简介
prometheus-operator
Prometheus:一个非常优秀的监控工具或者说是监控方案。它提供了数据搜集、存储、处理、可视化和告警一套完整的解决方案。作为kubernetes官方推荐的监控系统,用Prometheus来监控kubernetes集群的状况和运行在集群上的应用运行状况。
Prometheus架构图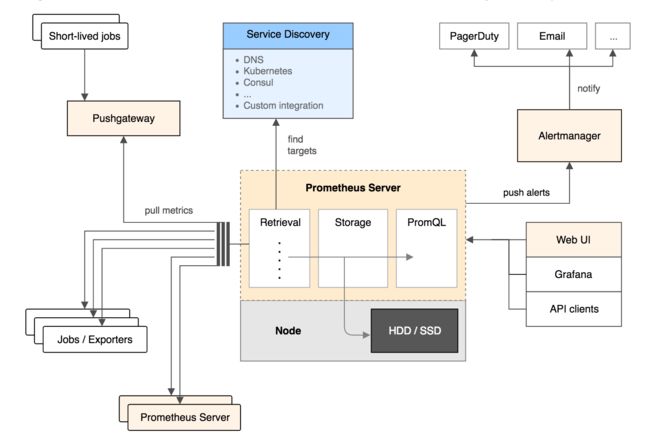
那Prometheus Operator是做什么的呢?
Operator是由CoreOS公司开发的,用来扩展 Kubernetes API,特定的应用程序控制器,它用来创建、配置和管理复杂的有状态应用,如数据库、缓存和监控系统。
可以理解为,Prometheus Operator就是用于管理部署Prometheus到kubernetes的工具,其目的是简化和自动化对Prometheus组件的维护。
Prometheus Operator架构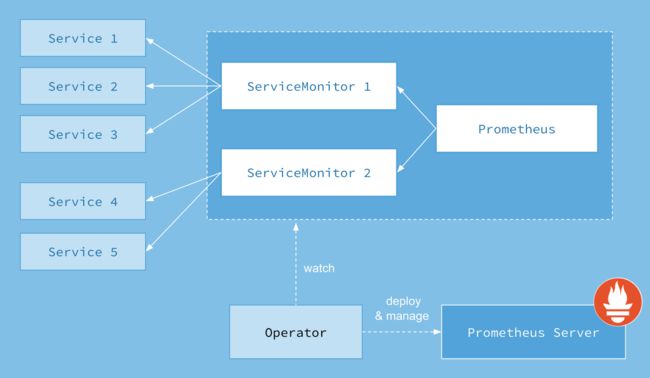
部署前准备
1、克隆kube-prometheus项目
[root@k8s-master001 opt]# git clone https://github.com/prometheus-operator/kube-prometheus.git2、进入kube-prometheus/manifests目录,可以看到一堆yaml文件,文件太多,我们按用组件分类
[root@k8s-master001 manifests]# ls -al
total 20
drwxr-xr-x. 10 root root 140 Sep 14 21:25 .
drwxr-xr-x. 12 root root 4096 Sep 14 21:11 ..
drwxr-xr-x. 2 root root 4096 Sep 14 21:23 adapter
drwxr-xr-x. 2 root root 189 Sep 14 21:22 alertmanager
drwxr-xr-x. 2 root root 241 Sep 14 21:22 exporter
drwxr-xr-x. 2 root root 254 Sep 14 21:23 grafana
drwxr-xr-x. 2 root root 272 Sep 14 21:22 metrics
drwxr-xr-x. 2 root root 4096 Sep 14 21:25 prometheus
drwxr-xr-x. 2 root root 4096 Sep 14 21:23 serviceMonitor
drwxr-xr-x. 2 root root 4096 Sep 14 21:11 setup3、修改yaml文件中的nodeSelector
首先查看下现在Node节点的标签
[root@k8s-master001 manifests]# kubectl get node --show-labels=true
NAME STATUS ROLES AGE VERSION LABELS
k8s-master001 Ready master 4d16h v1.19.0 app.storage=rook-ceph,beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-master001,kubernetes.io/os=linux,node-role.kubernetes.io/master=
k8s-master002 Ready master 4d16h v1.19.0 app.storage=rook-ceph,beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-master002,kubernetes.io/os=linux,node-role.kubernetes.io/master=
k8s-master003 Ready master 4d16h v1.19.0 app.storage=rook-ceph,beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-master003,kubernetes.io/os=linux,node-role.kubernetes.io/master=,role=ingress-controller并把manifests目录的yaml文件中nodeSelector改为kubernetes.io/os=linux
例如:vim setup/prometheus-operator-deployment.yaml,
nodeSelector:
kubernetes.io/os: linux其他的自行修改,可以如下命令过滤并查看是否需要修改
[root@k8s-master001 manifests]# grep -A1 nodeSelector prometheus/*
prometheus/prometheus-prometheus.yaml: nodeSelector:
prometheus/prometheus-prometheus.yaml: nodeSelector:
prometheus/prometheus-prometheus.yaml- kubernetes.io/os: linux部署kube-prometheus
1、安装operator
[root@k8s-master001 manifests]# kubectl apply -f setup/
namespace/monitoring created
customresourcedefinition.apiextensions.k8s.io/alertmanagers.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/podmonitors.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/probes.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/prometheuses.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/prometheusrules.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/servicemonitors.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/thanosrulers.monitoring.coreos.com created
clusterrole.rbac.authorization.k8s.io/prometheus-operator created
clusterrolebinding.rbac.authorization.k8s.io/prometheus-operator created
deployment.apps/prometheus-operator created
