人工智能的本质:最优化 (神经网络优化算法python手写实现)
人工智能的本质就是最优化。假设把任务比作是一碗饭,
传统的解决方法,就是根据数学公式,然后一口气吃完饭,如果饭碗小,数学公式还行,如果饭碗大,数学公式能一口吃完饭吗?
人工智能的本质就是最优化,得益于有很多优化算法,优化算法等于是一口一口吃饭,再大的饭碗,再多的饭,也能干。
本文以一元线性回归为例,
通过代码来感受下神经网络的优化算法。
一.梯度下降算法SGD
梯度下降是一种非常通用的优化算法。
假设在浓雾下,你迷失在了大山中,你只能感受到自己脚下的坡度,为了最快到达山底,最好的方法就是沿着坡度最陡的地方下山。这就是梯度下降。它计算误差函数关于参数θ 的局部梯度,同时它沿着梯度下降的方向进行下一次迭代,当梯度值为0的时候,就达到误差函数最小值。
具体来说,开始时,需要指定一个随机的θ ,然后逐渐去改进它,每次变化一小步,每一次都试着降低损失函数,直到算法收敛到一个最小值。
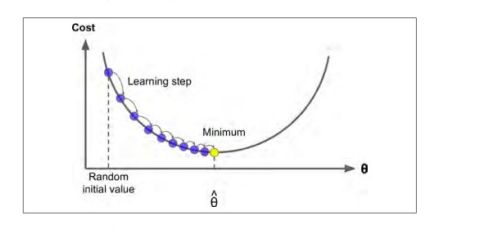
在梯度下降中一个最重要的参数就是步长,也叫学习率
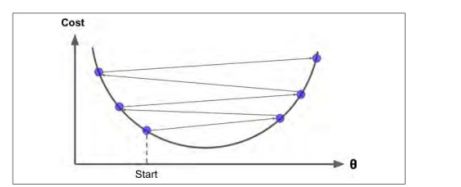
如果学习率太小,则需要多次迭代才能达到最小值。

如果学习率太大,可能跳过最小值,很难收敛。
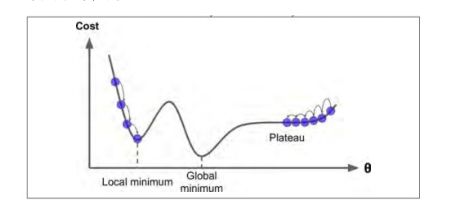
并不是所有的损失函数都是一个V型,有的像山脊等各种不规则地形。如果早早地结束训练可能会陷入局部最小值,所以这时需要指定训练轮数,当轮数过大,才有可能得到全局最小值。
线性目标函数为
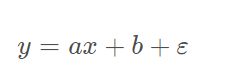

线性回归损失函数为
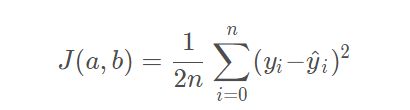 优化函数
优化函数
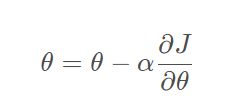 对于一元线性回归的优化函数为:
对于一元线性回归的优化函数为:
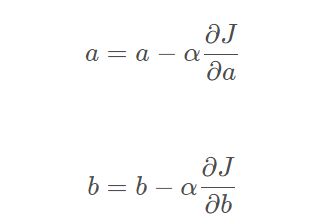

