通过kubernetes构建容器云平台第二篇,最近刚好官方发布了V1.19.0,本文就以最新版来介绍通过kubeadm安装高可用的kubernetes集群。
市面上安装k8s的工具很多,但是用于学习的话,还是建议一步步安装,了解整个集群内部运行的组件,以便后期学习排错更方便。。。
本文环境如下:
服务器:3台
操作系统:CentOS 7
拓扑图就不画了,直接copy官网的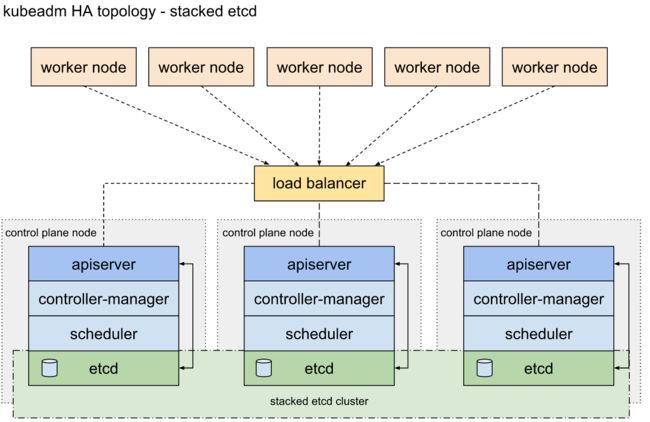
###概述
简单说下这个图,三台服务器作为master节点,使用keepalive+haproxy对apiserver进行负载均衡,node节点和apiserver通信通过VIP进行。第一篇说过,集群的所有信息存在ETCD集群中。
接下来,开干。。。
###配置源
这边配置了三种源,全部替换从国内的镜像源,以加快安装包的速度。
# 系统源
curl -O http://mirrors.aliyun.com/repo/Centos-7.repo
# docker源
curl -O https://mirrors.ustc.edu.cn/docker-ce/linux/centos/docker-ce.repo
sed -i 's/download.docker.com/mirrors.ustc.edu.cn\/docker-ce/g' docker-ce.repo
# kubernetes源
cat < /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF ###配置系统相关参数
系统配置完源以后,需要对一些参数进行设置,都是官方的推荐,更多优化后期介绍。
# 临时禁用selinux
# 永久关闭 修改/etc/sysconfig/selinux文件设置
sed -i 's/SELINUX=permissive/SELINUX=disabled/' /etc/sysconfig/selinux
setenforce 0
# 临时关闭swap
# 永久关闭 注释/etc/fstab文件里swap相关的行
swapoff -a
# 开启forward
# Docker从1.13版本开始调整了默认的防火墙规则
# 禁用了iptables filter表中FOWARD链
# 这样会引起Kubernetes集群中跨Node的Pod无法通信
iptables -P FORWARD ACCEPT
# 配置转发相关参数,否则可能会出错
cat < /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
vm.swappiness=0
EOF
sysctl --system
# 加载ipvs相关内核模块
# 如果重新开机,需要重新加载
modprobe ip_vs
modprobe ip_vs_rr
modprobe ip_vs_wrr
modprobe ip_vs_sh
modprobe nf_conntrack_ipv4
lsmod | grep ip_vs ###安装kubeadm及其相关软件
yum install -y kubelet kubeadm kubectl ipvsadm###配置docker
主要配置加速下载公有镜像和允许从不安全的私有仓库下载镜像hub.xxx.om需要改成自己的私有仓库地址,如果没有请删除insecure-registries该行vim /etc/docker/daemon.json
{
"registry-mirrors": ["https://ci7pm4nx.mirror.aliyuncs.com","https://registry.docker-cn.com","http://hub-mirror.c.163.com"],
"insecure-registries":["hub.xxx.om"]
}写好配置,重启docker
systemctl restart docker
systemctl enable docker.service查看docker info,输出如下
Insecure Registries:
hub.xxx.com
127.0.0.0/8
Registry Mirrors:
https://ci7pm4nx.mirror.aliyuncs.com/
https://registry.docker-cn.com/
http://hub-mirror.c.163.com/###启动kubelet
systemctl enable --now kubeletkubelet 现在每隔几秒就会重启,因为它陷入了一个等待 kubeadm 指令的死循环。
##安装配置haproxy和keepalive (三台机器都要安装配置)
安装软件包yum install -y haproxy keepalived
配置haproxy
需要注意,手动创建/var/log/haproxy.log文件
[root@k8s-master001 ~]# cat /etc/haproxy/haproxy.cfg
# /etc/haproxy/haproxy.cfg
#---------------------------------------------------------------------
# Global settings
#---------------------------------------------------------------------
global
log /var/log/haproxy.log local0
daemon
#---------------------------------------------------------------------
# common defaults that all the 'listen' and 'backend' sections will
# use if not designated in their block
#---------------------------------------------------------------------
defaults
mode http
log global
retries 1
timeout http-request 10s
timeout queue 20s
timeout connect 5s
timeout client 20s
timeout server 20s
timeout http-keep-alive 10s
timeout check 10s
listen admin_stats
mode http
bind 0.0.0.0:1080
log 127.0.0.1 local0 err
stats refresh 30s
stats uri /haproxy-status
stats realm Haproxy\ Statistics
stats auth admin:admin
stats hide-version
stats admin if TRUE
#---------------------------------------------------------------------
# apiserver frontend which proxys to the masters
#---------------------------------------------------------------------
