课程向:深度学习与人类语言处理 ——李宏毅,2020 (P30)
Question Answering
李宏毅老师2020新课深度学习与人类语言处理课程主页:
http://speech.ee.ntu.edu.tw/~tlkagk/courses_DLHLP20.html
视频链接地址:
https://www.bilibili.com/video/BV1RE411g7rQ
图片均截自课程PPT、且已得到李宏毅老师的许可:)
考虑到部分英文术语的不易理解性,因此笔记尽可能在标题后加中文辅助理解,虽然这样看起来会乱一些,但更好读者理解,以及文章内部较少使用英文术语或者即使用英文也会加中文注释,望见谅
深度学习与人类语言处理 P30 系列文章目录
- Question Answering
- 前言
- I Answer QA任务中的答案
-
- 1.1 Substance 基本内容
- 1.2 Word 答案为词汇
- 1.3 Choice 答案为选项
- 1.4 Span 答案为文中片段
- 1.5 Paragraph 答案为一整段话
- 1.6 No Answer 无答案
- II Source QA任务中的来源
-
- 2.1 Internet 来源为文字资料
- 2.2 Visual 来源为图片
- 2.3 Audio 来源为语音
- 2.4 Movie 来源为多种
前言
在上篇中的上半篇P29中,我们学习到在语音方面前沿的AALBERT的有关内容。
而在本篇P30和下一篇P31中,我们将进入Question Answering QA问题的学习,本篇将介绍QA中Question 答案和 Source 来源的种种,下一篇将是有关问题的部分。
I Answer QA任务中的答案
1.1 Substance 基本内容
Question、Source & Answer

对于 QA 任务,有两个输入:Question 问题和 Source 来源,输出为根据所给文章可得到问题的 Answer 答案。
在此,Question 问题 有这样几种:
- 有标准答案的简单客观问题,如“谁是现任美国总统?”,答案就是特朗普,这样的问题与答案是不存在任何争议的。
- 多来源的问题,如“特朗普年龄比奥巴马大吗?”,这个答案就需要机器先在某篇文章中找到特朗普的年龄,再可能从其他文章中找出奥巴马的年龄,要通过不同来源才能得到答案。
- 没有标准答案的问题,如“约会时谁应该付钱,为什么?”,情感问题可能真的没有答案。
有关感情的问题,我一律建议分手!
而有关答案的 Source 来源可以是很多种:如文章、网络、语音、视频等。
对于问题和来源都要经过一定的预处理,如通过BERT转成词向量嵌入等,且对于问题和来源得到的向量后可能还会通过Attention机制。接下来,通过一个寻找答案的模块输入预处理后的问题和来源,输出答案,而对于Answer 答案而言,有以下几种:
- word:词汇
- span in source:文中片段
- correct choice:选项
- paragraph:一整段话
以下,我们将通过各种答案的类型进行QA任务的学习,
1.2 Word 答案为词汇

最简单的答案形式就是输出一个词汇,在QA领域,类似图像中的MNIST数据集一样,bAbI是最早最经典的QA数据集。它有20种不同的类别,具体数据可参见上图,像这样的QA其实已经是很简单的了,不过在2015年当年是被认为通过20个任务来测试机器的语言理解能力。当然,今天深度学习方法已经能达到95%以上的正确率了。那怎么做呢?

对于模型而言,简单来讲,这就是一个多分类问题,将所有可能的答案作为一个个类别。Answer模块就是一个多分类器。bAbI就是这么解的。当然,在此也可看出这其实并不是真正的理解语言,只是寻找pattern规律而已。
1.3 Choice 答案为选项

另外一种类型的问题是选择题,在选择题中根据文章、问题来选择出正确的那个选项。对于模型而言,除了Source 来源、Question 问题的预处理外,还需要Choice 选项的预处理。接下来,这三个部分也可能互相都要使用Attention机制,再丢给最终寻找答案的模块。
此时,有两种解法,第一种是将每一个选项一一与文章和问题进行判断,输出Yes/No,二分类问题。第二种是直接把所有选项与文章和问题进行判断,输出正确的选项,这就又变成了一个多分类的问题。但如果当成多分类的问题的话,可能会遇到这样的情况,不同问题有不同个数个选项,也就是说多分类时,类别数目会发生变化,这样很不容易处理,因此当成二分类问题是稳定、有弹性的解法。
1.4 Span 答案为文中片段

