'] += model.predict_proba(test_x)[:,1] / 5
3.3 提交
下述代码只需注意修改token即可
!wget -nv -O kesci_submit https://cdn.kesci.com/submit_tool/v4/kesci_submit&&chmod +x kesci_submit
submission.to_csv('submission.csv',index=False)
!./kesci_submit -token '你的队伍Token' -file '/home/kesci/work/submission.csv'
完整ipynb文件可见Github