frontend apiserver
bind *:8443
mode tcp
option tcplog
default_backend apiserver
#---------------------------------------------------------------------
# round robin balancing for apiserver
#---------------------------------------------------------------------
backend apiserver
option httpchk GET /healthz
http-check expect status 200
mode tcp
option ssl-hello-chk
balance roundrobin
server k8s-master001 10.26.25.20:6443 weight 1 maxconn 1000 check inter 2000 rise 2 fall 3
server k8s-master002 10.26.25.21:6443 weight 1 maxconn 1000 check inter 2000 rise 2 fall 3
server k8s-master003 10.26.25.22:6443 weight 1 maxconn 1000 check inter 2000 rise 2 fall 3####启动haproxy
systemctl start haproxy
systemctl enable haproxy
###配置keepalived
[root@k8s-master001 ~]# cat /etc/keepalived/keepalived.conf
! /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id LVS_K8S
}
vrrp_script check_apiserver {
script "/etc/keepalived/check_apiserver.sh"
interval 3
weight -2
fall 10
rise 2
}
vrrp_instance VI_1 {
state MASTER
interface ens18
virtual_router_id 51
priority 100
authentication {
auth_type PASS
auth_pass kubernetes
}
virtual_ipaddress {
10.26.25.23
}
track_script {
check_apiserver
}
}添加keepalive检查脚本
[root@k8s-master001 ~]# cat /etc/keepalived/check_apiserver.sh
#!/bin/sh
errorExit() {
echo "*** $*" 1>&2
exit 1
}
curl --silent --max-time 2 --insecure https://localhost:8443/ -o /dev/null || errorExit "Error GET https://localhost:8443/"
if ip addr | grep -q 10.26.25.23; then
curl --silent --max-time 2 --insecure https://10.26.25.23:8443/ -o /dev/null || errorExit "Error GET https://10.26.25.23:8443/"
fi
chmod +x /etc/keepalived/check_apiserver.sh####启动keepalived
systemctl start keepalived
systemctl enable keepalived现在你可以通过访问masterIP:1080/aproxy-status 访问haproxy管理界面,用户名密码在配置文件中。本文是admin/admin,可以自己修改。
刚开始apiserver的行都是红的,表示服务还未启动,我这里图是后截的,所以是绿的
接下开,开始初始化kubernetes集群
###初始化第一个控制节点master001
[root@k8s-master001 ~]# kubeadm init --control-plane-endpoint 10.26.25.23:8443 --upload-certs --image-repository registry.aliyuncs.com/google_containers --pod-network-cidr 10.244.0.0/16
W0910 05:09:41.166260 29186 configset.go:348] WARNING: kubeadm cannot validate component configs for API groups [kubelet.config.k8s.io kubeproxy.config.k8s.io]
[init] Using Kubernetes version: v1.19.1
[preflight] Running pre-flight checks
[WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[certs] Using certificateDir folder "/etc/kubernetes/pki"
........忽略了部分信息
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Starting the kubelet
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
............忽略了部分信息
[addons] Applied essential addon: CoreDNS
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of the control-plane node running the following command on each as root:
kubeadm join 10.26.25.23:8443 --token f28iti.c5fgj45u28332ga7 \
--discovery-token-ca-cert-hash sha256:81ec8f1d1db0bb8a31d64ae31091726a92b9294bcfa0e2b4309b9d8c5245db41 \
--control-plane --certificate-key 93f9514164e2ecbd85293a9c671344e06a1aa811faf1069db6f678a1a5e6f38b
Please note that the certificate-key gives access to cluster sensitive data, keep it secret!
As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use
"kubeadm init phase upload-certs --upload-certs" to reload certs afterward.