service/prometheus-operator created
serviceaccount/prometheus-operator created
[root@k8s-master001 manifests]# kubectl get po -n monitoring
NAME READY STATUS RESTARTS AGE
prometheus-operator-74d54b5cfc-xgqg7 2/2 Running 0 2m40s2、安装adapter
[root@k8s-master001 manifests]# kubectl apply -f adapter/
apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io created
clusterrole.rbac.authorization.k8s.io/prometheus-adapter created
clusterrole.rbac.authorization.k8s.io/system:aggregated-metrics-reader created
clusterrolebinding.rbac.authorization.k8s.io/prometheus-adapter created
clusterrolebinding.rbac.authorization.k8s.io/resource-metrics:system:auth-delegator created
clusterrole.rbac.authorization.k8s.io/resource-metrics-server-resources created
configmap/adapter-config created
deployment.apps/prometheus-adapter created
rolebinding.rbac.authorization.k8s.io/resource-metrics-auth-reader created
service/prometheus-adapter created
serviceaccount/prometheus-adapter created
servicemonitor.monitoring.coreos.com/prometheus-adapter created
[root@k8s-master001 manifests]# kubectl get po -n monitoring
NAME READY STATUS RESTARTS AGE
prometheus-adapter-557648f58c-9x446 1/1 Running 0 41s
prometheus-operator-74d54b5cfc-xgqg7 2/2 Running 0 4m33s3、安装alertmanager
[root@k8s-master001 manifests]# kubectl apply -f alertmanager/
alertmanager.monitoring.coreos.com/main created
secret/alertmanager-main created
service/alertmanager-main created
serviceaccount/alertmanager-main created
servicemonitor.monitoring.coreos.com/alertmanager created
[root@k8s-master001 ~]# kubectl get po -n monitoring
NAME READY STATUS RESTARTS AGE
alertmanager-main-0 2/2 Running 0 53m
alertmanager-main-1 2/2 Running 0 3m3s
alertmanager-main-2 2/2 Running 0 53m4、安装exporter
[root@k8s-master001 manifests]# kubectl apply -f exporter/
clusterrole.rbac.authorization.k8s.io/node-exporter created
clusterrolebinding.rbac.authorization.k8s.io/node-exporter created
daemonset.apps/node-exporter created
service/node-exporter created
serviceaccount/node-exporter created
servicemonitor.monitoring.coreos.com/node-exporter created
[root@k8s-master001 manifests]# kubectl get po -n monitoring
NAME READY STATUS RESTARTS AGE
node-exporter-2rvtt 2/2 Running 0 108s
node-exporter-9kwb6 2/2 Running 0 108s
node-exporter-9zlbb 2/2 Running 0 108s5、安装metrics
[root@k8s-master001 manifests]# kubectl apply -f metrics
clusterrole.rbac.authorization.k8s.io/kube-state-metrics created
clusterrolebinding.rbac.authorization.k8s.io/kube-state-metrics created
deployment.apps/kube-state-metrics created
service/kube-state-metrics created
serviceaccount/kube-state-metrics created
servicemonitor.monitoring.coreos.com/kube-state-metrics created
[root@k8s-master001 manifests]# kubectl get po -n monitoring
NAME READY STATUS RESTARTS AGE
kube-state-metrics-85cb9cfd7c-v9c4f 3/3 Running 0 2m8s6、安装prometheus
[root@k8s-master001 manifests]# kubectl apply -f prometheus/
clusterrole.rbac.authorization.k8s.io/prometheus-k8s created
clusterrolebinding.rbac.authorization.k8s.io/prometheus-k8s created
servicemonitor.monitoring.coreos.com/prometheus-operator created