第三种类型的答案是所给文章中的某一连续片段,如SQuAD和DRCD。SQuAD就是从输入的文章里找其中一段,也就是基于抽取式的QA,这是英文中比较具有代表性的。对于中文,DRCD是比较著名的,仿照SQuAD。
解法如上图,输入Source 文章,模型要给文章中每个token一个作为起始的分数,和一个作为结尾的分数。接下来,选出其中起始分数最大的token和结尾分数最大的token,答案也就是从起始到结尾token间的这一段,如上图的 w 3 , w 4 , w 5 w_3,w_4,w_5 w3,w4,w5
那怎么产生起始和结尾的分数呢?
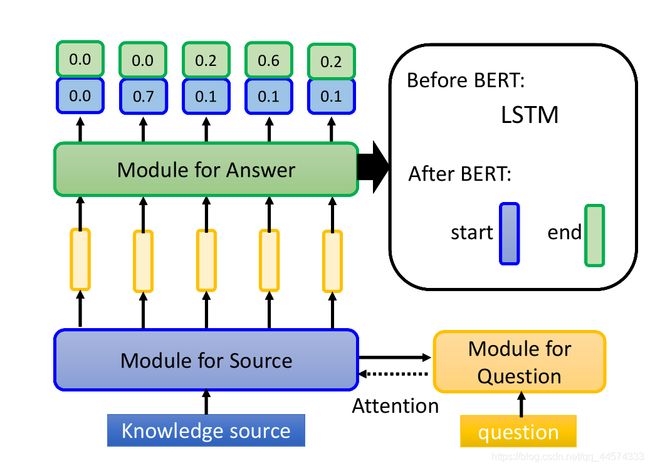
Source 来源同样是将其中每个token做词向量嵌入。而对于Question 问题则是产生两个向量,一个代表start,另一个代表end。然后,将Source 来源的每个词向量分别和这两个向量去算一下它们的某种相似度,可以是点乘,将这个相似度当作是起始和结束的分数即可。
1.5 Paragraph 答案为一整段话

最后一种也是最复杂的,答案是没有任何限制的。有代表性的数据集,对于英文来说有MS MARCO,中文有DuReader。
在 MS MARCO 英文数据集中,问题有几种类型,答案就有几种类型。如第一种,答案在文章中找不到,但答案中的每个词汇是出现在文中各个部分的,所以像刚刚讲述Span 文中片段的解法便不再适用。第二种,答案的词汇一部分出现在文章里,一部分出现在问题里。第三种,答案的关键词出现在文章里。第四种,答案没有出现在文章的任何地方,这种问题一般也是以Yes/No为答案。
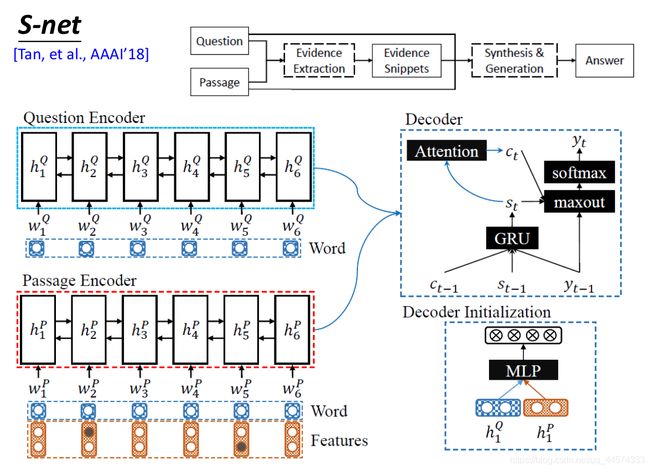
那对于这些不同类型的问题和答案,该怎么解呢?一个直觉的想法就是seq2seq,比较有代表性的便是S-net,如下图。
1.6 No Answer 无答案
上述讲了好几种QA的形态,但还有一种特殊的状况需要我们考虑,因为并不是所有问题都有答案,如悖论。
所以该怎么让机器遇到不该回答的问题,选择不回答呢?有这样一个著名的数据集,SQuAD 2.0,就是测验机器不回答的能力,在这个数据集中有很多假的问题。举个例子,如问题是“1937年哪一个条约被签订”,而在文章中只提到了“1937年签订了一个条约,1940又签订了一个叫XXX的条约”,如果模型一般,便会拿取同一个句中的XXX条约名当作问题的答案,但其实这个问题的答案根本在文中没有出现。
那我们怎么让机器做到这件事情呢?

