CDH新增计算节点,并对新增的计算节点,添加服务角色的详细具体步骤
前言
最近发现,公司的的大数据环境,空间有不足的情况,集群的计算能力也下降, 此时需要对将大数据的集群环境进行扩容 增加计算节点。
操作步骤
集群示意图:

准备好linux环境
配置hadoop账号,ssh免密,关掉防火墙,磁盘挂载
1:创建hadoop账号
useradd hadoop2:ssh无密码登陆
su hadoop
ssh-keygen -t rsa
#复制到所有datanode,并测试ssh登陆
cp id_rsa.pub authorized_key3:配置hadoop
把原先的/usr/local/hadoop复制到/home/hadoop下,并修改配置文件中hadoop_home相关的地址。
4:修改文件权限
修改dfs.name.dir,dfs.data.dir,mapred.system.dir,mapred.local.dir等相关目录的权限。
chown -R hadoop:hadoop [dir]5:修改hdfs权限
hadoop dfs -chown -R hadoop:hadoop /6:配置系统时间chrony时间同步服务器
root用户执行命令,安装chrony:
yum install -y chrony*
echo "server 192.168.4.11 iburst" >> /etc/chrony.conf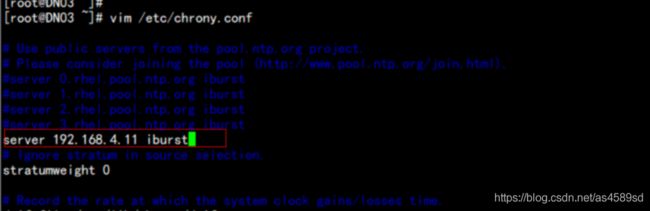
启动chrony.service
/bin/systemctl restart chronyd.service
/bin/systemctl enable chronyd.service
chronyc sources -v 
同步到bios 时间,root用户执行命令
hwclock --localtime -w 
关闭firewalld iptables 和禁用selinux,关闭iptables
systemctl stop firewalld.service
systemctl disable firewalld.service
firewall-cmd --state关闭iptables
iptables -F
systemctl stop iptables.service
service iptables save 禁用 selinux
sed -i '/SELINUX/s/enforcing/disabled/' /etc/selinux/config
setenforce 0
getenforce 0
sestatus重启机器
reboot 修改文件系统的最大连接数,以root用户执行:
vim /etc/security/limits.conf
* soft nofile 32728
* hard nofile 1029345
* soft nproc unlimited
* hard nproc unlimited
* soft memlock unlimited
* hard memlock unlimited 配置新增节点服务器的无密钥认证登录,做root用户无密钥认证
ssh-keygen ---一直敲回车到最后
cat id_rsa.pub >> authorized_keys 将所有节点的公钥导入authorized_keys 分发到 所有的 机器的.ssh/ 下面
chmod 600 .ssh/authorized_keys然后进行无密钥登录认证测试!
准备cm包,增加节点,及配置环境
安装CDH5.12.0 组建所依赖的包
yum -y install chkconfig python bind-utils psmisc libxslt zlib sqlite cyrus-sasl-plain cyrus-sasl-gssapi fuse fuse-libs redhat-lsb创建CM 的安装目录,root 用户执行命名:
mkdir /opt/cloudera-manager
wget http://archive.cloudera.com/cm5/cm/5/cloudera-manager-centos7-cm5.12.0_x86_64.tar.gz解压CM包到/opt/cloudera-manager,以root用户执行命令:
tar -zxvf cloudera-manager-centos7-cm5.12.0_x86_64.tar.gz -C /opt/cloudera-manager修改agent 的配置文件config.ini
以root用户执行命令:
cd /opt/cloudera-manager/cm-5.12.0/etc/cloudera-scm-agent
vim config.ini
server_host=NN01.sge.com.cn创建cloudera-scm 用户用作安装
useradd --system --home=/opt/cloudera-manager/cm-5.12.0/run/cloudera-scm-server --no-create-home --shell=/bin/false --comment "Cloudera SCM User" cloudera-scm提升cloudera-scm 的权限
vim /etc/sudoers在root 权限下面 增加 一行:
cloudera-scm ALL=(ALL) ALL新建新增节点的目录
以root用户执行下面的命令:
mkdir -p /opt/cloudera/parcels
chown -R cloudera-scm:cloudera-scm /opt/cloudera/parcels/新建目录:
mkdir -p /var/lib/cloudera-scm-server
mkdir -p /var/lib/cloudera-scm-agent
chown -R cloudera-scm:cloudera-scm /var/lib/cloudera-scm-server/
chown -R cloudera-scm:cloudera-scm /var/lib/cloudera-scm-agent/启动新增DN03的agent端
启动CM-server的agent 端
cd /opt/cloudera-manager/cm-5.12.0/etc/init.d
./cloudera-scm-agent start 
以root 用户执行命令
echo "10" > /proc/sys/vm/swappiness
echo never > /sys/kernel/mm/transparent_hugepage/defrag
echo never > /sys/kernel/mm/transparent_hugepage/enabled
vim /etc/rc.local
若启动agent失败,则尝试以下命令:
ps -ef | grep supervisord | xargs kill -9
sudo service cloudera-scm-agent restart
登陆cm,选择主机->Parcel
登陆cm(如:http://192.168.16.32:8010/pages/viewpage.action?pageId=16094086)
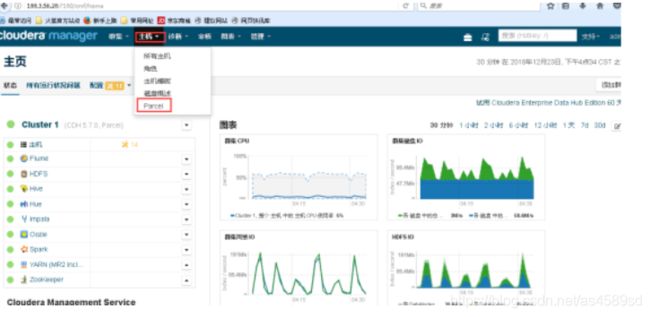
点击检查新Parcel