prometheus.monitoring.coreos.com/k8s created
rolebinding.rbac.authorization.k8s.io/prometheus-k8s-config created
rolebinding.rbac.authorization.k8s.io/prometheus-k8s created
rolebinding.rbac.authorization.k8s.io/prometheus-k8s created
rolebinding.rbac.authorization.k8s.io/prometheus-k8s created
role.rbac.authorization.k8s.io/prometheus-k8s-config created
role.rbac.authorization.k8s.io/prometheus-k8s created
role.rbac.authorization.k8s.io/prometheus-k8s created
role.rbac.authorization.k8s.io/prometheus-k8s created
prometheusrule.monitoring.coreos.com/prometheus-k8s-rules created
service/prometheus-k8s created
serviceaccount/prometheus-k8s created
[root@k8s-master001 manifests]# kubectl get po -n monitoring
NAME READY STATUS RESTARTS AGE
prometheus-k8s-0 3/3 Running 1 94s
prometheus-k8s-1 3/3 Running 1 94s7、安装grafana
root@k8s-master001 manifests]# kubectl apply -f grafana/
secret/grafana-datasources created
configmap/grafana-dashboard-apiserver created
configmap/grafana-dashboard-cluster-total created
configmap/grafana-dashboard-controller-manager created
configmap/grafana-dashboard-k8s-resources-cluster created
configmap/grafana-dashboard-k8s-resources-namespace created
configmap/grafana-dashboard-k8s-resources-node created
configmap/grafana-dashboard-k8s-resources-pod created
configmap/grafana-dashboard-k8s-resources-workload created
configmap/grafana-dashboard-k8s-resources-workloads-namespace created
configmap/grafana-dashboard-kubelet created
configmap/grafana-dashboard-namespace-by-pod created
configmap/grafana-dashboard-namespace-by-workload created
configmap/grafana-dashboard-node-cluster-rsrc-use created
configmap/grafana-dashboard-node-rsrc-use created
configmap/grafana-dashboard-nodes created
configmap/grafana-dashboard-persistentvolumesusage created
configmap/grafana-dashboard-pod-total created
configmap/grafana-dashboard-prometheus-remote-write created
configmap/grafana-dashboard-prometheus created
configmap/grafana-dashboard-proxy created
configmap/grafana-dashboard-scheduler created
configmap/grafana-dashboard-statefulset created
configmap/grafana-dashboard-workload-total created
configmap/grafana-dashboards created
deployment.apps/grafana created
service/grafana created
serviceaccount/grafana created
servicemonitor.monitoring.coreos.com/grafana created
[root@k8s-master001 manifests]# kubectl get po -n monitoring
NAME READY STATUS RESTARTS AGE
grafana-b558fb99f-87spq 1/1 Running 0 3m14s8、安装serviceMonitor
[root@k8s-master001 manifests]# kubectl apply -f serviceMonitor/
servicemonitor.monitoring.coreos.com/prometheus created
servicemonitor.monitoring.coreos.com/kube-apiserver created
servicemonitor.monitoring.coreos.com/coredns created
servicemonitor.monitoring.coreos.com/kube-controller-manager created
servicemonitor.monitoring.coreos.com/kube-scheduler created
servicemonitor.monitoring.coreos.com/kubelet created9、查看全部运行的服务
[root@k8s-master001 manifests]# kubectl get po -n monitoring
NAME READY STATUS RESTARTS AGE
alertmanager-main-0 2/2 Running 0 90m
alertmanager-main-1 2/2 Running 0 40m