其实,在最原始的BERT里就有试着解这个问题了,在文章里面加入一个特别的token “Null”。接下来就和抽取式QA一样,根据问题和文章给文中每一个token一个作为起始和终止的分数,如果最后“Null”起始的分数和终止的分数都是最大的,那么“Null”便是指这个问题没有答案。在BERT中[CLS]就是当作Null的token了。
但其实在实作中,还需要加很多条件。举例来说,我们在训练时很难得到Null作为起始和终止的分数都最高的状况,所以一般只要Null的起始和终止都超过某一个阈值分数就作为答案,这个阈值分数就作为超参数调节。

当然,还有很多其他的做法,如上图下侧,举例来说,一种直觉的做法是我们另外加一个module 模块,来决定这个问题能不能被回答,这个module 模块会通过文章和问题来判断问题能否被回答,二分类问题。
还有另外一种方法,如上图上侧,这种方法还考虑了答案,也许模型能够给出荒谬的答案,这个答案和问题不匹配。这样来判断问题能否被回答。
II Source QA任务中的来源
2.1 Internet 来源为文字资料

最常见的是根据一篇文章找出其中的答案,但是这个设置有些不切实际,看一篇文中找答案是比较简单的。所以真正使用QA的情况可能是这样的,如上图,我们有这样的问题Q,但我们不是从某一篇文章中找答案,而是从整个网络中找,因此整个网络资料都是我们的来源。
如在DrQA中将维基百科当作来源,所以我们现需要一个搜寻的module 模块,找出有可能包含答案和问题比较相关的文章。然后根据这些相关的文章和问题来决定答案。在刚刚讲到的MS MARCO 和 DuReader数据集也是如此设置的,每一个问题都提供了数篇文章,要从这些文章找出正确答案。
那这些相关文章从哪里来呢?用一个搜索引擎搜索问题,将前十篇文章拿出来作为相关文章即可。但这样也会遇到一个问题,搜索引擎搜到的文章不是都有正确答案的,所以对QA模型要先判断能否从现在的文章中得到正确答案,而怎么滤掉哪些不相关的文章也是一个值得研究的问题。

举例来说,有这样一个模型,V-Net根据输入的问题和多篇文章得到多个答案 A 1 , A 2 , . . . , A n A_1,A_2,...,A_n A1,A2,...,An,而选择哪一个作为最终答案,在V-Net中的方法是投票的方式,如十篇文章中八篇都得到了一样的答案,那么这个答案就作为我们的最终答案输出。
2.2 Visual 来源为图片

除了文字,还有其他可能的类型当作来源,如上图的图片作为来源。而比较常见的解法就是把一张图片丢到CNN里面,CNN就会给图片的每一小块一个向量表示,所以一张图片也是表示成一堆向量。类似于一篇文章输给BERT后得到的就是一堆embedding词向量的序列。接下来用到QA的方法和文字一样。
2.3 Audio 来源为语音

其实声音也包含了十分丰富的资讯,那怎么做语音的QA呢?最简单的方法是先做语音辨识,把声音讯号转成对应文字,然后通过文字版QA解决。
在还没有SQuAD时,当年在老师实验室,便通过大量托福听力测验的考古题来训练了一个模型,根据语音和问题进行选择。在出现文字版SQuAD后,实验室便创造了语音版的SQuAD。

那在解决语音QA时,通常会用到语音辨识,但语音辨识的结果可能并不准确。因此有这样的前沿研究,如上图左侧,也许对于语音QA,并不需要读文字,而是使用 Subword Units 子词单位 ,比如说以中文为例,“chengshi”的发音可能被辨识为“城市或程式”,如果以字为单位,那这两种结果是完全不一样的。但是如果以重音符号为分割,将整段声音经此拆分为多个子词单位,这样语音QA效果更好。
另外一个技术是使用对抗学习的方法,如上图右侧,语音QA的数据比较少,但文字的QA数据很多,对于文字QA是没有语音辨识的错误问题的,因此我们期待可以通过对抗学习的方法用文字QA来辅助语音QA的训练。

但更进一步,我们真的需要语音辨识吗?有没有可能跳过语音辨识,做一个端到端的语音QA,SpeechBERT便是如此,“硬train一发”。当然,这样做得到的正确率是差于做语音辨识的语音版QA的。但这两种是可以互补使用的,在语音辨识部分效果差的语音QA便通过这种端到端的方法解决,语音辨识部分效果好的依旧是文字版QA。
2.4 Movie 来源为多种

刚刚上述讲的来源都是来自同一种类型的,那有没有可能从多个来源来训练QA呢?
有这样一种Movie QA,它的来源有影像(图片)、字幕(文字)、音频(声音)。回答一个问题是来自这三种资讯的,不过后来比赛发现文字资讯太强了,影像和音频几乎没有帮助。
本篇介绍了QA中答案和来源的内容,下一篇将是有关问题的部分。