import numpy as np
import matplotlib.pyplot as plt
#定义线性回归
def model(a, b, x):
return a*x + b
#损失函数
def cost_function(a, b, x, y):
n = 5#5个样本,后面举例的数据为5个样本
return 0.5/n * (np.square(y-a*x-b)).sum()
#梯度下降
#梯度下降
def sgd(a,b,x,y):
n = 5#5个样本
alpha = 1e-1
y_hat = model(a,b,x)#预测值
da = (1.0/n) * ((y_hat-y)*x).sum()
db = (1.0/n) * ((y_hat-y).sum())
a = a - alpha*da
b = b - alpha*db
return a, b
#定义数据 5个样本
x=np.array([1,2,3,4,5])
y=np.array([2.1,4.2,5.9,7.8,10.2])
def train():
# 初始化参数
a = np.random.random()
b = np.random.random()
n_iterations = 10000 # 轮数
print('初始值 a,b', a, b)
for i in range(n_iterations):
a, b= sgd(a, b, x, y)
cost=cost_function(a,b,x,y)
if np.abs(cost)<0.01:
break
return a,b,i
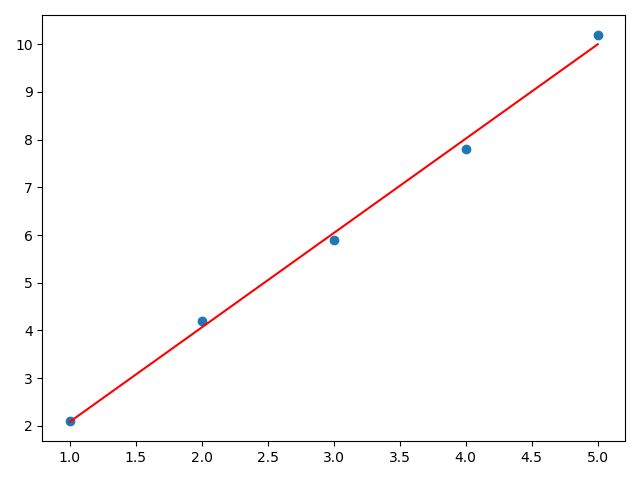
a,b,i=train()
print('a,b,i',a,b,i)
y1=np.dot(x,a)+b
plt.scatter(x,y)
plt.plot(x,y1,color='red',)
plt.show()

二.动量优化Momentum
梯度下降算法只是通过直接减去损失函数J(θ)相对于θ的梯度,乘以学习率η来更新权重θ,方程是θ=θ-η∇J(θ)。它不关心早期的梯度是什么,如果局部梯度很小,则会非常缓慢。
动量优化Momentum很关心之前的梯度,在每次迭代时,它将动量矢量m(乘以学习率β)与局部梯度相加,并通过简单地减去或加上该动量矢量来更新权重。换句话讲,梯度作用于加速度,不作用于速度,人为引入了一个初速度βm。
公式为
 其中的β类似于摩擦系数,一般取0.9,m为动量。
其中的β类似于摩擦系数,一般取0.9,m为动量。
import numpy as np
import matplotlib.pyplot as plt
#定义线性回归
def model(a, b, x):
return a*x + b
#损失函数
def cost_function(a, b, x, y):
n = 5#5个样本,后面举例的数据为5个样本
return 0.5/n * (np.square(y-a*x-b)).sum()
#动量优化
def nesterov(a, b, ma, mb, x, y):
n = 5#5个样本
alpha = 1e-1
beta = 0.1
y_hat = model(a,b,x)
da = (1.0/n) * ((y_hat-y)*x).sum()
db = (1.0/n) * ((y_hat-y).sum())
ma = beta*ma + alpha*da#动量矢量,其中beta*ma 控制速度,alpha*da控制加速度
mb = beta*mb + alpha*db#动力矢量
a = a - ma#权重参数更新
b = b - mb#权重参数更新
return a, b, ma, mb
#定义数据 5个样本
x=np.array([1,2,3,4,5])
y=np.array([2.1,4.2,5.9,7.8,10.2])
def train():
# 初始化参数
a = np.random.random()
b = np.random.random()
n_iterations = 10000 # 轮数
print('初始值 a,b', a, b)
for i in range(n_iterations):
a, b, ma, mb = nesterov(a, b, 0.9, 0.9, x, y)
cost=cost_function(a,b,x,y)
if np.abs(cost)<1:
break
return a,b,i
a,b,i=train()
print('a,b,i',a,b,i)
y1=np.dot(x,a)+b
plt.scatter(x,y)
plt.plot(x,y1,color='red',)
plt.show()
ma = betama + alphada#动量矢量,其中betama 控制速度,alphada控制加速度
合理选择速度
数据量大还行,数据量小我感觉效果不如梯度下降


