腾讯会议,一款提供灵活协作的线上会议解决方案。其中大量的模块是有状态服务,在使用Kubernetes为其进行容器化部署时,Pod升级需保持共享内存、长连接服务。升级时只容忍ms级抖动,需提供大规模分批灰度发布、业务配额控制等能力,并同时解决集群节点负载不均衡、上万Pods的Workload的HPA性能差等问题。这里将向大家介绍TKEx容器平台及其在灰度发布、资源管理、弹性伸缩等方面的能力。
海量规模下Kubernetes面临的挑战
在腾讯自研业务中,已经有几百万核跑在Kubernetes上,要在如此体量的容器场景提供可靠稳定的容器服务,无论在底层、集群能力、运营或运维等各个方面都面临具体挑战。
- 我们怎么进行容器可靠高性能的灰度发布? 尤其是在自研业务里面,大量的服务是有状态的服务, 原生的Kubernetes StatefulSet已经无法满足我们如此大规模的容器发布需求。
- 调度层面需要做哪些优化,从而保证在Pod漂移和重调度的过程中保证业务的稳定性。
- 在优化资源编排性能方面,如何在整个平台层面和业务层面做好后台管理。
- 在大规模的弹性伸缩方面如何提供高性能和全面的弹性伸缩能力。
TKEx容器平台简介
TKEx容器平台的底层基于腾讯公有云的TKE和EKS两个产品,它是使用Kubernetes原生的技术手段服务于腾讯内部的业务, 包括腾讯会议、腾讯课堂、QQ及腾讯看点等。TKEx在灰度发布、服务路由、弹性伸缩、容器调度、资源管理、多集群管理、业务容灾、在离线混部等方面做了大量工作,比如:
- 通过Kubernetes API/Contoller/Operator的原生方式适配腾讯内部各种系统,比如服务路由系统、CMDB、CI、安全平台等。
- 通过声明式的方式,对所有的托管业务进行生命周期管理。
- 支持在线业务、大数据、AI等类型作业。
- 实现在线业务和离线业务的混合部署,同时提升整个资源的利用率。
- 通过优化linux的内核,增强资源底层隔离能力。
- 集成Tencent Cloud Mesh(TCM)服务为自研业务提供ServiceMesh服务。
- 在大规模的集群里面,对弹性伸缩的各种组件进行改造和优化,以保证它的性能和可用性。
- 基于业务产品维度,提供多租户和配额管理能力。
下面是TKEx平台缩略版的架构图,仅包括本次讨论的相关能力。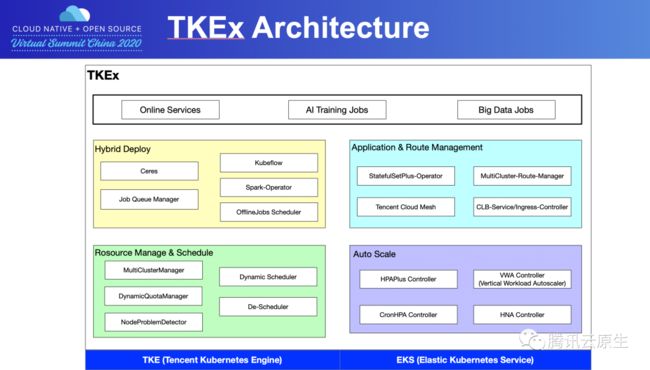
- 底层基于TKE和EKS两个产品,在上层服务于在线业务、AI训练以及大数据作业。
- 中间这四个框主要包括在应用和路由管理、资源编排调度、弹性伸缩、混部。下面会重点介绍其中前三个部分。
高效稳定的发布能力
业务没有大规模使用StatefulSet的滚动更新能力,对于有状态服务来说,原生的滚动更新机制的发布可控性太差,对于multi-zone容灾部署的业务更是很难做精细化的发布策略。我们提供了分批灰度发布策略供有状态服务使用,约80%的Workload都选择了这种策略。

以一个业务分两批进行发布为例,第一批升级两个Pod,用户可以指定是哪两个Pod,也可以按照一定比例指定第一批是10%,由平台自动选择10%的Pod进行灰度,剩余Pods在第二批进行灰度。
- 自动分批机制:如果Pod的探针完善且能真实反映业务是否可用,用户可以使用自动分批机制,上一批次完成后可通过自定义的批次时间间隔和健康检查机制自动进行下一批的灰度发布或者自动回滚。
- 手动分批机制:用户也可以通过手动分批机制,在上一批次灰度完成后,可人为在业务层面确认上一批的灰度是否成功,来决定是否触发下一批灰度还是回滚。
分批灰度发布更安全、更可靠、更可控的特性,整个发布过程更灵活。由于单个批次内所有选中Pods的更新都是并发的,因此可以应付紧急快速发布的需求。