选择主机加入集群

对机器进行分配,解压,激活

检查主机正确性

向集群添加新主机

重新部署客户端

查看主机添加成功

对添加的新主机添加角色
在Cluster1中选择“添加服务”

在“添加服务至Cluster1”,选择服务类型:
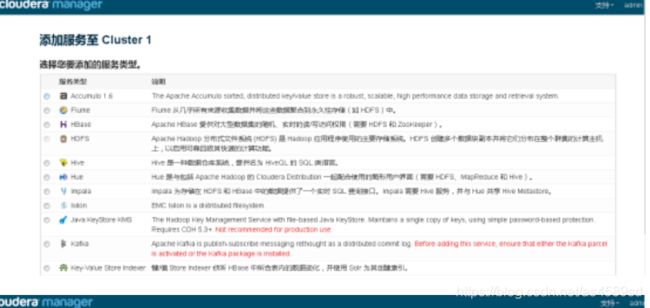
自定义角色分配

同理,添加yarn

为impala角色配置目录

角色成功加入

添加节点完成
计算节点测试
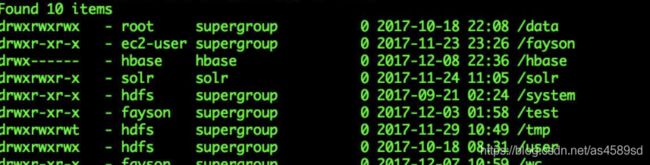
1.HDFS命令测试
[DNS6@fleapx ~]$ hadoop fs -ls /
2.HBase命令测试
[DNS6@fleapx ~]$ hbase shell

3.Hive命令测试
[DNS6@fleapx ~]$ hive

4.hadoop命令向集群提交作业
[DNS6@fleapx ~]$ hadoop jar /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar pi 5 5
友情链接:https://blog.51cto.com/flyfish225/2118098