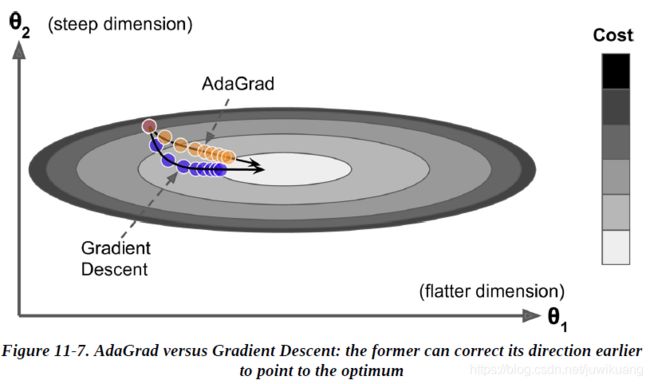
三.AdaGrad
在图中,蓝色的为梯度下降,它朝着梯度最大的方向快速前进,而不是朝着全局最后前进。黄色的是AdaGrad,它指向的是全局最优。它的办法是缩小(scaling down)最大的梯度参数。

import numpy as np
import matplotlib.pyplot as plt
#定义线性回归
def model(a, b, x):
return a*x + b
#损失函数
def cost_function(a, b, x, y):
n = 5#5个样本,后面举例的数据为5个样本
return 0.5/n * (np.square(y-a*x-b)).sum()
#ada_grad
def ada_grad(a,b,sa, sb, x,y):
epsilon=1e-10
n = 5#5个样本
alpha = 1e-1
y_hat = model(a,b,x)
da = (1.0/n) * ((y_hat-y)*x).sum()
db = (1.0/n) * ((y_hat-y).sum())
sa=sa+da*da + epsilon
sb=sb+db*db + epsilon
# da,db随着轮数变小,sa,sb大趋势随着轮数变大
a = a - alpha*da / np.sqrt(sa)
b = b - alpha*db / np.sqrt(sb)
return a, b, sa, sb
#定义数据 5个样本
x=np.array([1,2,3,4,5])
y=np.array([2.1,4.2,5.9,7.8,10.2])
def train():
# 初始化参数
a = np.random.random()
b = np.random.random()
n_iterations = 10000 # 轮数
print('初始值 a,b', a, b)
for i in range(n_iterations):
a, b, sa, sb = ada_grad(a, b, 0.9, 0.9, x, y)
cost=cost_function(a,b,x,y)
if np.abs(cost)<0.1:
break
return a,b,i,sa,sb
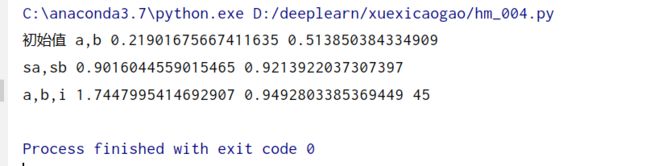
a,b,i,sa,sb=train()
print('sa,sb',sa,sb)
print('a,b,i',a,b,i)
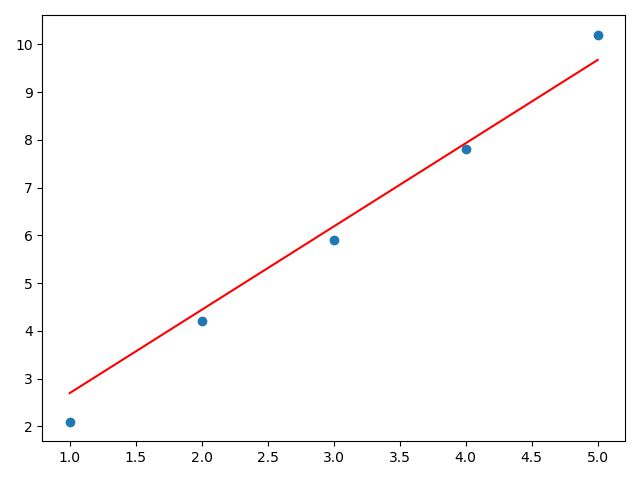
y1=np.dot(x,a)+b
plt.scatter(x,y)
plt.plot(x,y1,color='red',)
plt.show()
解析:
sa=sa+dada + epsilon,sb=sb+dbdb + epsilon 会随着轮数越来越大,然后导致学习率1/ np.sqrt(sa) 越来越小,权重更新得越慢。即开始时学习率比较大,后面学习率较小,学习率一直在变,是一种自适应学习率。
四.RMSProp
尽管AdaGrad的速度变慢了一些,并且从未收敛到全局最优。
AdaGrad 权重更新,学习率累积的时训练以来的所以梯度(sa累积的是所有的da,sb累积的是所有的db)
AdaGrad 中
sa=sa+dada + epsilon
sb=sb+dbdb + epsilon
a = a - alphada / np.sqrt(sa)
b = b - alphadb / np.sqrt(sb)
da,db总体上会随着轮数越来越小,,sa,sb随着轮数变大
1/ np.sqrt(sa),1/ np.sqrt(sb) 学习率随着轮数变小,容易陷入局部最小值,(因为当它局部最小值附近时,da小,学习率也小,很难爬出小凹谷)
RMSProp 通过仅累积最近迭代的(da,db)的梯度来修正这个问题,它通过在第一步中使用指数衰减来实现。