alertmanager-main-2 2/2 Running 0 90m
grafana-b558fb99f-87spq 1/1 Running 0 4m56s
kube-state-metrics-85cb9cfd7c-v9c4f 3/3 Running 0 10m
node-exporter-2rvtt 2/2 Running 0 35m
node-exporter-9kwb6 2/2 Running 0 35m
node-exporter-9zlbb 2/2 Running 0 35m
prometheus-adapter-557648f58c-9x446 1/1 Running 0 91m
prometheus-k8s-0 3/3 Running 1 7m49s
prometheus-k8s-1 3/3 Running 1 7m49s
prometheus-operator-74d54b5cfc-xgqg7 2/2 Running 0 95m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/alertmanager-main ClusterIP 10.98.96.94 9093/TCP 91m
service/alertmanager-operated ClusterIP None 9093/TCP,9094/TCP,9094/UDP 91m
service/grafana ClusterIP 10.108.204.33 3000/TCP 6m30s
service/kube-state-metrics ClusterIP None 8443/TCP,9443/TCP 12m
service/node-exporter ClusterIP None 9100/TCP 36m
service/prometheus-adapter ClusterIP 10.98.16.117 443/TCP 93m
service/prometheus-k8s ClusterIP 10.109.119.37 9090/TCP 9m22s
service/prometheus-operated ClusterIP None 9090/TCP 9m24s
service/prometheus-operator ClusterIP None 8443/TCP 97m 10、使用nodeport暴露grafana和prometheus服务,访问UI界面
---
apiVersion: v1
kind: Service
metadata:
name: grafana-svc
namespace: monitoring
spec:
type: NodePort
ports:
- port: 3000
targetPort: 3000
selector:
app: grafana
---
apiVersion: v1
kind: Service
metadata:
name: prometheus-svc
namespace: monitoring
spec:
type: NodePort
ports:
- port: 9090
targetPort: 9090
selector:
prometheus: k8s查看结果
[root@k8s-master001 manifests]# kubectl get svc -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
grafana-svc NodePort 10.99.31.100 3000:30438/TCP 9s
prometheus-svc NodePort 10.102.245.8 9090:32227/TCP 3s 现在可以使用浏览器访问URL NodeIP:30438 NodeIP:32227 : NodeIP为k8s节点IP,当然也可以使用前文介绍的ingress暴露服务
例如:
prometheus: http://10.26.25.20:32227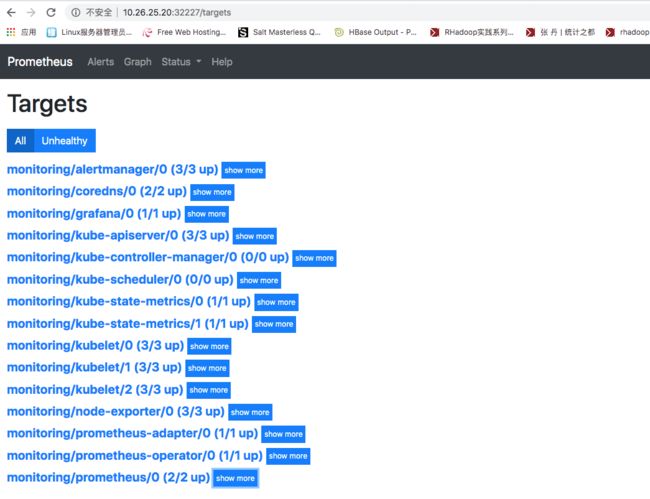
grafana: http://10.26.25.20:30438 默认密码admin/admin,登录后需要修改admin密码
以上,kube-prometheus已经部署完毕,可以用过prometheus查看到监控信息了。
几个小坑
坑位一
1、从prometheus target可以看到,kube-controller-manager和kube-scheduler都没有被监控
解决
这是因为serviceMonitor是根据label去选取svc的,我们可以看到对应的serviceMonitor是选取的namespace范围是kube-system
[root@k8s-master001 manifests]# grep -A2 -B2 selector serviceMonitor/prometheus-serviceMonitorKube*
serviceMonitor/prometheus-serviceMonitorKubeControllerManager.yaml- matchNames:
serviceMonitor/prometheus-serviceMonitorKubeControllerManager.yaml- - kube-system
serviceMonitor/prometheus-serviceMonitorKubeControllerManager.yaml: selector:
serviceMonitor/prometheus-serviceMonitorKubeControllerManager.yaml- matchLabels:
serviceMonitor/prometheus-serviceMonitorKubeControllerManager.yaml- k8s-app: kube-controller-manager
--
serviceMonitor/prometheus-serviceMonitorKubelet.yaml- matchNames:
serviceMonitor/prometheus-serviceMonitorKubelet.yaml- - kube-system
serviceMonitor/prometheus-serviceMonitorKubelet.yaml: selector:
serviceMonitor/prometheus-serviceMonitorKubelet.yaml- matchLabels:
serviceMonitor/prometheus-serviceMonitorKubelet.yaml- k8s-app: kubelet
--
serviceMonitor/prometheus-serviceMonitorKubeScheduler.yaml- matchNames:
serviceMonitor/prometheus-serviceMonitorKubeScheduler.yaml- - kube-system
serviceMonitor/prometheus-serviceMonitorKubeScheduler.yaml: selector:
serviceMonitor/prometheus-serviceMonitorKubeScheduler.yaml- matchLabels:
serviceMonitor/prometheus-serviceMonitorKubeScheduler.yaml- k8s-app: kube-scheduler2、创建kube-controller-manager和kube-scheduler service
k8s v1.19默认使用https,kube-controller-manager端口10257 kube-scheduler端口10259
kube-controller-manager-scheduler.yml
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-controller-manager
labels:
k8s-app: kube-controller-manager
spec:
selector:
component: kube-controller-manager
type: ClusterIP
clusterIP: None
ports:
- name: https-metrics
port: 10257
targetPort: 10257
protocol: TCP
---
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-scheduler
labels:
k8s-app: kube-scheduler
spec:
selector:
component: kube-scheduler
type: ClusterIP
clusterIP: None
ports:
- name: https-metrics
port: 10259
targetPort: 10259
protocol: TCP执行命令
[root@k8s-master001 manifests]# kubectl apply -f kube-controller-manager-scheduler.yml
[root@k8s-master001 manifests]# kubectl get svc -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-controller-manager ClusterIP None 10257/TCP 37m
kube-scheduler ClusterIP None 10259/TCP 37m
3、创建kube-controller-manager和kube-scheduler endpoint
注意:addresses改成集群实际的IP
kube-ep.yml
apiVersion: v1
kind: Endpoints
metadata:
labels:
k8s-app: kube-controller-manager
name: kube-controller-manager
namespace: kube-system
subsets:
- addresses:
- ip: 10.26.25.20
- ip: 10.26.25.21
- ip: 10.26.25.22
ports:
- name: https-metrics
port: 10257
protocol: TCP
---
apiVersion: v1
kind: Endpoints
metadata:
labels:
k8s-app: kube-scheduler
name: kube-scheduler
namespace: kube-system
subsets:
- addresses:
- ip: 10.26.25.20
- ip: 10.26.25.21
- ip: 10.26.25.22
ports:
- name: https-metrics
port: 10259
protocol: TCP[root@k8s-master001 manifests]# kubectl apply -f kube-ep.yml
endpoints/kube-controller-manager created
endpoints/kube-scheduler created
[root@k8s-master001 manifests]# kubectl get ep -n kube-system
NAME ENDPOINTS AGE
kube-controller-manager 10.26.25.20:10257,10.26.25.21:10257,10.26.25.22:10257 16m
kube-scheduler 10.26.25.20:10259,10.26.25.21:10259,10.26.25.22:10259 16m现在看下页面上prometheus target,已经能看到kube-controller-manager和kube-scheduler被监控了
坑位二
1、默认清理下,kube-controller-manager和kube-scheduler绑定IP为127.0.0.1,如果需要监控这两个服务,需要修改kube-controller-manager和kube-scheduler配置,让其绑定到0.0.0.0
2、配置文件所在目录/etc/kubernetes/manifests
修改kube-controller-manager.yaml中--bind-address=0.0.0.0
修改kube-scheduler.yaml中--bind-address=0.0.0.0
3、重启kubelet:systemctl restart kubelet
4、查看是否生效,返回200即为成功
[root@k8s-master002 manifests]# curl -I -k https://10.26.25.20:10257/healthz
HTTP/1.1 200 OK
Cache-Control: no-cache, private
Content-Type: text/plain; charset=utf-8
X-Content-Type-Options: nosniff
Date: Tue, 15 Sep 2020 06:19:32 GMT
Content-Length: 2
[root@k8s-master002 manifests]# curl -I -k https://10.26.25.20:10259/healthz
HTTP/1.1 200 OK
Cache-Control: no-cache, private
Content-Type: text/plain; charset=utf-8
X-Content-Type-Options: nosniff
Date: Tue, 15 Sep 2020 06:19:36 GMT
Content-Length: 2最后
kube-prometheus配置很多,这里只是做了最基础的设置。更多需求请自行查看官方文档
注:文中图片来源于网络,如有侵权,请联系我及时删除。