背景

蘑菇街旨在做一家高科技轻时尚的互联网公司,公司的核心宗旨就是购物与社区的相互结合,为更多消费者提供更有效的购物决策建议。
蘑菇街上每天有几百万网友在这里交流时尚、购物的话题,相互分享,这些行为会产生大量的数据,当这些数据源产生数据后,需要有一个组件获取数据源的数据,将数据写到 kafka,蘑菇街研发团队以往的解决办法,一是通过 Lofstash、Filebeat 等开源的数据存储方案处理,二是自己写代码实现这种逻辑。
开始数据量小的时候还可以,随着业务的不断扩张,数据越来越大,为了保障可用性、可靠性以及性能相关的内容,需要大量的研发资源投入,因此,亟待新的解决方案支持。
CKafka 全称是 Tencent Cloud Kafka ,是一款适合公有云部署、运行、运维的分布式、高可靠、高吞吐和高可扩展的消息队列系统。它 100% 兼容开源的 Kafka API,目前主要支持开源的 0.9, 0.10, 1.1.1, 2.4.2 四个大版本,并提供向下兼容的能力。
目前 Tencent Cloud Kafka 维护了近万节点的集群,堆积数据达到了 PB 级。是一款集成了租户隔离、限流、鉴权、安全、数据监控告警、故障快速切换、跨可用区容灾等等一系列特性的,历经大流量检验的、可靠的公有云上 Kafka 集群。
CKafka 目前服务对象包括拼多多、微信、哔哩哔哩,以及腾讯内部的一些大的应用,包括腾讯视频、微视等。
蘑菇街的选择
蘑菇街团队对比市场上的技术解决方案,从学习成本、扩缩容能力以及人工维护成本和稳定性方面考虑。
腾讯云 Serverless 云函数具有天然的优势:
- 支持多语言
- 学习成本低,不需要学习开源方案,不需要学习分布式调度
- 无限的弹性扩容能力
- 多重触发方式,事件触发、定时触发、主动触发
- 集群稳定性和可用性的维护成本几乎没有
- 按实际用量计费,1ms计费,费用很低
同时,腾讯云 Serverless 云函数+ Ckafka 提供自建的 UI 交互界面,可进行流量告警配置,同时控制台上可进行扩容配置且安全可靠。
腾讯云 Serverless 团队为蘑菇街提供的业务解决方案,是通过云函数将一个实例中某个 Topic 的消息转储至另一个实例对应的 Topic上,对比原来的 Connector 方案,腾讯云云函数 SCF 能够通过腾讯云控制台进行管理,能控制触发阈值,触发开关等,可以很方便地对每个函数进行管理。简单来讲,
- 消息转储:将 Topic 的消息同步至离线集群
- 集群迁移:在集群迁移合并的过程中起到一个双写的作用

经过对比,腾讯云 Serverless 云函数 + Ckafka 是最优的解决方案,蘑菇街最终决定选择使用腾讯云 Serverless 云函数 + Ckafka 运用在的消息同步业务上。
腾讯云 Serverless 云函数 + Ckafka 解决方案的优势
Kafka 社区的繁荣,让越来越多的电商用户开始使用 Kafka 来做日志收集、大数据分析、流式数据处理等。而公有云上的产品 Ckafka 也借助了开源社区的力量,和云函数结合,推出了非常实用的功能,其优化点包括:
- 基于 ApacheKafka 的分布式、高可扩展、高吞吐
- 100% 兼容 Apache KafkaAPI(0.9 及 0.10)
- 无需部署,直接使用 Kafka 所有功能
- Ckafka 封装所有集群细节,无需用户运维
- 支持动态升降实例配置,按照需求付费(开发中)
- 对消息引擎优化,性能比社区最高提升 50%
如下图,云函数可以实时消费 Ckafka 中的消息,比如做数据转存、日志清洗、实时消费等。并且,像数据转存的功能已经集成到了 Ckafka 的控制台上,用户可以一键开启使用,大大降低了用户使用的复杂度。
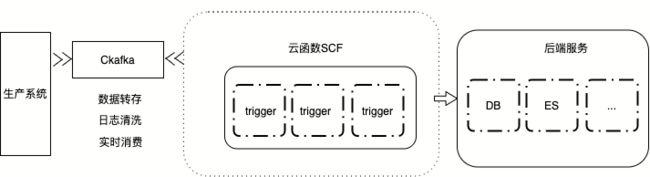
对比使用云主机自建 Ckafka Consumer 的方式,云函数帮用户屏蔽掉了很多不必要的开销:
- 云函数控制台上可以一键开启 Ckafka 触发器,帮助用户自动创建 Consumer,并由云函数平台来维护组建的高可用;
- Ckafka 触发器自身支持很多实用的配置:支持配置 offset 位置、支持配置1~1万消息聚合条数、支持配置 1~1万次重试次数等;
- 基于云函数开发的业务逻辑,天然支持弹性伸缩,无需额外搭建和维护服务器集群等。
腾讯云 Serverless ETL 通用数据处理能力
互联网竞争日益激烈,无论是蘑菇街还是其他产品都在寻找新的突破,当产品团队尝试做产品迭代或者产品新功能时,初期要做一些新项目的验证,数据拉取、数据分析自然是必要的。
这部分的数据需求可能会给团队带来很大的压力,一方面,对已有数据处理的主流程和数据结构有适配成本,需要考虑稳定性的风险,这部分需要投入大量的人力和时间成本;另一方面,由于这个过程时间周期比较长的,可能会影响迭代的速度,赶不上竞品。
这个时候不妨试试腾讯云 Serverless 云函数,前面提到的 CKafka -> SCF -> CKafka 只是腾讯云 Serverless 云函数支持的 ETL 场景中的一条链路,Serverless 云函数能支持通用的数据处理。
ETL 场景是指业务上需要做数据抽取(Extract)、数据转换(Transform)、数据加载(Load)的场景。腾讯云 Serverless 云函数在这方面有很大的优势:
- 更轻量,无需要购买服务器,即可实现产品快速迭代中数据方面的需求。
- 更快速实现,由于学习成本低,数据团队只需很轻松地写个脚本,上下游链接一下数据源,中间做一些数据逻辑即可。
- 费用成本低,云函数 1ms 计费原则,且只对运行的函数付费,对于有波峰波谷的业务场景,在成本方面更是节省很多。
- 灵活,不影响已经有项目的数据处理流程,可单独运行并满足数据验证需求。
- 省心,从数据抓取、转存、分析、报表,全流程都实现了。