相比于AdaGrad ,RMSProp就是在AdaGrad基础上减缓学习率[1 / np.sqrt(sa) 和1/ np.sqrt(sb) ]的变化。
import numpy as np
import matplotlib.pyplot as plt
#定义线性回归
def model(a, b, x):
return a*x + b
#损失函数
def cost_function(a, b, x, y):
n = 5#5个样本,后面举例的数据为5个样本
return 0.5/n * (np.square(y-a*x-b)).sum()
#rmsprop
def rmsprop(a,b,sa, sb, x,y):
epsilon=1e-10
beta = 0.9
n = 5#本文5个样本数据
alpha = 1e-1
y_hat = model(a,b,x)
da = (1.0/n) * ((y_hat-y)*x).sum()
db = (1.0/n) * ((y_hat-y).sum())
sa=beta*sa+(1-beta)*da*da + epsilon
sb=beta*sb+(1-beta)*db*db + epsilon
#da,db会随着轮数越来越小,sa,sb,大趋势变小
a = a - alpha*da / np.sqrt(sa)
b = b - alpha*db / np.sqrt(sb)
return a, b, sa, sb
#定义数据 5个样本
x=np.array([1,2,3,4,5])
y=np.array([2.1,4.2,5.9,7.8,10.2])
def train():
# 初始化参数
a = np.random.random()
b = np.random.random()
n_iterations = 10000 # 轮数
print('初始值 a,b', a, b)
for i in range(n_iterations):
a, b, sa, sb = rmsprop(a, b, 0.9, 0.9, x, y)
cost=cost_function(a,b,x,y)
if np.abs(cost)<0.1:
break
return a,b,i,sa,sb
a,b,i,sa,sb=train()
print('sa,sb',sa,sb)
print('a,b,i',a,b,i)
y1=np.dot(x,a)+b
plt.scatter(x,y)
plt.plot(x,y1,color='red',)
plt.show()
解析
sa=betasa+(1-beta)dada + epsilon. beta=0.9,现在=0.9以前的+0.1的现在梯度。
sa=betasa+(1-beta)dada + epsilon
sb=betasb+(1-beta)dbdb + epsilon
#da,db总体上会随着轮数越来越小,sa,sb,大趋势变小。学习率1 / np.sqrt(sa)变大
a = a - alphada / np.sqrt(sa)
b = b - alpha*db / np.sqrt(sb)
当处于局部最小值附近时,学习率足够大,容易爬出小凹谷。


五.Adam
简而言之,Adam使用动量和自适应学习率来加快收敛速度。
Momentum (动量)
在解释动量时,研究人员和从业人员都喜欢使用比球滚下山坡而向局部极小值更快滚动的类比法,但从本质上讲,我们必须知道的是,动量算法在相关方向上加速了随机梯度下降,如 以及抑制振荡。
为了将动量引入我们的神经网络,我们将时间元素添加到过去时间步长的更新向量中,并将其添加到当前更新向量中。 这样可以使球的动量增加一定程度。 可以用数学表示,如下图所示。
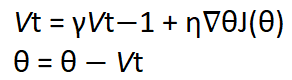
动量更新方法,其中θ是网络的参数,即权重,偏差或激活值,η是学习率,J是我们要优化的目标函数,γ是常数项,也称为动量。 Vt-1(注意t-1是下标)是过去的时间步长,而Vt(注意t是下标)是当前的时间步长。
动量项γ通常被初始化为0.9
适应性学习率
通过将学习率降低到我们在AdaGrad,RMSprop,Adam和AdaDelta中看到的预定义时间表(schedule),可以将自适应学习率视为训练阶段的学习率调整。这也称为学习率时间表 有关该主题的更多详细信息
在不花太多时间介绍AdaGrad优化算法的情况下,这里将解释RMSprop及其在AdaGrad上的改进以及如何随时间改变学习率。
RMSprop(即均方根传播)其目的是解决AdaGrad的学习率急剧下降的问题。 简而言之,RMSprop更改学习速率的速度比AdaGrad慢,但是RMSprop仍可从AdaGrad(更快的收敛速度)中受益-数学表达式请参见下图