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 10.26.25.23:8443 --token f28iti.c5fgj45u28332ga7 \
--discovery-token-ca-cert-hash sha256:81ec8f1d1db0bb8a31d64ae31091726a92b9294bcfa0e2b4309b9d8c5245db41看到输出如上,代表初始化成功
初始化命令说明:kubeadm init --control-plane-endpoint 10.26.25.23:8443 --upload-certs --image-repository registry.aliyuncs.com/google_containers --pod-network-cidr 10.244.0.0/16
- --control-plane-endpoint 10.26.25.23:8443 这里的10.26.25.23就是keepalived配置的VIP
- --image-repository registry.aliyuncs.com/google_containers 更改了默认下载镜像的地址,默认是k8s.gcr.io,国内下载不了,或者自行爬墙~~~
- --pod-network-cidr 10.244.0.0/16 定义了pod的网段,需要与flannel定义的网段一直,否则在安装flannel时可能会出现flannel的pod一直重启,后面安装flannel的时候会提到
初始化过程简介:
- 下载需要的镜像
- 创建证书
- 创建服务的yaml配置文件
- 启动静态pod
初始化完成以后,现在就可以根据提示,配置kubectl客户端,使用kubernetes了,虽然现在只有一个master节点
开始使用集群
[root@k8s-master001 ~]# mkdir -p $HOME/.kube
[root@k8s-master001 ~]# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@k8s-master001 ~]# sudo chown $(id -u):$(id -g) $HOME/.kube/config
[root@k8s-master001 ~]# kubectl get no
NAME STATUS ROLES AGE VERSION
k8s-master001 NotReady master 105s v1.19.0现在可以看到集群中只有一个节点,状态为NotReady,这是因为网络插件还没有安装
接下来安装网络插件Flannel
###Flannel安装
下载安装需要的yalm文件:wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/k8s-manifests/kube-flannel.yml
因为现在安装的是最新版本的kubernetes,rbac的api版本需要修改为rbac.authorization.k8s.io/v1,DaemonSet的api版本改为 apps/v1,同时添加selector,这里只贴出配置的一部分。
[root@k8s-master001 ~]# cat kube-flannel.yml
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: kube-flannel-ds
namespace: kube-system
labels:
tier: node
app: flannel
spec:
selector:
matchLabels:
tier: node
app: flannel
template:
metadata:
labels:
tier: node
app: flannel
接下来,通过kubectl安装Flannel,并通过kubectl查看flannel pod的状态是否运行。
kubectl apply -f kube-flannel.yaml
[root@k8s-master001 ~]# kubectl get no
NAME STATUS ROLES AGE VERSION
k8s-master001 Ready master 6m35s v1.19.0
[root@k8s-master001 ~]# kubectl get po -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-6d56c8448f-9cr5l 1/1 Running 0 6m51s
coredns-6d56c8448f-wsjwx 1/1 Running 0 6m51s
etcd-k8s-master001 1/1 Running 0 7m
kube-apiserver-k8s-master001 1/1 Running 0 7m
kube-controller-manager-k8s-master001 1/1 Running 0 7m
kube-flannel-ds-nmfwd 1/1 Running 0 4m36s
kube-proxy-pqrnl 1/1 Running 0 6m51s
kube-scheduler-k8s-master001 1/1 Running 0 7m可以看到一个名字叫kube-flannel-ds-nmfwd的pod,状态为running,表示flannel已经安装好了
因为现在只有一个节点,只看到一个flannel的pod,后面继续添加另外两个节点,就会看到更多的pod了
接下来继续添加master节点
###添加另外控制节点master002,master003
因为现在已经有一个控制节点,集群已经存在,只需要将剩下的机器添加到集群中即可,添加信息在刚在初始化节点的时候输出中可以看到,命令如下
因为输出太多,这里会删除一部分不重要的输出信息
在master002上操作:
[root@k8s-master002 ~]# kubeadm join 10.26.25.23:8443 --token f28iti.c5fgj45u28332ga7 --discovery-token-ca-cert-hash sha256:81ec8f1d1db0bb8a31d64ae31091726a92b9294bcfa0e2b4309b9d8c5245db41 --control-plane --certificate-key 93f9514164e2ecbd85293a9c671344e06a1aa811faf1069db6f678a1a5e6f38b
[preflight] Running pre-flight checks
[WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -oyaml'
[preflight] Running pre-flight checks before initializing the new control plane instance
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[download-certs] Downloading the certificates in Secret "kubeadm-certs" in the "kube-system" Namespace
..............