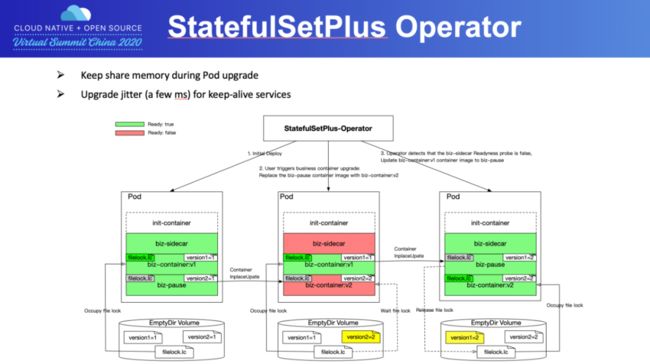
StatefulSetPlus是我们用来实现分批灰度发布的CRD,它继承了Kubernetes原生的StatefulSet的所有能力,并在此之上新增和优化了大量特性。StatefulSetPlus主要提供的核心特性包括自动的以及手动的分批灰度发布,在发布异常时可以进行全量一次回滚或者分批次的回滚。Pod更新的策略支持两种形式,一种是Pod重建的方式,另一种是Pod的原地升级方式。同时我们还提供了一些高级特性,比如:
- 支持Pod升级过程中保持Pod使用的共享内存数据不丢失,这个特性非常适合于像腾讯会议这样的音视频业务。
- 如果升级过程中触发了Workload的扩容,那么扩容的时候会使用上一个好的版本进行扩容,而不是像原生的StatefulSet和Deployment一样,使用最新的镜像进行扩容,因为最新的镜像版本有可能是不可用的,扩容出来的Pod可服务型存在风险。
- 在存储编排方面,我们继承了StatefulSet的Per Pod Per PV的特性,同时也支持Per Workload Per PV的特性,即单个StatefulSetPlus下面所有的Pod共享一个PV,也就是类似Deployment共享PV的模式。
- 在StatefulSet里面,当节点出现异常,比如出现了NodeLost的情况下,出于有状态服务的可用性考虑,不会进行Pod重建。在StatefulSetPlus中,监听到NodeLost后,对应的Pod会自动漂移。这还不够,我们会通过NPD检测,上报事件或Patch Condition快速发现节点异常,对StatefulSetPlus Pod进行原地重建或者漂移等决策。
- StatefulSetPlus还有一个非常重要的特性,就是它支持ConfigMap的版本管理以及ConfigMap的分批灰度发布,这是决定ConfigMap能否大规模在生产中使用的关键能力。
这里特别介绍一下,如何支持Pod升级过程中保持共享内存数据不丢失,并且在升级过程中,单个Pod只有毫秒级的服务抖动。主要的实现原理就是在Pod里面,通过一个占位容器和业务容器进行文件锁的抢占动作,来实现升级过程中两个容器的角色进行快速切换。
动态的资源调度和管理
kubernetes的调度原生是使用静态调度的方式,在生产环境会出现集群里面各个节点的负载不均衡的情况,并且造成很大的资源浪费。
动态调度器是我们自研的一个调度器扩展器,主要任务是平衡集群中各个节点真实的负载,在调度的时候,将各个节点的真实负载纳入考量的范畴。

动态调度器必须要解决的一个技术点是调度热点的问题。当集群中有一批节点负载比较低,这时用户创建大量的Pod,这些Pod会集中调度到这些低负载的节点上面,这将导致这些低负载节点在几分钟之后又会成为高负载节点,从而影响这批节点上Pod的服务质量,这种现象尤其在集群扩容后很容易出现。我们自研的调度热点规避算法,极大的避免了某个节点因为低负载被动态调度器调度后成为延迟性的高负载热点,极少数高负载节点在de-scheduler中会基于Node CPU的历史监控进行节点降热操作。。
我们希望能够快速地感知集群的异常情况,包括kubelet异常、docker异常、内核死锁以及节点是否出现文件描述符即将耗尽的情况,从而能在第一时间去做决策,避免问题的恶化。其中快速发现这个动作是由Node Problem Detector(NPD)组件负责的,NPD组件是基于社区的NPD进行了大量的策略扩展。