E [g²] t的第一个方程是平方梯度的指数衰减平均值。 Geoff Hinton建议将γ设置为0.9,而学习率η的默认值为0.001
这可以使学习率随着时间的流逝而适应,这很重要,因为这种现象也存在于Adam中。 当我们将两者(Momentum 和RMSprop)放在一起时,我们得到了Adam

import numpy as np
import matplotlib.pyplot as plt
#定义线性回归
def model(a, b, x):
return a*x + b
#损失函数
def cost_function(a, b, x, y):
n = 5#5个样本,后面举例的数据为5个样本
return 0.5/n * (np.square(y-a*x-b)).sum()
#Adam
def adam(a, b, ma, mb, sa, sb, t, x, y):
epsilon = 1e-10
beta1 = 0.9
beta2 = 0.9
n = 5#5个样本
alpha = 1e-1
y_hat = model(a, b, x)
da = (1.0 / n) * ((y_hat - y) * x).sum()#计算梯度a
db = (1.0 / n) * ((y_hat - y).sum())#计算梯度b
ma = beta1 * ma - (1 - beta1) * da#计算动量ma
mb = beta1 * mb - (1 - beta1) * db#计算动量mb
sa = beta2 * sa + (1 - beta2) * da * da#自适应sa
sb = beta2 * sb + (1 - beta2) * db * db#自适应sb
ma_hat = ma / (1 - beta1 ** t)#动量添加指数
mb_hat = mb / (1 - beta1 ** t)#动量添加指数
sa_hat = sa / (1 - beta2 ** t)#自适应添加指数
sb_hat = sb / (1 - beta2 ** t)#自适应添加指数
a = a + alpha * ma_hat / np.sqrt(sa_hat)#权重更新
b = b + alpha * mb_hat / np.sqrt(sb_hat)
return a, b, ma, mb, sa, sb
#定义数据 5个样本
x=np.array([1,2,3,4,5])
y=np.array([2.1,4.2,5.9,7.8,10.2])
def train():
# 初始化参数
a = np.random.random()
b = np.random.random()
n_iterations = 10000 # 轮数
print('初始值 a,b', a, b)
for i in range(n_iterations):
a, b, ma,mb,sa, sb = adam(a, b, 0.05, 0.05, 0.9,0.9,1000,x, y)
cost=cost_function(a,b,x,y)
if np.abs(cost)<0.1:
break
return a,b,i,sa,sb
a,b,i,sa,sb=train()
print('sa,sb',sa,sb)
print('a,b,i',a,b,i)
y1=np.dot(x,a)+b
plt.scatter(x,y)
plt.plot(x,y1,color='red',)
plt.show()
解析
adam(a, b, ma, mb, sa, sb, t, x, y):
中的ma,mb控制初速度,要不要一来就梯度更新得很快(数据量大时可以考虑较大的ma,mb) 做学习率的分子
sa,sb控制权重更新速度,越大更新越慢,做学习率的分母


本文主要参考文献如下,感谢大佬。
1.Adam 优化算法详解
2.https://blog.csdn.net/juwikuang/article/details/108039680
、、、、、、、、、、、、、、、、、、、、、、、、、、、、
常用优化算法就这些,还有其他的未列举。
我也感觉似懂非懂,唉。
![]()
电气工程的计算机萌新:余登武。
写博文不容易,如果你觉得本文对你有用,请点个赞支持下,谢谢。
![]()