To start administering your cluster from this node, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Run 'kubectl get nodes' to see this node join the cluster.看到这样的输出,表示添加成功了。
现在来查看下集群节点信息
[root@k8s-master002 ~]# kubectl get no
NAME STATUS ROLES AGE VERSION
k8s-master001 Ready master 21m v1.19.0
k8s-master002 Ready master 6m5s v1.19.0从输出能看到两个master节点,添加master003节点操作和master002一样,不再多说
最后三个节点全部添加以后,通过kubectl可以看到集群的具体信息
[root@k8s-master003 ~]# kubectl get no
NAME STATUS ROLES AGE VERSION
k8s-master001 Ready master 25m v1.19.0
k8s-master002 Ready master 10m v1.19.0
k8s-master003 Ready master 26s v1.19.0最后查看现在运行的所有pod
[root@k8s-master003 ~]# kubectl get po -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-6d56c8448f-9cr5l 1/1 Running 0 27m
coredns-6d56c8448f-wsjwx 1/1 Running 0 27m
etcd-k8s-master001 1/1 Running 0 27m
etcd-k8s-master002 1/1 Running 0 8m19s
etcd-k8s-master003 1/1 Running 0 83s
kube-apiserver-k8s-master001 1/1 Running 0 27m
kube-apiserver-k8s-master002 1/1 Running 0 12m
kube-apiserver-k8s-master003 1/1 Running 0 85s
kube-controller-manager-k8s-master001 1/1 Running 1 27m
kube-controller-manager-k8s-master002 1/1 Running 0 12m
kube-controller-manager-k8s-master003 1/1 Running 0 81s
kube-flannel-ds-2lh42 1/1 Running 0 2m31s
kube-flannel-ds-nmfwd 1/1 Running 0 25m
kube-flannel-ds-w276b 1/1 Running 0 11m
kube-proxy-dzpdz 1/1 Running 0 2m39s
kube-proxy-hd5tb 1/1 Running 0 12m
kube-proxy-pqrnl 1/1 Running 0 27m
kube-scheduler-k8s-master001 1/1 Running 1 27m
kube-scheduler-k8s-master002 1/1 Running 0 12m
kube-scheduler-k8s-master003 1/1 Running 0 76s现在可以看到,kubernetes的核心服务apiserver,-controller-manager,scheduler都是3个pod。
以上,kubernetes的master高科用就部署完毕了。
现在你可以通过haproxy的web管理界面,可以看到三个master已经可用了。
###故障排除
如果master初始化失败,或者添加节点失败,可以使用kubeadm reset重置,然后重新安装
#####重置节点
[root@k8s-node003 haproxy]# kubeadm reset
[reset] Reading configuration from the cluster...
[reset] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -oyaml'
W0910 05:31:57.345399 20386 reset.go:99] [reset] Unable to fetch the kubeadm-config ConfigMap from cluster: failed to get node registration: node k8s-node003 doesn't have kubeadm.alpha.kubernetes.io/cri-socket annotation
[reset] WARNING: Changes made to this host by 'kubeadm init' or 'kubeadm join' will be reverted.
[reset] Are you sure you want to proceed? [y/N]: y
[preflight] Running pre-flight checks
W0910 05:31:58.580982 20386 removeetcdmember.go:79] [reset] No kubeadm config, using etcd pod spec to get data directory
[reset] No etcd config found. Assuming external etcd
[reset] Please, manually reset etcd to prevent further issues
[reset] Stopping the kubelet service
[reset] Unmounting mounted directories in "/var/lib/kubelet"
[reset] Deleting contents of config directories: [/etc/kubernetes/manifests /etc/kubernetes/pki]
[reset] Deleting files: [/etc/kubernetes/admin.conf /etc/kubernetes/kubelet.conf /etc/kubernetes/bootstrap-kubelet.conf /etc/kubernetes/controller-manager.conf /etc/kubernetes/scheduler.conf]
[reset] Deleting contents of stateful directories: [/var/lib/kubelet /var/lib/dockershim /var/run/kubernetes /var/lib/cni]
The reset process does not clean CNI configuration. To do so, you must remove /etc/cni/net.d
The reset process does not reset or clean up iptables rules or IPVS tables.
If you wish to reset iptables, you must do so manually by using the "iptables" command.
If your cluster was setup to utilize IPVS, run ipvsadm --clear (or similar)
to reset your system's IPVS tables.
The reset process does not clean your kubeconfig files and you must remove them manually.
Please, check the contents of the $HOME/.kube/config file.一篇内容太多,后续的内容看下篇。。。