NPD检测到异常后,除了NPD组件本身对节点自愈的动作之外,de-scheduler还会基于异常事件和当前集群/Workload现状协助进行动作决策,比如Pod驱逐、Container原地重启。这里要重点提一下,我们基于Self算法的分布式的Ping检测,能够快速发现节点的网络异常情况,由de-scheduler对网络异常节点上的Pods进行漂移。
在腾讯内部,产品的管理是分多个层级的,因此在配额管理方面,我们没有使用Kubernetes原生的ResourceQuota机制,而是研发了DynamicQuota CRD来实现多层级的、动态的面向业务的Quota管理。
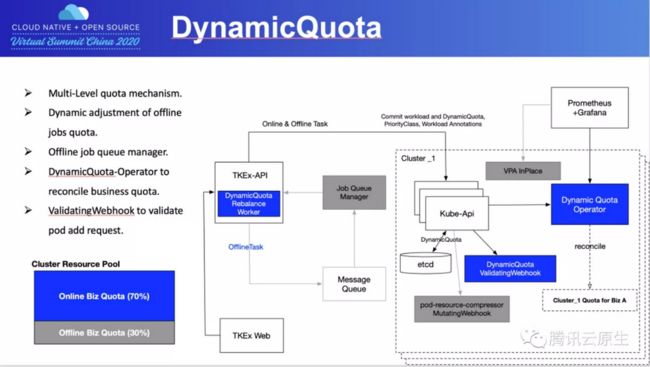
比如从业务维度,腾讯会议是一个产品、腾讯课堂是一个产品,每个产品下面都会有多级业务模块,在做资源规划和配额管理的时候,是基于产品维度的。在实际部署的时候,实际上Workload绑定到对应的CMDB的最后一级模块。所以,这里需要自动的将产品配额下发到CMDB多级模块的机制,通过DynamicQuota不只是做资源使用上限的控制,更重要的是保证这个业务有这么多配额可以用,防止被其他业务抢占了。
当然这里还有一些关键问题,比如为了避免资源浪费,我们需要把一些产品的空闲资源借调给其他已经超过配额控制但是需要继续使用更多资源的业务,这样配额就有了灵活的弹性。
同时我们也利用了DynamicQuota控制在线业务和离线业务占用资源的比例,主要是为了保证在线业务始终会有一定的配额可以使用,防止离线业务无限制侵占整个平台的资源,同时也能更好的控制集群负载。
大规模和高性能的弹性伸缩
在扩缩容方面,这里主要介绍纵向扩缩容和横向扩缩容做的工作。社区的VPA不太适合很多腾讯的自研业务,因为扩缩容都是基于Pod的重建机制,在扩容效果和对业务的感知方面,都不是很好。

我们自研了Vertical Workload AutoScaler (VWA) CRD用于Pod的垂直扩缩容,主要解决的问题是:
- 当业务出现突发流量的时候,HPA扩容不及时,导致下面Pod的资源利用率暴涨,进而引发业务的雪崩。VWA有更快的响应速度,并且不需要重建Pod,因此比HPA更快更安全。
- 业务在使用容器规格的时候,经常把容器规格配置得比较高,Pod资源使用率会比较低,通过VWA自动进行降配,优化资源利用率。
- 当节点出现高负载的情况下,这个节点上面跑着在线和离线业务,我们会通过VWA快速地对离线业务容器进行在线降配,从而保证在线业务的服务质量。
这里面核心的特性,包括提供原地升级容器规格的能力,而不需要重建Container,性能上做了优化,单集群能支持上千个VWA对象的扩缩容。同时也支持VWA的个性化配置,比如可以配置每一个VWA对象的循环同步周期,每次扩容的最大比例以及缩容的最大比例等。
最后再介绍一下在HPA方面我们做的工作。Kubernetes原生的HPA Controller是内置在kube-controller-manager里面的,它存在着以下缺陷:
- 它不能独立部署,如果集群中有成千上万的HPA对象,原生HPA Controller是很难承受的,稳定性也直接受限于kube-controller-manager。
- 另外在性能方面,原生HPA Controller在一个协程里面遍历所有HPA对象,所以在大规模HPA场景下,同步实时性得不到保证。
我们自研了一个HPAPlus Controller,它兼容了原生的HPA对象,然后可以独立部署,在性能方面类似VWA一样做了很多性能优化,同时丰富了每个HPA对象可自定义的配置,比如同步周期、扩容比例、容忍度等。

HPAPlus-Controller还实现了与CronHPA和VWA进行联动决策,比如当VWA持续扩缩容达到了所属节点的上限,无法继续扩容的时候,这个时候会自动托管给HPA触发横向扩容。
总结
腾讯自研业务海量规模,除了文中介绍到弹性伸缩、调度和资源管理、灰度发布等方面面临的挑战外,我们还在多集群管理、在离线混部、ServiceMesh、异构计算、AI/大数据框架支持等多方面做了大量工作。另外,TKEx底层正在大量使用EKS弹性容器服务来提供更好的容器资源隔离能力、弹性能力,以实现真正的零集群运维成本和高资源利用率的目标。