实战部署
说了这么多,一起来实战,了解了原理,操作起来其实也是非常简单了。
前置条件
以广州地域为例:
- 开启 Elasticsearch 服务
- 开启 Ckafka 服务
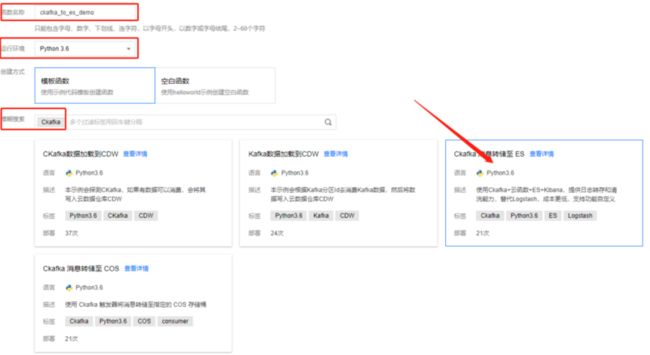
1. 创建云函数
登录云函数控制台,选择地域后,新建函数,选择运行环境Python3.6,搜索“Ckafka”,选中模板函数后,下一步。
在下一步中,点开高级设置:配置环境变量,如下:
必填参数:
ES_Address,ES_User,ES_Password,ES_Index_KeyWord可选填入:
ES_Log_IgnoreWord(需要删除的关键词,缺省则全量写入,如填name,password)ES_Index_TimeFormat(按照天或者小时设置Index,缺省则按照天建立索引,如填hour)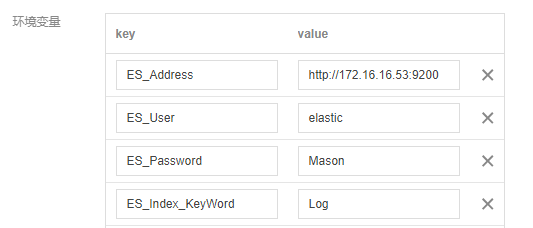
在高级设置中,配置私有网络,需要选择和 ES 相同 VPC,完成函数创建。

2. 创建 Ckafka 触发器
在函数的【触发管理】页面,创建触发器,配置对应 Topic 的触发方式,提交后即可生效。

3. 查看 ES 和函数运行日志
- 查看函数运行日志
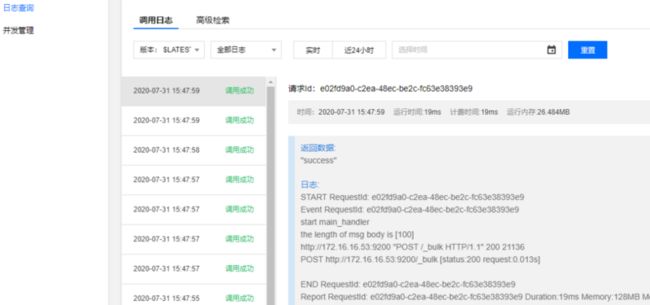
- 查看 Kibana
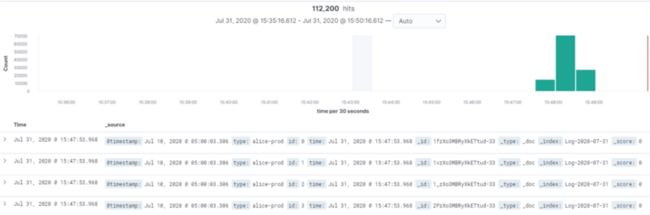
- 扩展能力介绍
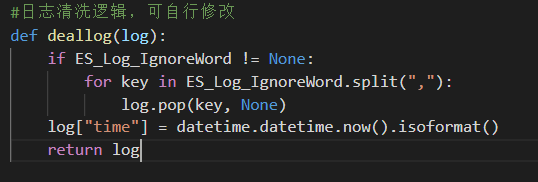
如果想要实现高级日志清洗逻辑,可直接在函数代码中修改逻辑。
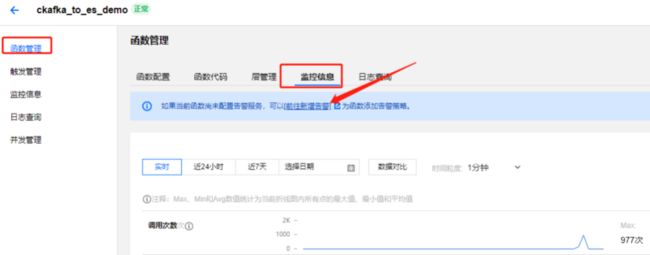
针对函数的运行状态,可以自行配置监控告警,实时感知业务运行情况。
One More Thing
立即体验腾讯云 Serverless Demo,领取 Serverless 新用户礼包 serverless/start
欢迎访问: Serverless 中文网!